 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Driven Cloth-Agnostic Feature Learning for Cloth-Changing Person Re-Identification
Jun 13, 2024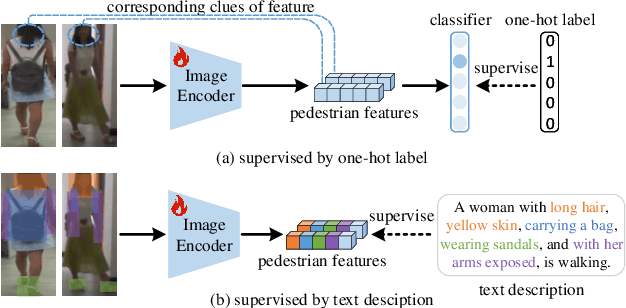

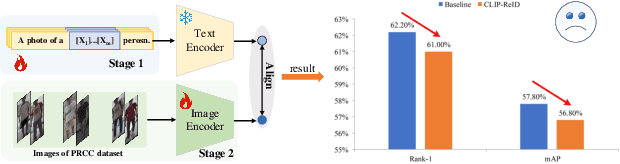
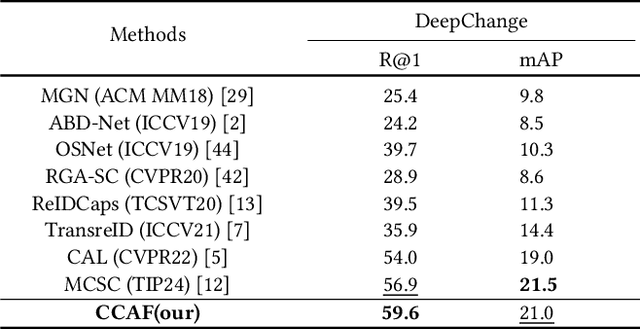
Contrastive Language-Image Pre-Training (CLIP) has shown impressive performance in short-term Person Re-Identification (ReID) due to its ability to extract high-level semantic features of pedestrians, yet its direct application to Cloth-Changing Person Re-Identification (CC-ReID) faces challenges due to CLIP's image encoder overly focusing on clothes clues. To address this, we propose a novel framework called CLIP-Driven Cloth-Agnostic Feature Learning (CCAF) for CC-ReID. Accordingly, two modules were custom-designed: the Invariant Feature Prompting (IFP) and the Clothes Feature Minimization (CFM). These modules guide the model to extract cloth-agnostic features positively and attenuate clothes-related features negatively. Specifically, IFP is designed to extract fine-grained semantic features unrelated to clothes from the raw image, guided by the cloth-agnostic text prompts. This module first covers the clothes in the raw image at the pixel level to obtain the shielding image and then utilizes CLIP's knowledge to generate cloth-agnostic text prompts. Subsequently, it aligns the raw image-text and the raw image-shielding image in the feature space, emphasizing discriminative clues related to identity but unrelated to clothes. Furthermore, CFM is designed to examine and weaken the image encoder's ability to extract clothes features. It first generates text prompts corresponding to clothes pixels. Then, guided by these clothes text prompts, it iteratively examines and disentangles clothes features from pedestrian features, ultimately retaining inherent discriminative features. Extensive experiments have demonstrated the effectiveness of the proposed CCAF, achieving new state-of-the-art performance on several popular CC-ReID benchmarks without any additional inference time.