 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
Dec 14, 2025
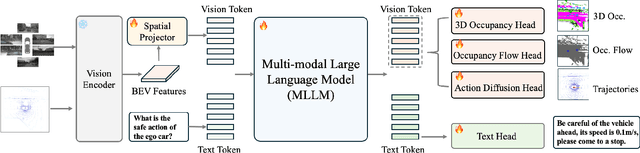
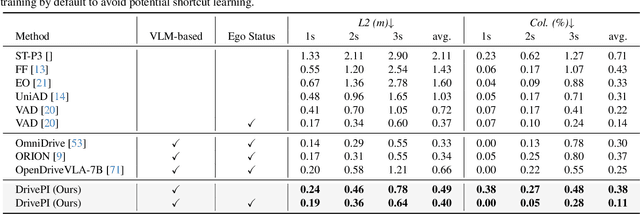
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI
ILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement
Apr 03, 2025



We present ILLUME+ that leverages dual visual tokenization and a diffusion decoder to improve both deep semantic understanding and high-fidelity image generation. Existing unified models have struggled to simultaneously handle the three fundamental capabilities in a unified model: understanding, generation, and editing. Models like Chameleon and EMU3 utilize VQGAN for image discretization, due to the lack of deep semantic interaction, they lag behind specialist models like LLaVA in visual understanding tasks. To mitigate this, LaViT and ILLUME employ semantic encoders for tokenization, but they struggle with image editing due to poor texture preservation. Meanwhile, Janus series decouples the input and output image representation, limiting their abilities to seamlessly handle interleaved image-text understanding and generation. In contrast, ILLUME+ introduces a unified dual visual tokenizer, DualViTok, which preserves both fine-grained textures and text-aligned semantics while enabling a coarse-to-fine image representation strategy for multimodal understanding and generation. Additionally, we employ a diffusion model as the image detokenizer for enhanced generation quality and efficient super-resolution. ILLUME+ follows a continuous-input, discrete-output scheme within the unified MLLM and adopts a progressive training procedure that supports dynamic resolution across the vision tokenizer, MLLM, and diffusion decoder. This design allows for flexible and efficient context-aware image editing and generation across diverse tasks. ILLUME+ (3B) exhibits competitive performance against existing unified MLLMs and specialized models across multimodal understanding, generation, and editing benchmarks. With its strong performance, ILLUME+ provides a scalable and versatile foundation for future multimodal applications. Project Page: https://illume-unified-mllm.github.io/.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
Dec 09, 2024In this paper, we introduce ILLUME, a unified multimodal large language model (MLLM) that seamlessly integrates multimodal understanding and generation capabilities within a single large language model through a unified next-token prediction formulation. To address the large dataset size typically required for image-text alignment, we propose to enhance data efficiency through the design of a vision tokenizer that incorporates semantic information and a progressive multi-stage training procedure. This approach reduces the dataset size to just 15M for pretraining -- over four times fewer than what is typically needed -- while achieving competitive or even superior performance with existing unified MLLMs, such as Janus. Additionally, to promote synergistic enhancement between understanding and generation capabilities, which is under-explored in previous works, we introduce a novel self-enhancing multimodal alignment scheme. This scheme supervises the MLLM to self-assess the consistency between text descriptions and self-generated images, facilitating the model to interpret images more accurately and avoid unrealistic and incorrect predictions caused by misalignment in image generation. Based on extensive experiments, our proposed ILLUME stands out and competes with state-of-the-art unified MLLMs and specialized models across various benchmarks for multimodal understanding, generation, and editing.
Efficient Multi-modal Large Language Models via Visual Token Grouping
Nov 26, 2024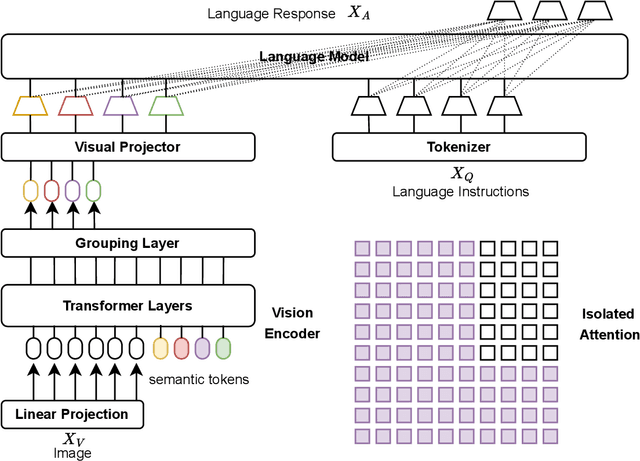
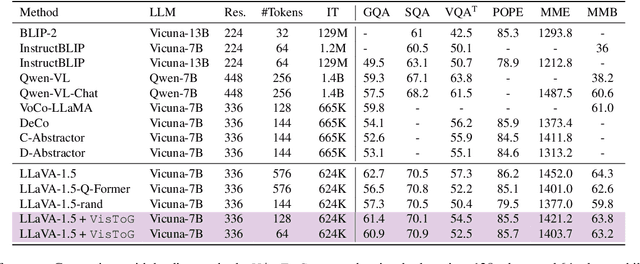
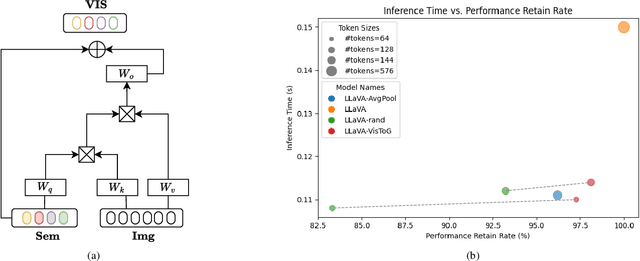
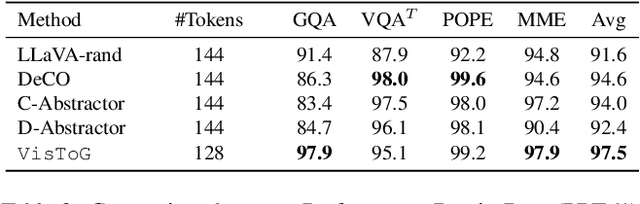
The development of Multi-modal Large Language Models (MLLMs) enhances Large Language Models (LLMs) with the ability to perceive data formats beyond text, significantly advancing a range of downstream applications, such as visual question answering and image captioning. However, the substantial computational costs associated with processing high-resolution images and videos pose a barrier to their broader adoption. To address this challenge, compressing vision tokens in MLLMs has emerged as a promising approach to reduce inference costs. While existing methods conduct token reduction in the feature alignment phase. In this paper, we introduce VisToG, a novel grouping mechanism that leverages the capabilities of pre-trained vision encoders to group similar image segments without the need for segmentation masks. Specifically, we concatenate semantic tokens to represent image semantic segments after the linear projection layer before feeding into the vision encoder. Besides, with the isolated attention we adopt, VisToG can identify and eliminate redundant visual tokens utilizing the prior knowledge in the pre-trained vision encoder, which effectively reduces computational demands. Extensive experiments demonstrate the effectiveness of VisToG, maintaining 98.1% of the original performance while achieving a reduction of over 27\% inference time.
AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning
Nov 18, 2024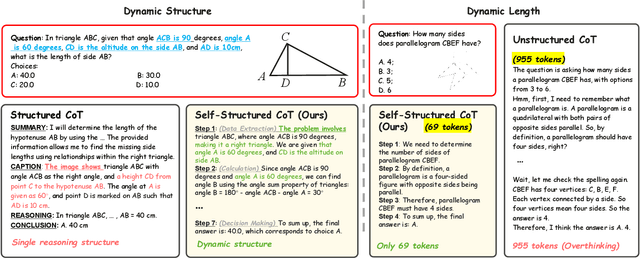
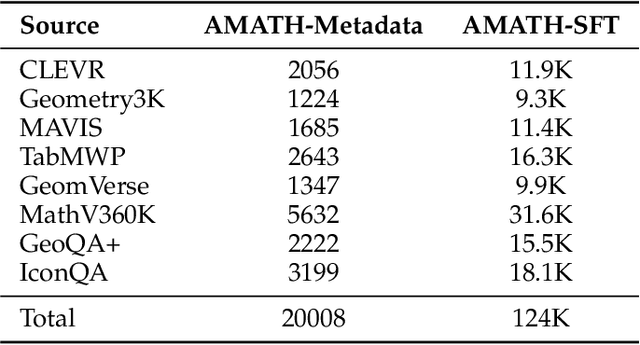
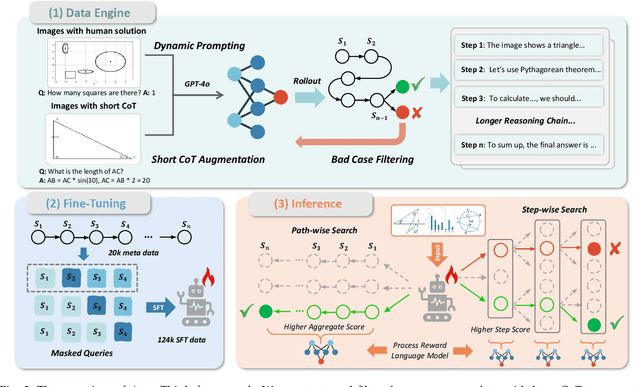
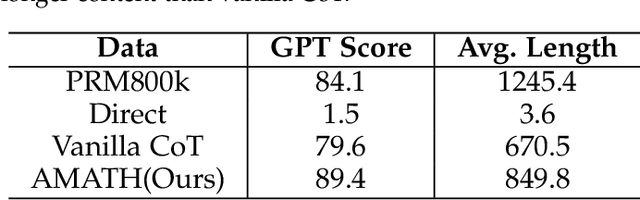
In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of ``slow thinking" into multimodal large language models (MLLMs). Contrary to existing methods that rely on direct or fast thinking, our key idea is to construct long chains of thought (CoT) consisting of atomic actions in a step-by-step manner, guiding MLLMs to perform complex reasoning. To this end, we design a novel AtomThink framework composed of three key modules: (i) a CoT annotation engine that automatically generates high-quality CoT annotations to address the lack of high-quality visual mathematical data; (ii) an atomic step fine-tuning strategy that jointly optimizes an MLLM and a policy reward model (PRM) for step-wise reasoning; and (iii) four different search strategies that can be applied with the PRM to complete reasoning. Additionally, we propose AtomMATH, a large-scale multimodal dataset of long CoTs, and an atomic capability evaluation metric for mathematical tasks. Extensive experimental results show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving approximately 50\% relative accuracy gains on MathVista and 120\% on MathVerse. To support the advancement of multimodal slow-thinking models, we will make our code and dataset publicly available on https://github.com/Quinn777/AtomThink.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024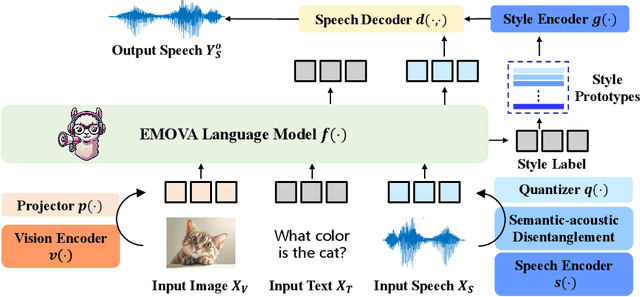
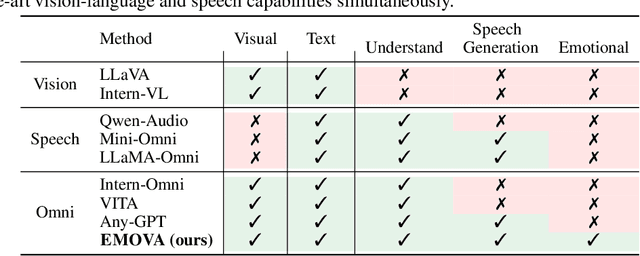
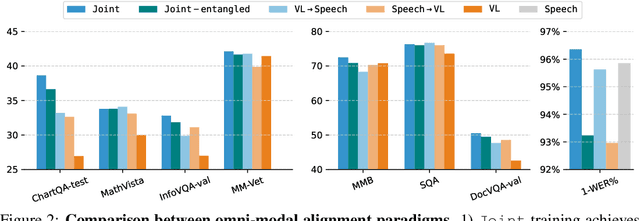

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
HiRes-LLaVA: Restoring Fragmentation Input in High-Resolution Large Vision-Language Models
Jul 11, 2024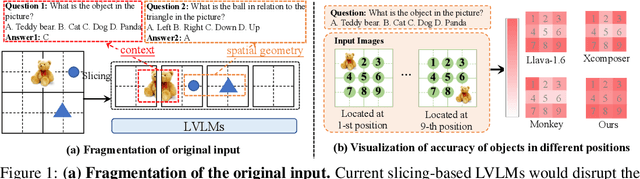
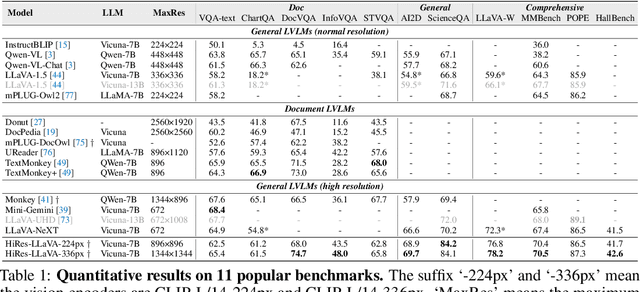
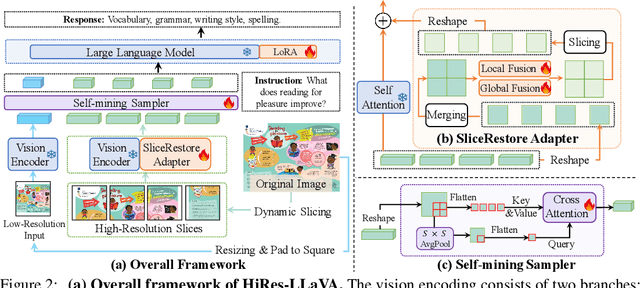

High-resolution inputs enable Large Vision-Language Models (LVLMs) to discern finer visual details, enhancing their comprehension capabilities. To reduce the training and computation costs caused by high-resolution input, one promising direction is to use sliding windows to slice the input into uniform patches, each matching the input size of the well-trained vision encoder. Although efficient, this slicing strategy leads to the fragmentation of original input, i.e., the continuity of contextual information and spatial geometry is lost across patches, adversely affecting performance in cross-patch context perception and position-specific tasks. To overcome these shortcomings, we introduce HiRes-LLaVA, a novel framework designed to efficiently process any size of high-resolution input without altering the original contextual and geometric information. HiRes-LLaVA comprises two innovative components: (i) a SliceRestore adapter that reconstructs sliced patches into their original form, efficiently extracting both global and local features via down-up-sampling and convolution layers, and (ii) a Self-Mining Sampler to compresses the vision tokens based on themselves, preserving the original context and positional information while reducing training overhead. To assess the ability of handling context fragmentation, we construct a new benchmark, EntityGrid-QA, consisting of edge-related and position-related tasks. Our comprehensive experiments demonstrate the superiority of HiRes-LLaVA on both existing public benchmarks and on EntityGrid-QA, particularly on document-oriented tasks, establishing new standards for handling high-resolution inputs.
LayerDiff: Exploring Text-guided Multi-layered Composable Image Synthesis via Layer-Collaborative Diffusion Model
Mar 18, 2024Despite the success of generating high-quality images given any text prompts by diffusion-based generative models, prior works directly generate the entire images, but cannot provide object-wise manipulation capability. To support wider real applications like professional graphic design and digital artistry, images are frequently created and manipulated in multiple layers to offer greater flexibility and control. Therefore in this paper, we propose a layer-collaborative diffusion model, named LayerDiff, specifically designed for text-guided, multi-layered, composable image synthesis. The composable image consists of a background layer, a set of foreground layers, and associated mask layers for each foreground element. To enable this, LayerDiff introduces a layer-based generation paradigm incorporating multiple layer-collaborative attention modules to capture inter-layer patterns. Specifically, an inter-layer attention module is designed to encourage information exchange and learning between layers, while a text-guided intra-layer attention module incorporates layer-specific prompts to direct the specific-content generation for each layer. A layer-specific prompt-enhanced module better captures detailed textual cues from the global prompt. Additionally, a self-mask guidance sampling strategy further unleashes the model's ability to generate multi-layered images. We also present a pipeline that integrates existing perceptual and generative models to produce a large dataset of high-quality, text-prompted, multi-layered images. Extensive experiments demonstrate that our LayerDiff model can generate high-quality multi-layered images with performance comparable to conventional whole-image generation methods. Moreover, LayerDiff enables a broader range of controllable generative applications, including layer-specific image editing and style transfer.
GrowCLIP: Data-aware Automatic Model Growing for Large-scale Contrastive Language-Image Pre-training
Aug 22, 2023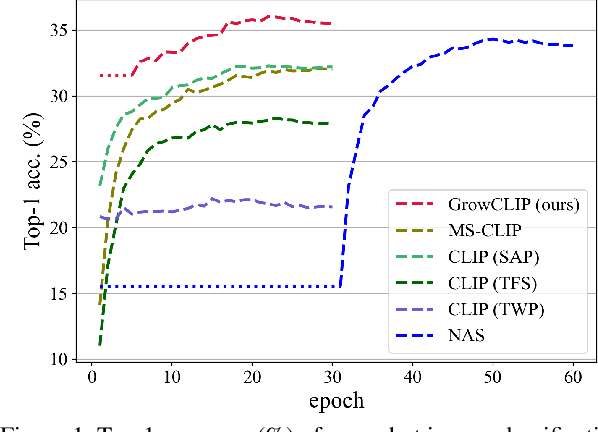

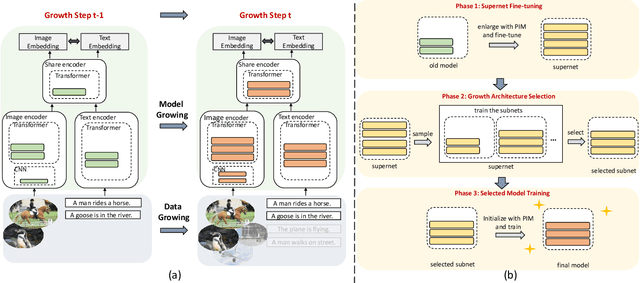

Cross-modal pre-training has shown impressive performance on a wide range of downstream tasks, benefiting from massive image-text pairs collected from the Internet. In practice, online data are growing constantly, highlighting the importance of the ability of pre-trained model to learn from data that is continuously growing. Existing works on cross-modal pre-training mainly focus on training a network with fixed architecture. However, it is impractical to limit the model capacity when considering the continuously growing nature of pre-training data in real-world applications. On the other hand, it is important to utilize the knowledge in the current model to obtain efficient training and better performance. To address the above issues, in this paper, we propose GrowCLIP, a data-driven automatic model growing algorithm for contrastive language-image pre-training with continuous image-text pairs as input. Specially, we adopt a dynamic growth space and seek out the optimal architecture at each growth step to adapt to online learning scenarios. And the shared encoder is proposed in our growth space to enhance the degree of cross-modal fusion. Besides, we explore the effect of growth in different dimensions, which could provide future references for the design of cross-modal model architecture. Finally, we employ parameter inheriting with momentum (PIM) to maintain the previous knowledge and address the issue of the local minimum dilemma. Compared with the existing methods, GrowCLIP improves 2.3% average top-1 accuracy on zero-shot image classification of 9 downstream tasks. As for zero-shot image retrieval, GrowCLIP can improve 1.2% for top-1 image-to-text recall on Flickr30K dataset.