 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysWorld: From Real Videos to World Models of Deformable Objects via Physics-Aware Demonstration Synthesis
Oct 24, 2025Interactive world models that simulate object dynamics are crucial for robotics, VR, and AR. However, it remains a significant challenge to learn physics-consistent dynamics models from limited real-world video data, especially for deformable objects with spatially-varying physical properties. To overcome the challenge of data scarcity, we propose PhysWorld, a novel framework that utilizes a simulator to synthesize physically plausible and diverse demonstrations to learn efficient world models. Specifically, we first construct a physics-consistent digital twin within MPM simulator via constitutive model selection and global-to-local optimization of physical properties. Subsequently, we apply part-aware perturbations to the physical properties and generate various motion patterns for the digital twin, synthesizing extensive and diverse demonstrations. Finally, using these demonstrations, we train a lightweight GNN-based world model that is embedded with physical properties. The real video can be used to further refine the physical properties. PhysWorld achieves accurate and fast future predictions for various deformable objects, and also generalizes well to novel interactions. Experiments show that PhysWorld has competitive performance while enabling inference speeds 47 times faster than the recent state-of-the-art method, i.e., PhysTwin.
Tool-R1: Sample-Efficient Reinforcement Learning for Agentic Tool Use
Sep 16, 2025Large language models (LLMs) have demonstrated strong capabilities in language understanding and reasoning, yet they remain limited when tackling real-world tasks that require up-to-date knowledge, precise operations, or specialized tool use. To address this, we propose Tool-R1, a reinforcement learning framework that enables LLMs to perform general, compositional, and multi-step tool use by generating executable Python code. Tool-R1 supports integration of user-defined tools and standard libraries, with variable sharing across steps to construct coherent workflows. An outcome-based reward function, combining LLM-based answer judgment and code execution success, guides policy optimization. To improve training efficiency, we maintain a dynamic sample queue to cache and reuse high-quality trajectories, reducing the overhead of costly online sampling. Experiments on the GAIA benchmark show that Tool-R1 substantially improves both accuracy and robustness, achieving about 10\% gain over strong baselines, with larger improvements on complex multi-step tasks. These results highlight the potential of Tool-R1 for enabling reliable and efficient tool-augmented reasoning in real-world applications. Our code will be available at https://github.com/YBYBZhang/Tool-R1.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025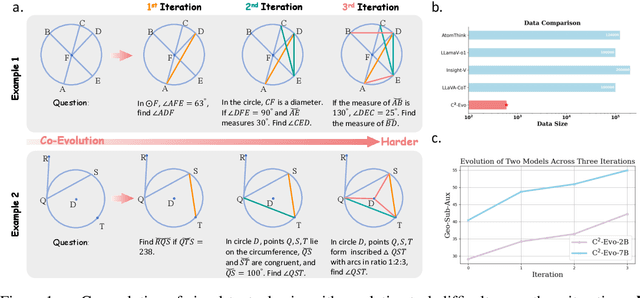

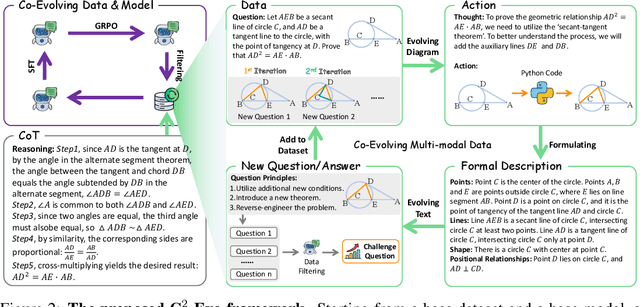
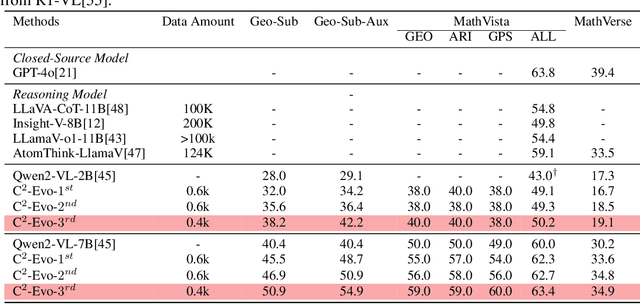
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
CoherenDream: Boosting Holistic Text Coherence in 3D Generation via Multimodal Large Language Models Feedback
Apr 28, 2025



Score Distillation Sampling (SDS) has achieved remarkable success in text-to-3D content generation. However, SDS-based methods struggle to maintain semantic fidelity for user prompts, particularly when involving multiple objects with intricate interactions. While existing approaches often address 3D consistency through multiview diffusion model fine-tuning on 3D datasets, this strategy inadvertently exacerbates text-3D alignment degradation. The limitation stems from SDS's inherent accumulation of view-independent biases during optimization, which progressively diverges from the ideal text alignment direction. To alleviate this limitation, we propose a novel SDS objective, dubbed as Textual Coherent Score Distillation (TCSD), which integrates alignment feedback from multimodal large language models (MLLMs). Our TCSD leverages cross-modal understanding capabilities of MLLMs to assess and guide the text-3D correspondence during the optimization. We further develop 3DLLaVA-CRITIC - a fine-tuned MLLM specialized for evaluating multiview text alignment in 3D generations. Additionally, we introduce an LLM-layout initialization that significantly accelerates optimization convergence through semantic-aware spatial configuration. Comprehensive evaluations demonstrate that our framework, CoherenDream, establishes state-of-the-art performance in text-aligned 3D generation across multiple benchmarks, including T$^3$Bench and TIFA subset. Qualitative results showcase the superior performance of CoherenDream in preserving textual consistency and semantic interactions. As the first study to incorporate MLLMs into SDS optimization, we also conduct extensive ablation studies to explore optimal MLLM adaptations for 3D generation tasks.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
UniGS: Unified Language-Image-3D Pretraining with Gaussian Splatting
Feb 25, 2025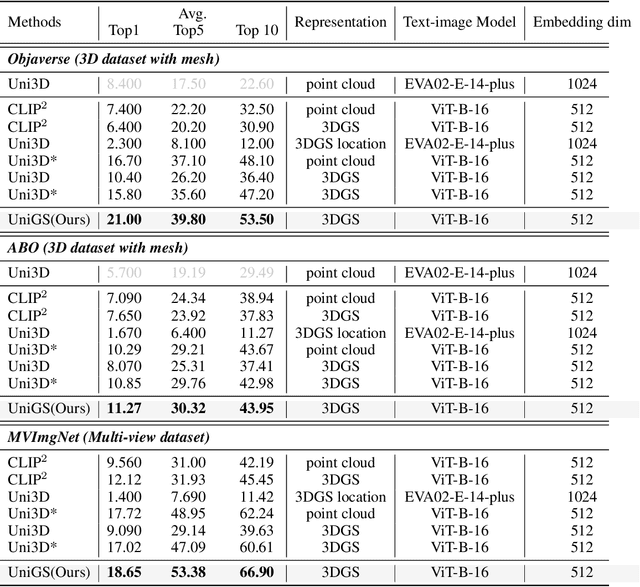

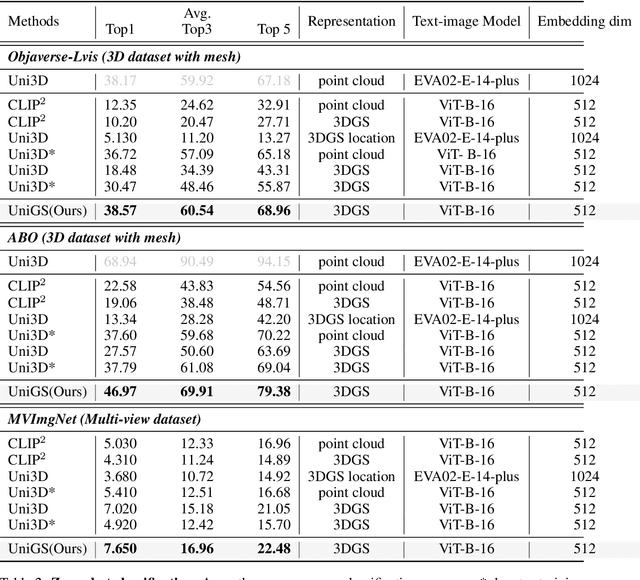

Recent advancements in multi-modal 3D pre-training methods have shown promising efficacy in learning joint representations of text, images, and point clouds. However, adopting point clouds as 3D representation fails to fully capture the intricacies of the 3D world and exhibits a noticeable gap between the discrete points and the dense 2D pixels of images. To tackle this issue, we propose UniGS, integrating 3D Gaussian Splatting (3DGS) into multi-modal pre-training to enhance the 3D representation. We first rely on the 3DGS representation to model the 3D world as a collection of 3D Gaussians with color and opacity, incorporating all the information of the 3D scene while establishing a strong connection with 2D images. Then, to achieve Language-Image-3D pertaining, UniGS starts with a pre-trained vision-language model to establish a shared visual and textual space through extensive real-world image-text pairs. Subsequently, UniGS employs a 3D encoder to align the optimized 3DGS with the Language-Image representations to learn unified multi-modal representations. To facilitate the extraction of global explicit 3D features by the 3D encoder and achieve better cross-modal alignment, we additionally introduce a novel Gaussian-Aware Guidance module that guides the learning of fine-grained representations of the 3D domain. Through extensive experiments across the Objaverse, ABO, MVImgNet and SUN RGBD datasets with zero-shot classification, text-driven retrieval and open-world understanding tasks, we demonstrate the effectiveness of UniGS in learning a more general and stronger aligned multi-modal representation. Specifically, UniGS achieves leading results across different 3D tasks with remarkable improvements over previous SOTA, Uni3D, including on zero-shot classification (+9.36%), text-driven retrieval (+4.3%) and open-world understanding (+7.92%).
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Feb 18, 2025Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
FramePainter: Endowing Interactive Image Editing with Video Diffusion Priors
Jan 14, 2025



Interactive image editing allows users to modify images through visual interaction operations such as drawing, clicking, and dragging. Existing methods construct such supervision signals from videos, as they capture how objects change with various physical interactions. However, these models are usually built upon text-to-image diffusion models, so necessitate (i) massive training samples and (ii) an additional reference encoder to learn real-world dynamics and visual consistency. In this paper, we reformulate this task as an image-to-video generation problem, so that inherit powerful video diffusion priors to reduce training costs and ensure temporal consistency. Specifically, we introduce FramePainter as an efficient instantiation of this formulation. Initialized with Stable Video Diffusion, it only uses a lightweight sparse control encoder to inject editing signals. Considering the limitations of temporal attention in handling large motion between two frames, we further propose matching attention to enlarge the receptive field while encouraging dense correspondence between edited and source image tokens. We highlight the effectiveness and efficiency of FramePainter across various of editing signals: it domainantly outperforms previous state-of-the-art methods with far less training data, achieving highly seamless and coherent editing of images, \eg, automatically adjust the reflection of the cup. Moreover, FramePainter also exhibits exceptional generalization in scenarios not present in real-world videos, \eg, transform the clownfish into shark-like shape. Our code will be available at https://github.com/YBYBZhang/FramePainter.
AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning
Nov 18, 2024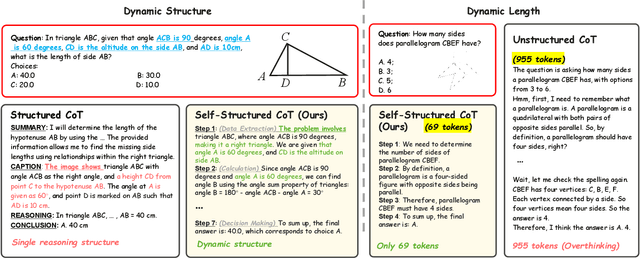
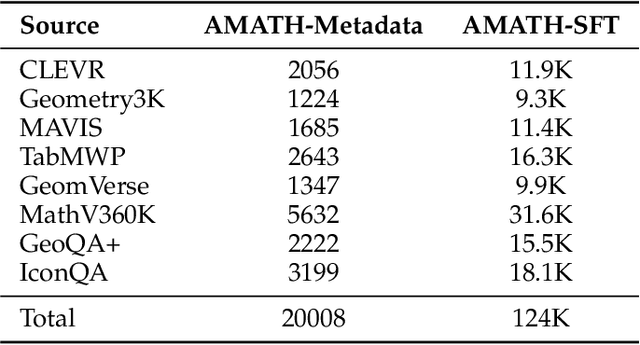
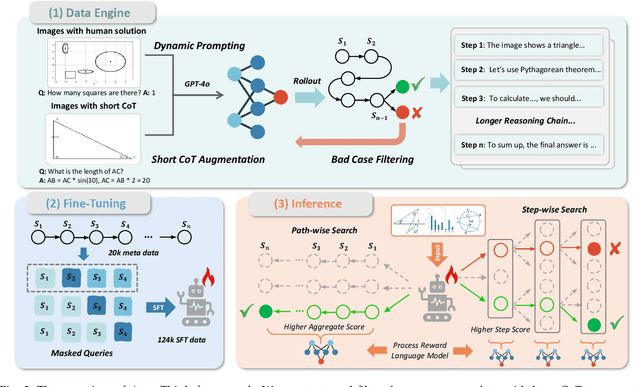
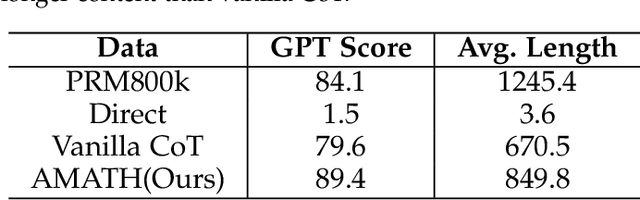
In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of ``slow thinking" into multimodal large language models (MLLMs). Contrary to existing methods that rely on direct or fast thinking, our key idea is to construct long chains of thought (CoT) consisting of atomic actions in a step-by-step manner, guiding MLLMs to perform complex reasoning. To this end, we design a novel AtomThink framework composed of three key modules: (i) a CoT annotation engine that automatically generates high-quality CoT annotations to address the lack of high-quality visual mathematical data; (ii) an atomic step fine-tuning strategy that jointly optimizes an MLLM and a policy reward model (PRM) for step-wise reasoning; and (iii) four different search strategies that can be applied with the PRM to complete reasoning. Additionally, we propose AtomMATH, a large-scale multimodal dataset of long CoTs, and an atomic capability evaluation metric for mathematical tasks. Extensive experimental results show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving approximately 50\% relative accuracy gains on MathVista and 120\% on MathVerse. To support the advancement of multimodal slow-thinking models, we will make our code and dataset publicly available on https://github.com/Quinn777/AtomThink.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024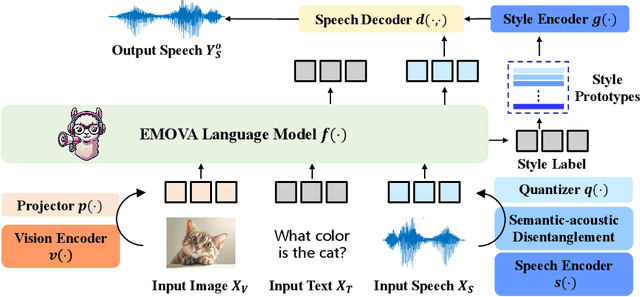
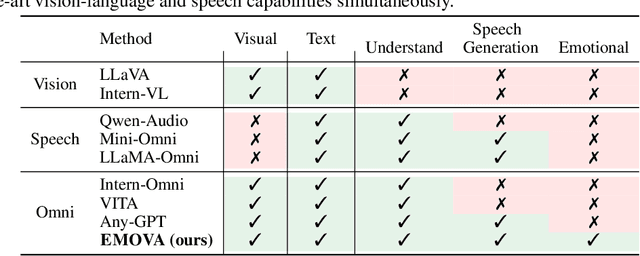
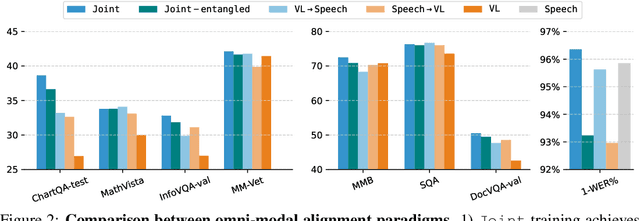

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.