 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoPO: Incorporating Motion Prior for Occluded Human Mesh Recovery
May 11, 2026Although recent studies have made remarkable progress in human mesh recovery, they still exhibit limited robustness to occlusions and often produce inaccurate poses and severe motion jitter due to the insufficient spatial features for occluded body parts. Inspired by the rapid advancements in human motion prediction, we discover that compared to occluded image features, pose sequence inherently contains reliable motion prior for estimating occluded body parts. In this paper, we incorporate Motion Prior for Occluded human mesh recovery, called MoPO. Our MoPO mainly consists of two components: 1) The motion de-occlusion module, where we propose a spatial-temporal occlusion detector to detect joint visibility, and then we propose a lightweight motion predictor to complete the occluded body parts by predicting the most plausible joint positions based on history poses. 2) The motion-aware fusion and refinement module, which fuses the completed joint sequence with image features to estimate human shape and initial human pose. Moreover, the completed joint sequence is further used to refine the final human pose through inverse kinematics, which provides the occlusion-free motion prior for regressing human poses. Extensive experiments demonstrate that MoPO achieves state-of-the-art performance on both occlusion-specific and standard benchmarks, significantly enhancing the accuracy and temporal consistency of occluded human mesh recovery. Our code and demo can be found in the supplementary material.
Diff-KD: Diffusion-based Knowledge Distillation for Collaborative Perception under Corruptions
Apr 02, 2026Multi-agent collaborative perception enables autonomous systems to overcome individual sensing limits through collective intelligence. However, real-world sensor and communication corruptions severely undermine this advantage. Crucially, existing approaches treat corruptions as static perturbations or passively conform to corrupted inputs, failing to actively recover the underlying clean semantics. To address this limitation, we introduce Diff-KD, a framework that integrates diffusion-based generative refinement into teacher-student knowledge distillation for robust collaborative perception. Diff-KD features two core components: (i) Progressive Knowledge Distillation (PKD), which treats local feature restoration as a conditional diffusion process to recover global semantics from corrupted observations; and (ii) Adaptive Gated Fusion (AGF), which dynamically weights neighbors based on ego reliability during fusion. Evaluated on OPV2V and DAIR-V2X under seven corruption types, Diff-KD achieves state-of-the-art performance in both detection accuracy and calibration robustness.
AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots
Mar 08, 2026Recent advances in Visual-Language-Action (VLA) models have shown promising potential for robotic manipulation tasks. However, real-world robotic tasks often involve long-horizon, multi-step problem-solving and require generalization for continual skill acquisition, extending beyond single actions or skills. These challenges present significant barriers for existing VLA models, which use monolithic action decoders trained on aggregated data, resulting in poor scalability. To address these challenges, we propose AtomicVLA, a unified planning-and-execution framework that jointly generates task-level plans, atomic skill abstractions, and fine-grained actions. AtomicVLA constructs a scalable atomic skill library through a Skill-Guided Mixture-of-Experts (SG-MoE), where each expert specializes in mastering generic yet precise atomic skills. Furthermore, we introduce a flexible routing encoder that automatically assigns dedicated atomic experts to new skills, enabling continual learning. We validate our approach through extensive experiments. In simulation, AtomicVLA outperforms $π_{0}$ by 2.4\% on LIBERO, 10\% on LIBERO-LONG, and outperforms $π_{0}$ and $π_{0.5}$ by 0.22 and 0.25 in average task length on CALVIN. Additionally, our AtomicVLA consistently surpasses baselines by 18.3\% and 21\% in real-world long-horizon tasks and continual learning. These results highlight the effectiveness of atomic skill abstraction and dynamic expert composition for long-horizon and lifelong robotic tasks. The project page is \href{https://zhanglk9.github.io/atomicvla-web/}{here}.
CATNet: Collaborative Alignment and Transformation Network for Cooperative Perception
Mar 05, 2026Cooperative perception significantly enhances scene understanding by integrating complementary information from diverse agents. However, existing research often overlooks critical challenges inherent in real-world multi-source data integration, specifically high temporal latency and multi-source noise. To address these practical limitations, we propose Collaborative Alignment and Transformation Network (CATNet), an adaptive compensation framework that resolves temporal latency and noise interference in multi-agent systems. Our key innovations can be summarized in three aspects. First, we introduce a Spatio-Temporal Recurrent Synchronization (STSync) that aligns asynchronous feature streams via adjacent-frame differential modeling, establishing a temporal-spatially unified representation space. Second, we design a Dual-Branch Wavelet Enhanced Denoiser (WTDen) that suppresses global noise and reconstructs localized feature distortions within aligned representations. Third, we construct an Adaptive Feature Selector (AdpSel) that dynamically focuses on critical perceptual features for robust fusion. Extensive experiments on multiple datasets demonstrate that CATNet consistently outperforms existing methods under complex traffic conditions, proving its superior robustness and adaptability.
DriveCombo: Benchmarking Compositional Traffic Rule Reasoning in Autonomous Driving
Mar 02, 2026Multimodal Large Language Models (MLLMs) are rapidly becoming the intelligence brain of end-to-end autonomous driving systems. A key challenge is to assess whether MLLMs can truly understand and follow complex real-world traffic rules. However, existing benchmarks mainly focus on single-rule scenarios like traffic sign recognition, neglecting the complexity of multi-rule concurrency and conflicts in real driving. Consequently, models perform well on simple tasks but often fail or violate rules in real world complex situations. To bridge this gap, we propose DriveCombo, a text and vision-based benchmark for compositional traffic rule reasoning. Inspired by human drivers' cognitive development, we propose a systematic Five-Level Cognitive Ladder that evaluates reasoning from single-rule understanding to multi-rule integration and conflict resolution, enabling quantitative assessment across cognitive stages. We further propose a Rule2Scene Agent that maps language-based traffic rules to dynamic driving scenes through rule crafting and scene generation, enabling scene-level traffic rule visual reasoning. Evaluations of 14 mainstream MLLMs reveal performance drops as task complexity grows, particularly during rule conflicts. After splitting the dataset and fine-tuning on the training set, we further observe substantial improvements in both traffic rule reasoning and downstream planning capabilities. These results highlight the effectiveness of DriveCombo in advancing compliant and intelligent autonomous driving systems.
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Feb 05, 2026Recent progress in spatial reasoning with Multimodal Large Language Models (MLLMs) increasingly leverages geometric priors from 3D encoders. However, most existing integration strategies remain passive: geometry is exposed as a global stream and fused in an indiscriminate manner, which often induces semantic-geometry misalignment and redundant signals. We propose GeoThinker, a framework that shifts the paradigm from passive fusion to active perception. Instead of feature mixing, GeoThinker enables the model to selectively retrieve geometric evidence conditioned on its internal reasoning demands. GeoThinker achieves this through Spatial-Grounded Fusion applied at carefully selected VLM layers, where semantic visual priors selectively query and integrate task-relevant geometry via frame-strict cross-attention, further calibrated by Importance Gating that biases per-frame attention toward task-relevant structures. Comprehensive evaluation results show that GeoThinker sets a new state-of-the-art in spatial intelligence, achieving a peak score of 72.6 on the VSI-Bench. Furthermore, GeoThinker demonstrates robust generalization and significantly improved spatial perception across complex downstream scenarios, including embodied referring and autonomous driving. Our results indicate that the ability to actively integrate spatial structures is essential for next-generation spatial intelligence. Code can be found at https://github.com/Li-Hao-yuan/GeoThinker.
FairGE: Fairness-Aware Graph Encoding in Incomplete Social Networks
Jan 14, 2026Graph Transformers (GTs) are increasingly applied to social network analysis, yet their deployment is often constrained by fairness concerns. This issue is particularly critical in incomplete social networks, where sensitive attributes are frequently missing due to privacy and ethical restrictions. Existing solutions commonly generate these incomplete attributes, which may introduce additional biases and further compromise user privacy. To address this challenge, FairGE (Fair Graph Encoding) is introduced as a fairness-aware framework for GTs in incomplete social networks. Instead of generating sensitive attributes, FairGE encodes fairness directly through spectral graph theory. By leveraging the principal eigenvector to represent structural information and padding incomplete sensitive attributes with zeros to maintain independence, FairGE ensures fairness without data reconstruction. Theoretical analysis demonstrates that the method suppresses the influence of non-principal spectral components, thereby enhancing fairness. Extensive experiments on seven real-world social network datasets confirm that FairGE achieves at least a 16% improvement in both statistical parity and equality of opportunity compared with state-of-the-art baselines. The source code is shown in https://github.com/LuoRenqiang/FairGE.
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
LiDAR-GS++:Improving LiDAR Gaussian Reconstruction via Diffusion Priors
Nov 15, 2025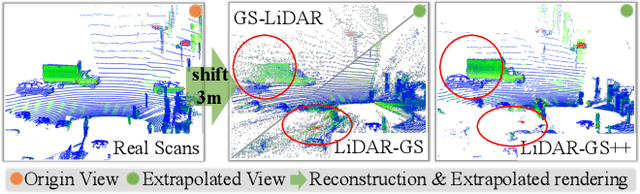
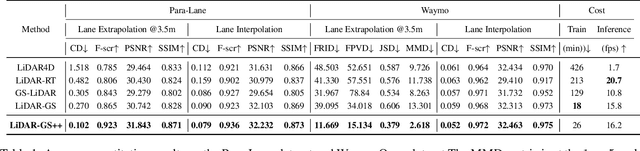
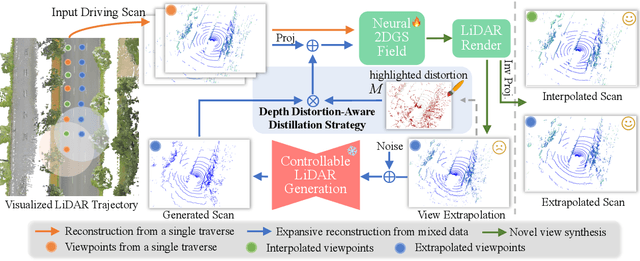
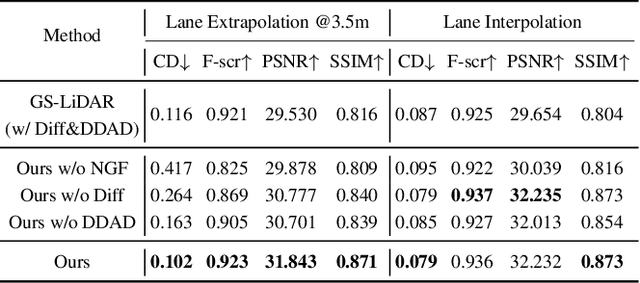
Recent GS-based rendering has made significant progress for LiDAR, surpassing Neural Radiance Fields (NeRF) in both quality and speed. However, these methods exhibit artifacts in extrapolated novel view synthesis due to the incomplete reconstruction from single traversal scans. To address this limitation, we present LiDAR-GS++, a LiDAR Gaussian Splatting reconstruction method enhanced by diffusion priors for real-time and high-fidelity re-simulation on public urban roads. Specifically, we introduce a controllable LiDAR generation model conditioned on coarsely extrapolated rendering to produce extra geometry-consistent scans and employ an effective distillation mechanism for expansive reconstruction. By extending reconstruction to under-fitted regions, our approach ensures global geometric consistency for extrapolative novel views while preserving detailed scene surfaces captured by sensors. Experiments on multiple public datasets demonstrate that LiDAR-GS++ achieves state-of-the-art performance for both interpolated and extrapolated viewpoints, surpassing existing GS and NeRF-based methods.