 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
VariFace: Fair and Diverse Synthetic Dataset Generation for Face Recognition
Dec 09, 2024

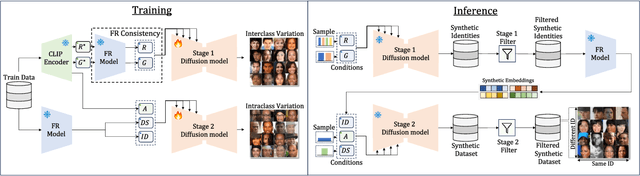

The use of large-scale, web-scraped datasets to train face recognition models has raised significant privacy and bias concerns. Synthetic methods mitigate these concerns and provide scalable and controllable face generation to enable fair and accurate face recognition. However, existing synthetic datasets display limited intraclass and interclass diversity and do not match the face recognition performance obtained using real datasets. Here, we propose VariFace, a two-stage diffusion-based pipeline to create fair and diverse synthetic face datasets to train face recognition models. Specifically, we introduce three methods: Face Recognition Consistency to refine demographic labels, Face Vendi Score Guidance to improve interclass diversity, and Divergence Score Conditioning to balance the identity preservation-intraclass diversity trade-off. When constrained to the same dataset size, VariFace considerably outperforms previous synthetic datasets (0.9200 $\rightarrow$ 0.9405) and achieves comparable performance to face recognition models trained with real data (Real Gap = -0.0065). In an unconstrained setting, VariFace not only consistently achieves better performance compared to previous synthetic methods across dataset sizes but also, for the first time, outperforms the real dataset (CASIA-WebFace) across six evaluation datasets. This sets a new state-of-the-art performance with an average face verification accuracy of 0.9567 (Real Gap = +0.0097) across LFW, CFP-FP, CPLFW, AgeDB, and CALFW datasets and 0.9366 (Real Gap = +0.0380) on the RFW dataset.
CHASE: Learning Convex Hull Adaptive Shift for Skeleton-based Multi-Entity Action Recognition
Oct 09, 2024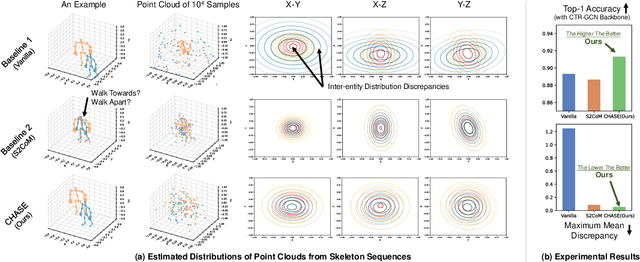
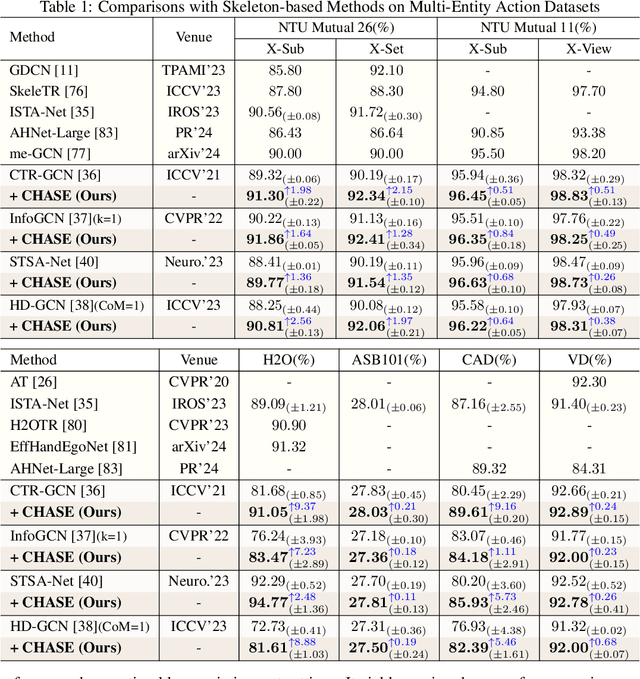
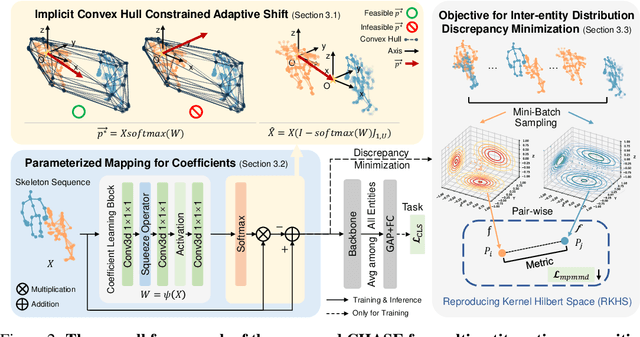
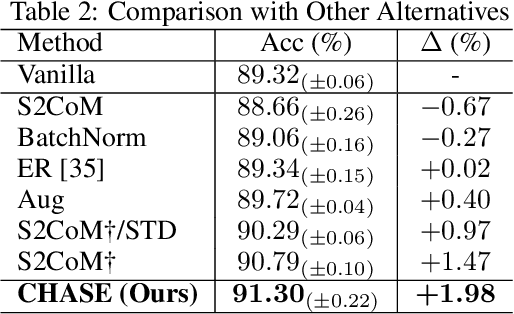
Skeleton-based multi-entity action recognition is a challenging task aiming to identify interactive actions or group activities involving multiple diverse entities. Existing models for individuals often fall short in this task due to the inherent distribution discrepancies among entity skeletons, leading to suboptimal backbone optimization. To this end, we introduce a Convex Hull Adaptive Shift based multi-Entity action recognition method (CHASE), which mitigates inter-entity distribution gaps and unbiases subsequent backbones. Specifically, CHASE comprises a learnable parameterized network and an auxiliary objective. The parameterized network achieves plausible, sample-adaptive repositioning of skeleton sequences through two key components. First, the Implicit Convex Hull Constrained Adaptive Shift ensures that the new origin of the coordinate system is within the skeleton convex hull. Second, the Coefficient Learning Block provides a lightweight parameterization of the mapping from skeleton sequences to their specific coefficients in convex combinations. Moreover, to guide the optimization of this network for discrepancy minimization, we propose the Mini-batch Pair-wise Maximum Mean Discrepancy as the additional objective. CHASE operates as a sample-adaptive normalization method to mitigate inter-entity distribution discrepancies, thereby reducing data bias and improving the subsequent classifier's multi-entity action recognition performance. Extensive experiments on six datasets, including NTU Mutual 11/26, H2O, Assembly101, Collective Activity and Volleyball, consistently verify our approach by seamlessly adapting to single-entity backbones and boosting their performance in multi-entity scenarios. Our code is publicly available at https://github.com/Necolizer/CHASE .
Learning Mutual Excitation for Hand-to-Hand and Human-to-Human Interaction Recognition
Feb 04, 2024



Recognizing interactive actions, including hand-to-hand interaction and human-to-human interaction, has attracted increasing attention for various applications in the field of video analysis and human-robot interaction. Considering the success of graph convolution in modeling topology-aware features from skeleton data, recent methods commonly operate graph convolution on separate entities and use late fusion for interactive action recognition, which can barely model the mutual semantic relationships between pairwise entities. To this end, we propose a mutual excitation graph convolutional network (me-GCN) by stacking mutual excitation graph convolution (me-GC) layers. Specifically, me-GC uses a mutual topology excitation module to firstly extract adjacency matrices from individual entities and then adaptively model the mutual constraints between them. Moreover, me-GC extends the above idea and further uses a mutual feature excitation module to extract and merge deep features from pairwise entities. Compared with graph convolution, our proposed me-GC gradually learns mutual information in each layer and each stage of graph convolution operations. Extensive experiments on a challenging hand-to-hand interaction dataset, i.e., the Assembely101 dataset, and two large-scale human-to-human interaction datasets, i.e., NTU60-Interaction and NTU120-Interaction consistently verify the superiority of our proposed method, which outperforms the state-of-the-art GCN-based and Transformer-based methods.
Dynamic Compositional Graph Convolutional Network for Efficient Composite Human Motion Prediction
Nov 23, 2023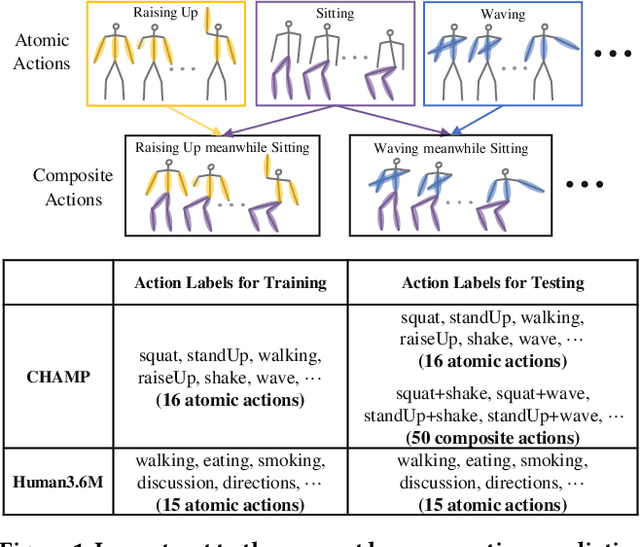
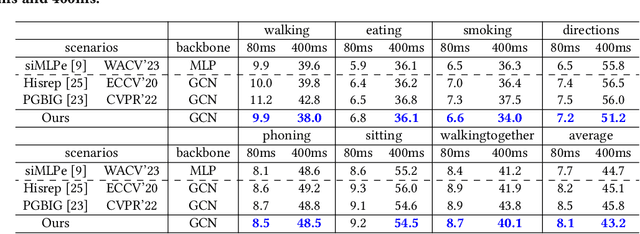
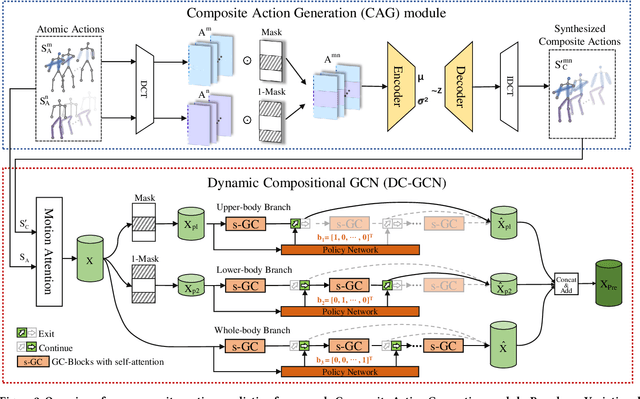
With potential applications in fields including intelligent surveillance and human-robot interaction, the human motion prediction task has become a hot research topic and also has achieved high success, especially using the recent Graph Convolutional Network (GCN). Current human motion prediction task usually focuses on predicting human motions for atomic actions. Observing that atomic actions can happen at the same time and thus formulating the composite actions, we propose the composite human motion prediction task. To handle this task, we first present a Composite Action Generation (CAG) module to generate synthetic composite actions for training, thus avoiding the laborious work of collecting composite action samples. Moreover, we alleviate the effect of composite actions on demand for a more complicated model by presenting a Dynamic Compositional Graph Convolutional Network (DC-GCN). Extensive experiments on the Human3.6M dataset and our newly collected CHAMP dataset consistently verify the efficiency of our DC-GCN method, which achieves state-of-the-art motion prediction accuracies and meanwhile needs few extra computational costs than traditional GCN-based human motion methods.
Frequency Compensated Diffusion Model for Real-scene Dehazing
Aug 21, 2023



Due to distribution shift, deep learning based methods for image dehazing suffer from performance degradation when applied to real-world hazy images. In this paper, we consider a dehazing framework based on conditional diffusion models for improved generalization to real haze. First, we find that optimizing the training objective of diffusion models, i.e., Gaussian noise vectors, is non-trivial. The spectral bias of deep networks hinders the higher frequency modes in Gaussian vectors from being learned and hence impairs the reconstruction of image details. To tackle this issue, we design a network unit, named Frequency Compensation block (FCB), with a bank of filters that jointly emphasize the mid-to-high frequencies of an input signal. We demonstrate that diffusion models with FCB achieve significant gains in both perceptual and distortion metrics. Second, to further boost the generalization performance, we propose a novel data synthesis pipeline, HazeAug, to augment haze in terms of degree and diversity. Within the framework, a solid baseline for blind dehazing is set up where models are trained on synthetic hazy-clean pairs, and directly generalize to real data. Extensive evaluations show that the proposed dehazing diffusion model significantly outperforms state-of-the-art methods on real-world images.
Federated Learning over a Wireless Network: Distributed User Selection through Random Access
Jul 07, 2023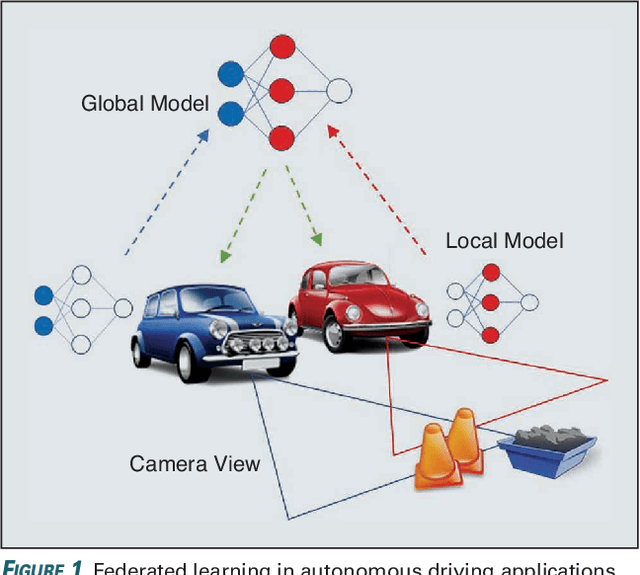
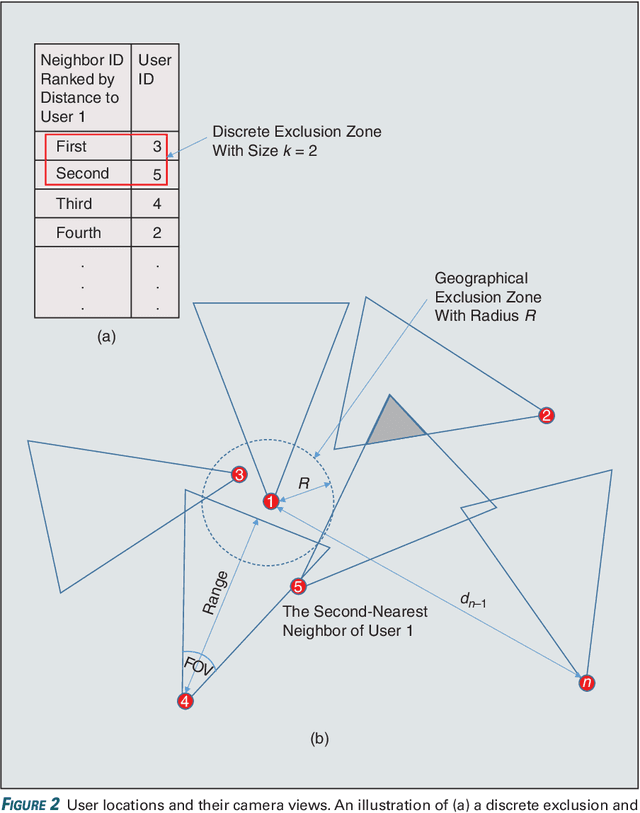
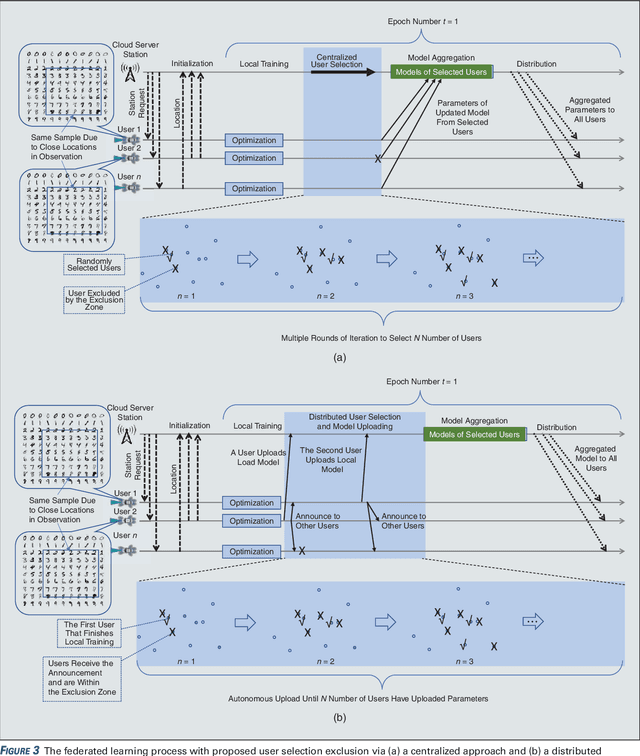
User selection has become crucial for decreasing the communication costs of federated learning (FL) over wireless networks. However, centralized user selection causes additional system complexity. This study proposes a network intrinsic approach of distributed user selection that leverages the radio resource competition mechanism in random access. Taking the carrier sensing multiple access (CSMA) mechanism as an example of random access, we manipulate the contention window (CW) size to prioritize certain users for obtaining radio resources in each round of training. Training data bias is used as a target scenario for FL with user selection. Prioritization is based on the distance between the newly trained local model and the global model of the previous round. To avoid excessive contribution by certain users, a counting mechanism is used to ensure fairness. Simulations with various datasets demonstrate that this method can rapidly achieve convergence similar to that of the centralized user selection approach.