 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariFace: Fair and Diverse Synthetic Dataset Generation for Face Recognition
Paper and Code
Dec 09, 2024

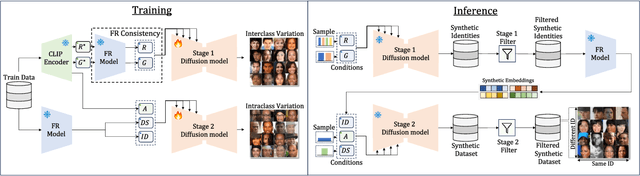

The use of large-scale, web-scraped datasets to train face recognition models has raised significant privacy and bias concerns. Synthetic methods mitigate these concerns and provide scalable and controllable face generation to enable fair and accurate face recognition. However, existing synthetic datasets display limited intraclass and interclass diversity and do not match the face recognition performance obtained using real datasets. Here, we propose VariFace, a two-stage diffusion-based pipeline to create fair and diverse synthetic face datasets to train face recognition models. Specifically, we introduce three methods: Face Recognition Consistency to refine demographic labels, Face Vendi Score Guidance to improve interclass diversity, and Divergence Score Conditioning to balance the identity preservation-intraclass diversity trade-off. When constrained to the same dataset size, VariFace considerably outperforms previous synthetic datasets (0.9200 $\rightarrow$ 0.9405) and achieves comparable performance to face recognition models trained with real data (Real Gap = -0.0065). In an unconstrained setting, VariFace not only consistently achieves better performance compared to previous synthetic methods across dataset sizes but also, for the first time, outperforms the real dataset (CASIA-WebFace) across six evaluation datasets. This sets a new state-of-the-art performance with an average face verification accuracy of 0.9567 (Real Gap = +0.0097) across LFW, CFP-FP, CPLFW, AgeDB, and CALFW datasets and 0.9366 (Real Gap = +0.0380) on the RFW dataset.