 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariFace: Fair and Diverse Synthetic Dataset Generation for Face Recognition
Dec 09, 2024

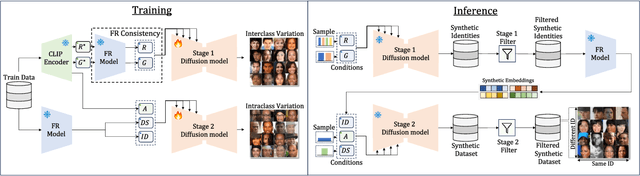

The use of large-scale, web-scraped datasets to train face recognition models has raised significant privacy and bias concerns. Synthetic methods mitigate these concerns and provide scalable and controllable face generation to enable fair and accurate face recognition. However, existing synthetic datasets display limited intraclass and interclass diversity and do not match the face recognition performance obtained using real datasets. Here, we propose VariFace, a two-stage diffusion-based pipeline to create fair and diverse synthetic face datasets to train face recognition models. Specifically, we introduce three methods: Face Recognition Consistency to refine demographic labels, Face Vendi Score Guidance to improve interclass diversity, and Divergence Score Conditioning to balance the identity preservation-intraclass diversity trade-off. When constrained to the same dataset size, VariFace considerably outperforms previous synthetic datasets (0.9200 $\rightarrow$ 0.9405) and achieves comparable performance to face recognition models trained with real data (Real Gap = -0.0065). In an unconstrained setting, VariFace not only consistently achieves better performance compared to previous synthetic methods across dataset sizes but also, for the first time, outperforms the real dataset (CASIA-WebFace) across six evaluation datasets. This sets a new state-of-the-art performance with an average face verification accuracy of 0.9567 (Real Gap = +0.0097) across LFW, CFP-FP, CPLFW, AgeDB, and CALFW datasets and 0.9366 (Real Gap = +0.0380) on the RFW dataset.
3DFlowRenderer: One-shot Face Re-enactment via Dense 3D Facial Flow Estimation
Apr 23, 2024Performing facial expression transfer under one-shot setting has been increasing in popularity among research community with a focus on precise control of expressions. Existing techniques showcase compelling results in perceiving expressions, but they lack robustness with extreme head poses. They also struggle to accurately reconstruct background details, thus hindering the realism. In this paper, we propose a novel warping technology which integrates the advantages of both 2D and 3D methods to achieve robust face re-enactment. We generate dense 3D facial flow fields in feature space to warp an input image based on target expressions without depth information. This enables explicit 3D geometric control for re-enacting misaligned source and target faces. We regularize the motion estimation capability of the 3D flow prediction network through proposed "Cyclic warp loss" by converting warped 3D features back into 2D RGB space. To ensure the generation of finer facial region with natural-background, our framework only renders the facial foreground region first and learns to inpaint the blank area which needs to be filled due to source face translation, thus reconstructing the detailed background without any unwanted pixel motion. Extensive evaluation reveals that our method outperforms state-of-the-art techniques in rendering artifact-free facial images.
Naming Objects for Vision-and-Language Manipulation
Mar 06, 2023Robot manipulation tasks by natural language instructions need common understanding of the target object between human and the robot. However, the instructions often have an interpretation ambiguity, because the instruction lacks important information, or does not express the target object correctly to complete the task. To solve this ambiguity problem, we hypothesize that "naming" the target objects in advance will reduce the ambiguity of natural language instructions. We propose a robot system and method that incorporates naming with appearance of the objects in advance, so that in the later manipulation task, instruction can be performed with its unique name to disambiguate the objects easily. To demonstrate the effectiveness of our approach, we build a system that can memorize the target objects, and show that naming the objects facilitates detection of the target objects and improves the success rate of manipulation instructions. With this method, the success rate of object manipulation task increases by 31% in ambiguous instructions.
SqueezeNeRF: Further factorized FastNeRF for memory-efficient inference
Apr 07, 2022
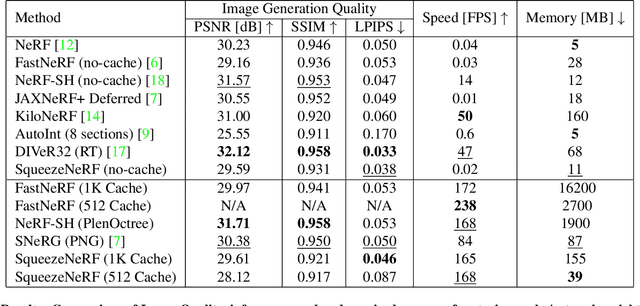
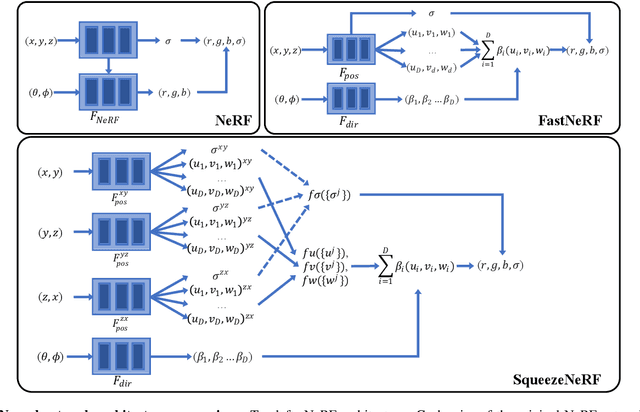
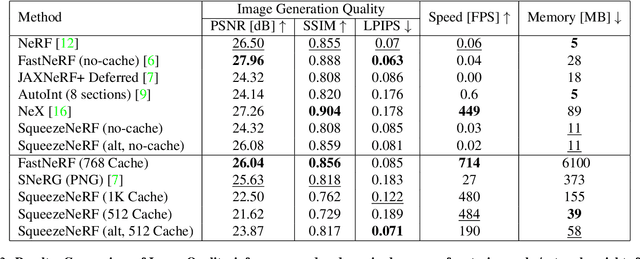
Neural Radiance Fields (NeRF) has emerged as the state-of-the-art method for novel view generation of complex scenes, but is very slow during inference. Recently, there have been multiple works on speeding up NeRF inference, but the state of the art methods for real-time NeRF inference rely on caching the neural network output, which occupies several giga-bytes of disk space that limits their real-world applicability. As caching the neural network of original NeRF network is not feasible, Garbin et al. proposed "FastNeRF" which factorizes the problem into 2 sub-networks - one which depends only on the 3D coordinate of a sample point and one which depends only on the 2D camera viewing direction. Although this factorization enables them to reduce the cache size and perform inference at over 200 frames per second, the memory overhead is still substantial. In this work, we propose SqueezeNeRF, which is more than 60 times memory-efficient than the sparse cache of FastNeRF and is still able to render at more than 190 frames per second on a high spec GPU during inference.
Thinking the Fusion Strategy of Multi-reference Face Reenactment
Feb 22, 2022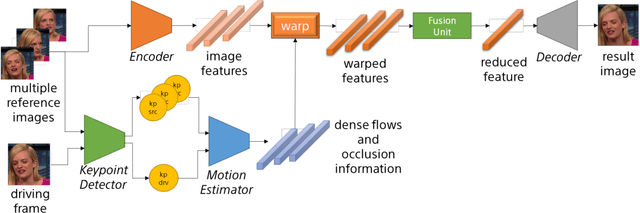



In recent advances of deep generative models, face reenactment -manipulating and controlling human face, including their head movement-has drawn much attention for its wide range of applicability. Despite its strong expressiveness, it is inevitable that the models fail to reconstruct or accurately generate unseen side of the face of a given single reference image. Most of existing methods alleviate this problem by learning appearances of human faces from large amount of data and generate realistic texture at inference time. Rather than completely relying on what generative models learn, we show that simple extension by using multiple reference images significantly improves generation quality. We show this by 1) conducting the reconstruction task on publicly available dataset, 2) conducting facial motion transfer on our original dataset which consists of multi-person's head movement video sequences, and 3) using a newly proposed evaluation metric to validate that our method achieves better quantitative results.