 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Improving Wind Resistance Performance of Cascaded PID Controlled Quadcopters using Residual Reinforcement Learning
Aug 03, 2023



Wind resistance control is an essential feature for quadcopters to maintain their position to avoid deviation from target position and prevent collisions with obstacles. Conventionally, cascaded PID controller is used for the control of quadcopters for its simplicity and ease of tuning its parameters. However, it is weak against wind disturbances and the quadcopter can easily deviate from target position. In this work, we propose a residual reinforcement learning based approach to build a wind resistance controller of a quadcopter. By learning only the residual that compensates the disturbance, we can continue using the cascaded PID controller as the base controller of the quadcopter but improve its performance against wind disturbances. To avoid unexpected crashes and destructions of quadcopters, our method does not require real hardware for data collection and training. The controller is trained only on a simulator and directly applied to the target hardware without extra finetuning process. We demonstrate the effectiveness of our approach through various experiments including an experiment in an outdoor scene with wind speed greater than 13 m/s. Despite its simplicity, our controller reduces the position deviation by approximately 50% compared to the quadcopter controlled with the conventional cascaded PID controller. Furthermore, trained controller is robust and preserves its performance even though the quadcopter's mass and propeller's lift coefficient is changed between 50% to 150% from original training time.
Naming Objects for Vision-and-Language Manipulation
Mar 06, 2023Robot manipulation tasks by natural language instructions need common understanding of the target object between human and the robot. However, the instructions often have an interpretation ambiguity, because the instruction lacks important information, or does not express the target object correctly to complete the task. To solve this ambiguity problem, we hypothesize that "naming" the target objects in advance will reduce the ambiguity of natural language instructions. We propose a robot system and method that incorporates naming with appearance of the objects in advance, so that in the later manipulation task, instruction can be performed with its unique name to disambiguate the objects easily. To demonstrate the effectiveness of our approach, we build a system that can memorize the target objects, and show that naming the objects facilitates detection of the target objects and improves the success rate of manipulation instructions. With this method, the success rate of object manipulation task increases by 31% in ambiguous instructions.
Dual Normalization Multitasking for Audio-Visual Sounding Object Localization
Jun 01, 2021

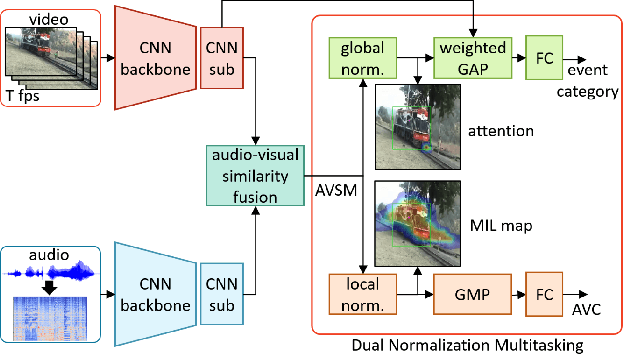

Although several research works have been reported on audio-visual sound source localization in unconstrained videos, no datasets and metrics have been proposed in the literature to quantitatively evaluate its performance. Defining the ground truth for sound source localization is difficult, because the location where the sound is produced is not limited to the range of the source object, but the vibrations propagate and spread through the surrounding objects. Therefore we propose a new concept, Sounding Object, to reduce the ambiguity of the visual location of sound, making it possible to annotate the location of the wide range of sound sources. With newly proposed metrics for quantitative evaluation, we formulate the problem of Audio-Visual Sounding Object Localization (AVSOL). We also created the evaluation dataset (AVSOL-E dataset) by manually annotating the test set of well-known Audio-Visual Event (AVE) dataset. To tackle this new AVSOL problem, we propose a novel multitask training strategy and architecture called Dual Normalization Multitasking (DNM), which aggregates the Audio-Visual Correspondence (AVC) task and the classification task for video events into a single audio-visual similarity map. By efficiently utilize both supervisions by DNM, our proposed architecture significantly outperforms the baseline methods.