 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025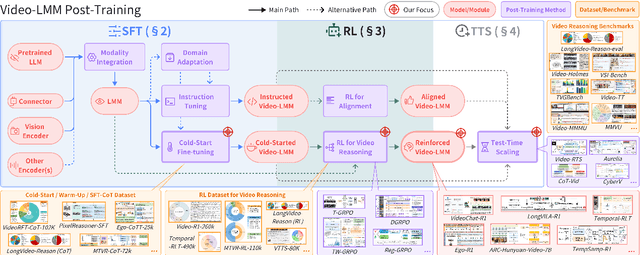
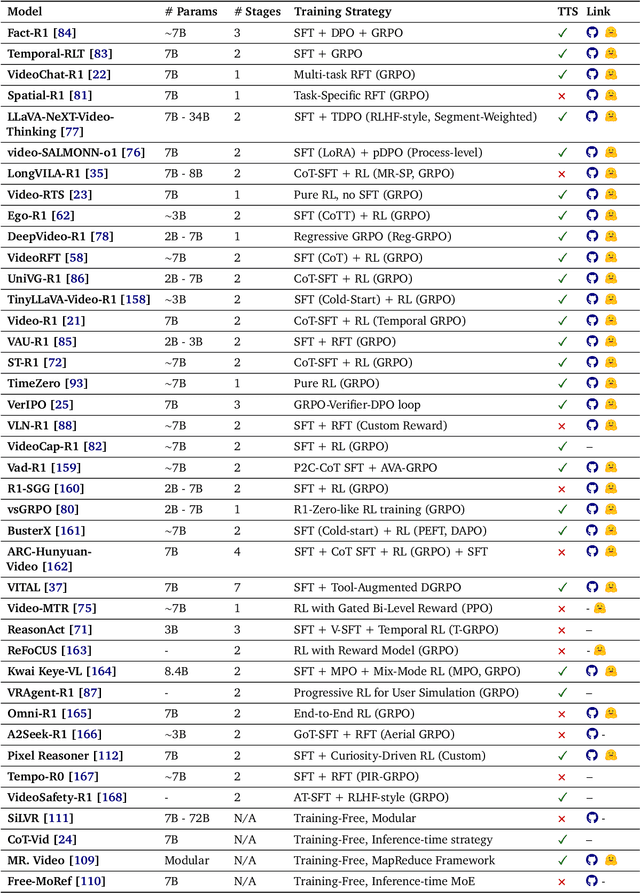
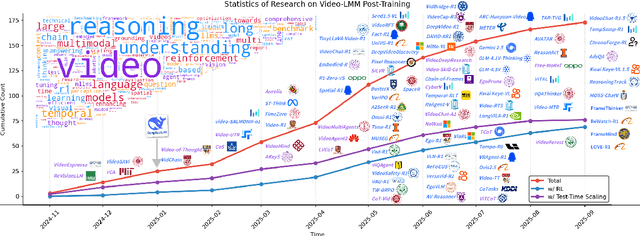
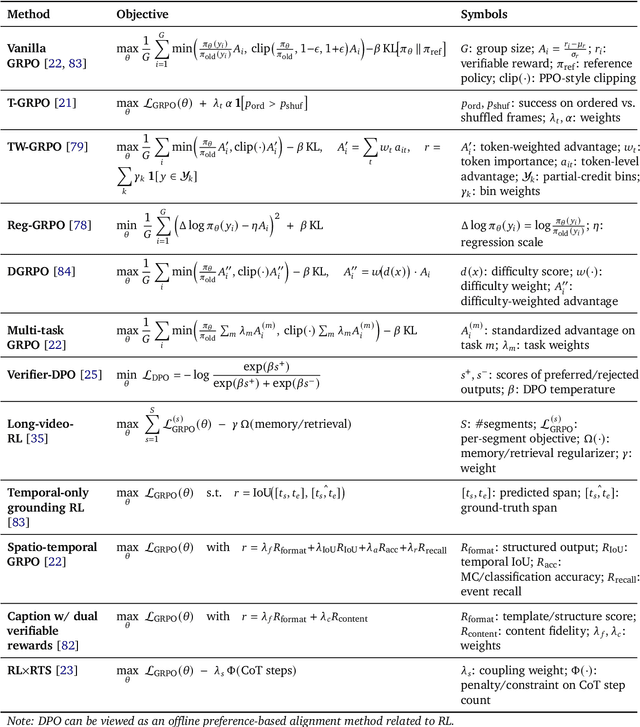
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Rethinking Audio-Visual Adversarial Vulnerability from Temporal and Modality Perspectives
Feb 19, 2025



While audio-visual learning equips models with a richer understanding of the real world by leveraging multiple sensory modalities, this integration also introduces new vulnerabilities to adversarial attacks. In this paper, we present a comprehensive study of the adversarial robustness of audio-visual models, considering both temporal and modality-specific vulnerabilities. We propose two powerful adversarial attacks: 1) a temporal invariance attack that exploits the inherent temporal redundancy across consecutive time segments and 2) a modality misalignment attack that introduces incongruence between the audio and visual modalities. These attacks are designed to thoroughly assess the robustness of audio-visual models against diverse threats. Furthermore, to defend against such attacks, we introduce a novel audio-visual adversarial training framework. This framework addresses key challenges in vanilla adversarial training by incorporating efficient adversarial perturbation crafting tailored to multi-modal data and an adversarial curriculum strategy. Extensive experiments in the Kinetics-Sounds dataset demonstrate that our proposed temporal and modality-based attacks in degrading model performance can achieve state-of-the-art performance, while our adversarial training defense largely improves the adversarial robustness as well as the adversarial training efficiency.
AVicuna: Audio-Visual LLM with Interleaver and Context-Boundary Alignment for Temporal Referential Dialogue
Mar 24, 2024



In everyday communication, humans frequently use speech and gestures to refer to specific areas or objects, a process known as Referential Dialogue (RD). While prior studies have investigated RD through Large Language Models (LLMs) or Large Multimodal Models (LMMs) in static contexts, the exploration of Temporal Referential Dialogue (TRD) within audio-visual media remains limited. Two primary challenges hinder progress in this field: (1) the absence of comprehensive, untrimmed audio-visual video datasets with precise temporal annotations, and (2) the need for methods to integrate complex temporal auditory and visual cues effectively. To address these challenges, we introduce a novel framework to generate PU-VALOR, an extensive audio-visual dataset comprising over 114,000 untrimmed videos with accurate temporal demarcations. We also present AVicuna, featuring an Audio-Visual Tokens Interleaver (AVTI) that ensures the temporal alignment of audio-visual information. Additionally, we develop the A5-222K dataset, encompassing more than 200,000 audio-text pairings, to facilitate the audio and text alignments. Our experiments demonstrate that AVicuna can effectively handle TRD in audio-visual videos and achieve state-of-the-art performance on various audio-visual video understanding tasks, particularly in untrimmed videos. We further investigate the optimal audio-interleaving rate for interleaved audio-visual inputs, which maximizes performance on the Audio-Visual Event Dense Localization task.
Dual Normalization Multitasking for Audio-Visual Sounding Object Localization
Jun 01, 2021

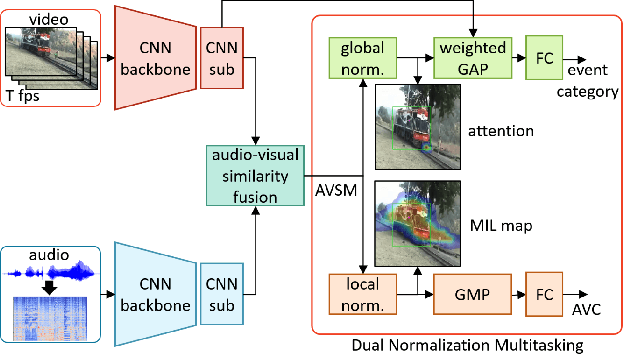

Although several research works have been reported on audio-visual sound source localization in unconstrained videos, no datasets and metrics have been proposed in the literature to quantitatively evaluate its performance. Defining the ground truth for sound source localization is difficult, because the location where the sound is produced is not limited to the range of the source object, but the vibrations propagate and spread through the surrounding objects. Therefore we propose a new concept, Sounding Object, to reduce the ambiguity of the visual location of sound, making it possible to annotate the location of the wide range of sound sources. With newly proposed metrics for quantitative evaluation, we formulate the problem of Audio-Visual Sounding Object Localization (AVSOL). We also created the evaluation dataset (AVSOL-E dataset) by manually annotating the test set of well-known Audio-Visual Event (AVE) dataset. To tackle this new AVSOL problem, we propose a novel multitask training strategy and architecture called Dual Normalization Multitasking (DNM), which aggregates the Audio-Visual Correspondence (AVC) task and the classification task for video events into a single audio-visual similarity map. By efficiently utilize both supervisions by DNM, our proposed architecture significantly outperforms the baseline methods.