 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025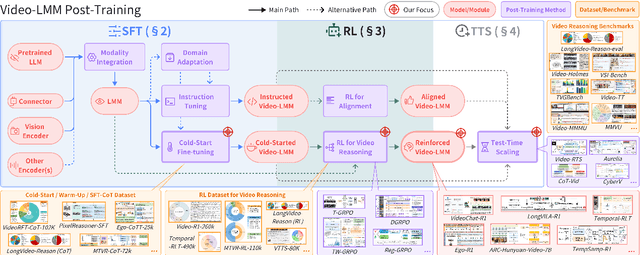
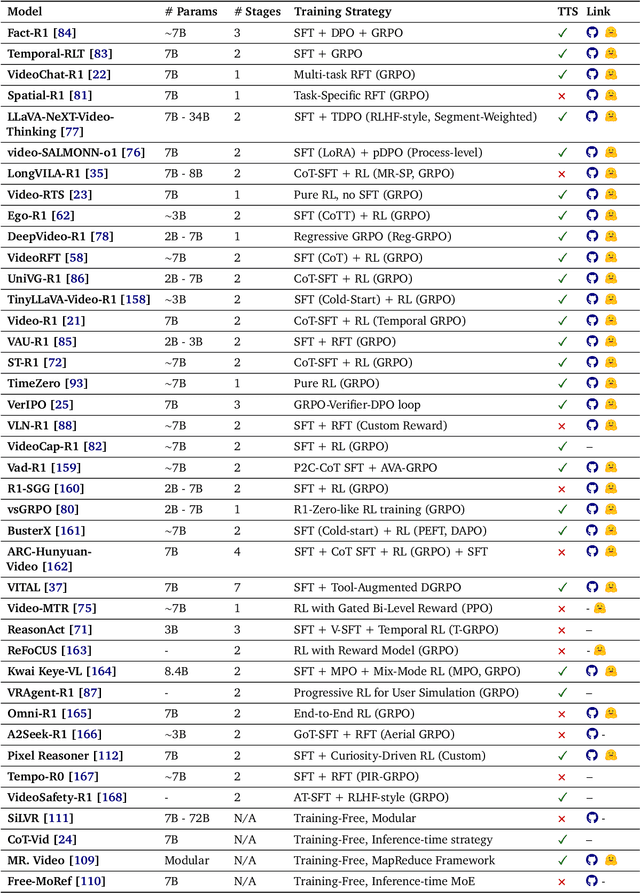
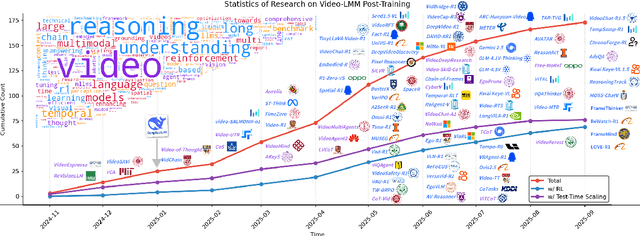
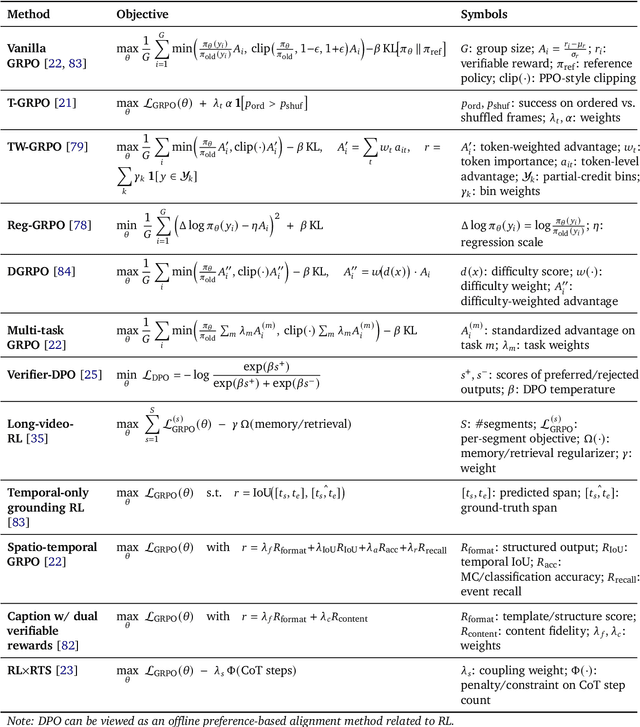
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Can Sound Replace Vision in LLaVA With Token Substitution?
Jun 12, 2025While multimodal systems have achieved impressive advances, they typically rely on text-aligned representations rather than directly integrating audio and visual inputs. This reliance can limit the use of acoustic information in tasks requiring nuanced audio understanding. In response, SoundCLIP explores direct audio-visual integration within multimodal large language models (MLLMs) by substituting CLIP's visual tokens with audio representations and selecting sound-relevant patch tokens in models such as LLaVA. We investigate two configurations: (1) projecting audio features into CLIP's visual manifold via a multilayer perceptron trained with InfoNCE on paired audio-video segments, and (2) preserving raw audio embeddings with minimal dimensional adjustments. Experiments with five state-of-the-art audio encoders reveal a fundamental trade-off. While audio-to-video retrieval performance increases dramatically (up to 44 percentage points in Top-1 accuracy) when audio is projected into CLIP's space, text generation quality declines. Encoders pre-trained with text supervision (CLAP, Whisper, ImageBind) maintain stronger generative capabilities than those focused primarily on audiovisual alignment (Wav2CLIP, AudioCLIP), highlighting the value of language exposure for generation tasks. We introduce WhisperCLIP, an architecture that fuses intermediate representations from Whisper, as well as AudioVisual Event Evaluation (AVE-2), a dataset of 580,147 three-second audiovisual clips with fine-grained alignment annotations. Our findings challenge the assumption that stronger cross-modal alignment necessarily benefits all multimodal tasks; instead, a Pareto frontier emerges wherein optimal performance depends on balancing retrieval accuracy with text generation quality. Codes and datasets: https://github.com/ali-vosoughi/SoundCLIP.
ZeroSep: Separate Anything in Audio with Zero Training
May 29, 2025Audio source separation is fundamental for machines to understand complex acoustic environments and underpins numerous audio applications. Current supervised deep learning approaches, while powerful, are limited by the need for extensive, task-specific labeled data and struggle to generalize to the immense variability and open-set nature of real-world acoustic scenes. Inspired by the success of generative foundation models, we investigate whether pre-trained text-guided audio diffusion models can overcome these limitations. We make a surprising discovery: zero-shot source separation can be achieved purely through a pre-trained text-guided audio diffusion model under the right configuration. Our method, named ZeroSep, works by inverting the mixed audio into the diffusion model's latent space and then using text conditioning to guide the denoising process to recover individual sources. Without any task-specific training or fine-tuning, ZeroSep repurposes the generative diffusion model for a discriminative separation task and inherently supports open-set scenarios through its rich textual priors. ZeroSep is compatible with a variety of pre-trained text-guided audio diffusion backbones and delivers strong separation performance on multiple separation benchmarks, surpassing even supervised methods.
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
The Sword of Damocles in ViTs: Computational Redundancy Amplifies Adversarial Transferability
Apr 15, 2025Vision Transformers (ViTs) have demonstrated impressive performance across a range of applications, including many safety-critical tasks. However, their unique architectural properties raise new challenges and opportunities in adversarial robustness. In particular, we observe that adversarial examples crafted on ViTs exhibit higher transferability compared to those crafted on CNNs, suggesting that ViTs contain structural characteristics favorable for transferable attacks. In this work, we investigate the role of computational redundancy in ViTs and its impact on adversarial transferability. Unlike prior studies that aim to reduce computation for efficiency, we propose to exploit this redundancy to improve the quality and transferability of adversarial examples. Through a detailed analysis, we identify two forms of redundancy, including the data-level and model-level, that can be harnessed to amplify attack effectiveness. Building on this insight, we design a suite of techniques, including attention sparsity manipulation, attention head permutation, clean token regularization, ghost MoE diversification, and test-time adversarial training. Extensive experiments on the ImageNet-1k dataset validate the effectiveness of our approach, showing that our methods significantly outperform existing baselines in both transferability and generality across diverse model architectures.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025
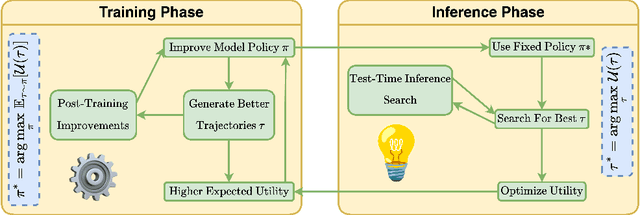
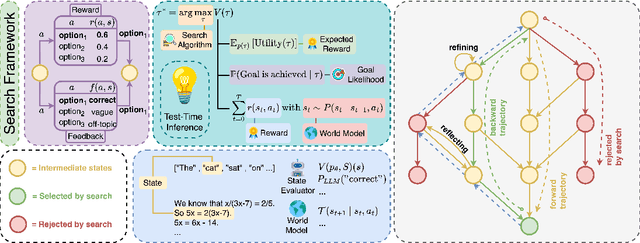
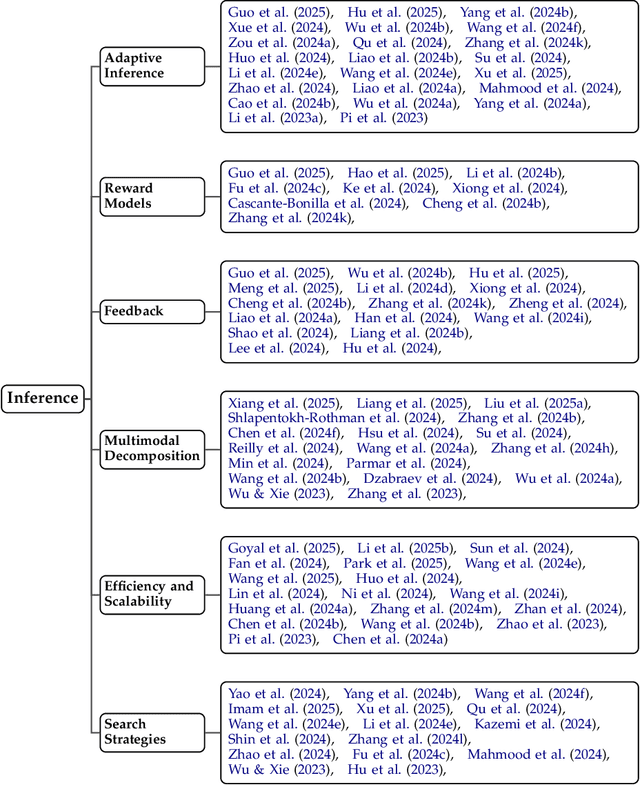
Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.
FreSca: Unveiling the Scaling Space in Diffusion Models
Apr 02, 2025Diffusion models offer impressive controllability for image tasks, primarily through noise predictions that encode task-specific information and classifier-free guidance enabling adjustable scaling. This scaling mechanism implicitly defines a ``scaling space'' whose potential for fine-grained semantic manipulation remains underexplored. We investigate this space, starting with inversion-based editing where the difference between conditional/unconditional noise predictions carries key semantic information. Our core contribution stems from a Fourier analysis of noise predictions, revealing that its low- and high-frequency components evolve differently throughout diffusion. Based on this insight, we introduce FreSca, a straightforward method that applies guidance scaling independently to different frequency bands in the Fourier domain. FreSca demonstrably enhances existing image editing methods without retraining. Excitingly, its effectiveness extends to image understanding tasks such as depth estimation, yielding quantitative gains across multiple datasets.