 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025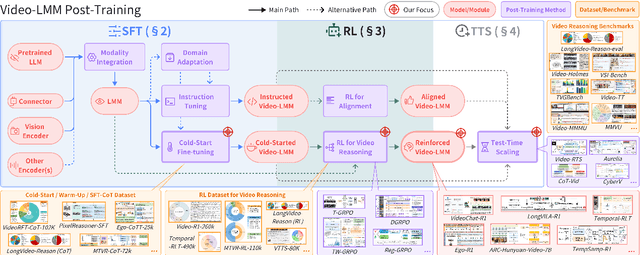
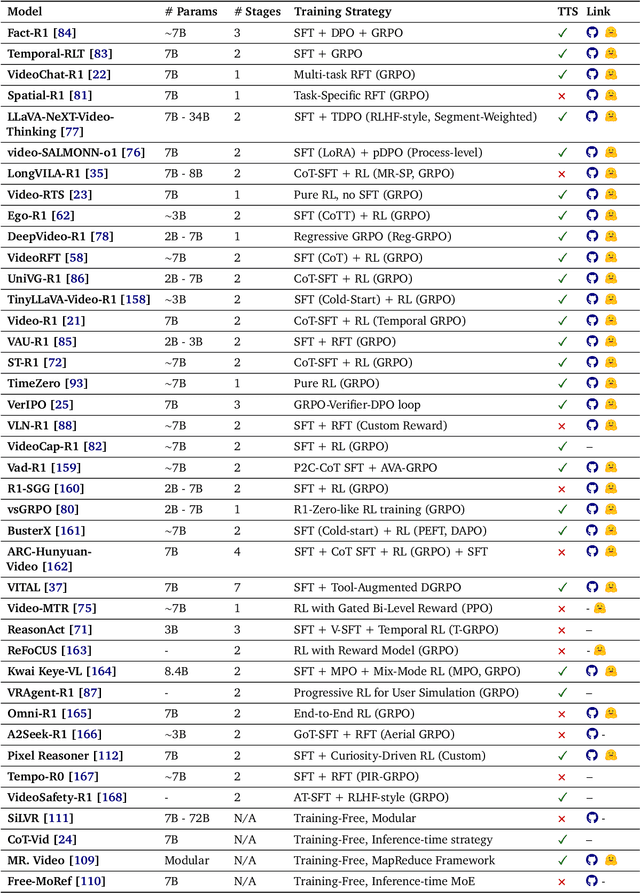
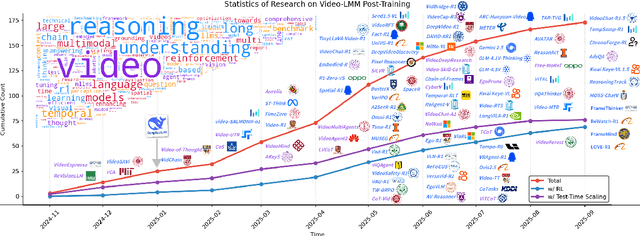
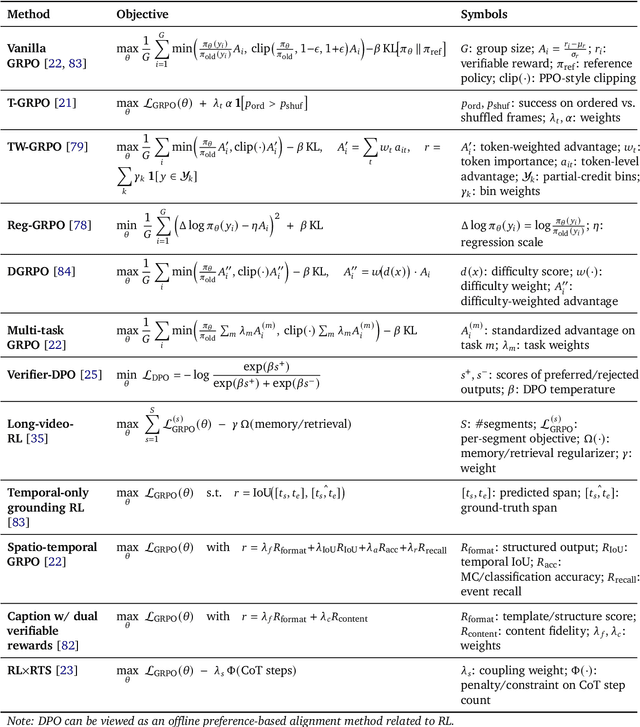
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
Segregation and Context Aggregation Network for Real-time Cloud Segmentation
Apr 19, 2025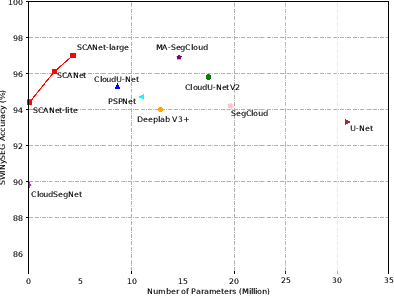
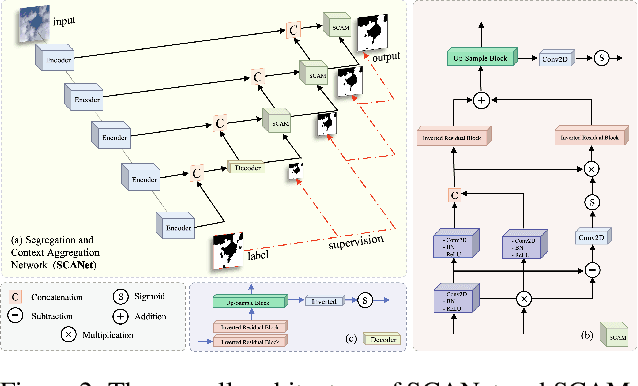
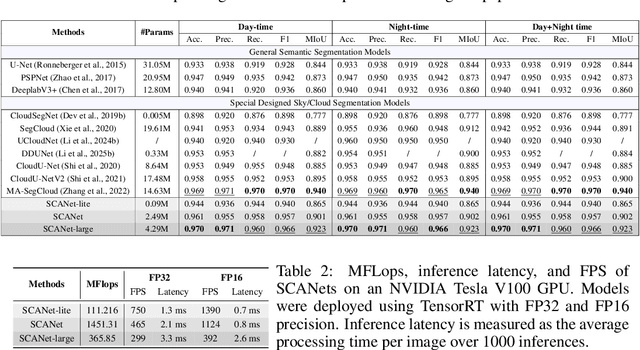

Cloud segmentation from intensity images is a pivotal task in atmospheric science and computer vision, aiding weather forecasting and climate analysis. Ground-based sky/cloud segmentation extracts clouds from images for further feature analysis. Existing methods struggle to balance segmentation accuracy and computational efficiency, limiting real-world deployment on edge devices, so we introduce SCANet, a novel lightweight cloud segmentation model featuring Segregation and Context Aggregation Module (SCAM), which refines rough segmentation maps into weighted sky and cloud features processed separately. SCANet achieves state-of-the-art performance while drastically reducing computational complexity. SCANet-large (4.29M) achieves comparable accuracy to state-of-the-art methods with 70.9% fewer parameters. Meanwhile, SCANet-lite (90K) delivers 1390 fps in FP16, surpassing real-time standards. Additionally, we propose an efficient pre-training strategy that enhances performance even without ImageNet pre-training.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
DDUNet: Dual Dynamic U-Net for Highly-Efficient Cloud Segmentation
Jan 26, 2025



Cloud segmentation amounts to separating cloud pixels from non-cloud pixels in an image. Current deep learning methods for cloud segmentation suffer from three issues. (a) Constrain on their receptive field due to the fixed size of the convolution kernel. (b) Lack of robustness towards different scenarios. (c) Requirement of a large number of parameters and limitations for real-time implementation. To address these issues, we propose a Dual Dynamic U-Net (DDUNet) for supervised cloud segmentation. The DDUNet adheres to a U-Net architecture and integrates two crucial modules: the dynamic multi-scale convolution (DMSC), improving merging features under different reception fields, and the dynamic weights and bias generator (DWBG) in classification layers to enhance generalization ability. More importantly, owing to the use of depth-wise convolution, the DDUNet is a lightweight network that can achieve 95.3% accuracy on the SWINySEG dataset with only 0.33M parameters, and achieve superior performance over three different configurations of the SWINySEg dataset in both accuracy and efficiency.
Generative AI for Cel-Animation: A Survey
Jan 08, 2025



Traditional Celluloid (Cel) Animation production pipeline encompasses multiple essential steps, including storyboarding, layout design, keyframe animation, inbetweening, and colorization, which demand substantial manual effort, technical expertise, and significant time investment. These challenges have historically impeded the efficiency and scalability of Cel-Animation production. The rise of generative artificial intelligence (GenAI), encompassing large language models, multimodal models, and diffusion models, offers innovative solutions by automating tasks such as inbetween frame generation, colorization, and storyboard creation. This survey explores how GenAI integration is revolutionizing traditional animation workflows by lowering technical barriers, broadening accessibility for a wider range of creators through tools like AniDoc, ToonCrafter, and AniSora, and enabling artists to focus more on creative expression and artistic innovation. Despite its potential, issues such as maintaining visual consistency, ensuring stylistic coherence, and addressing ethical considerations continue to pose challenges. Furthermore, this paper discusses future directions and explores potential advancements in AI-assisted animation. For further exploration and resources, please visit our GitHub repository: https://github.com/yunlong10/Awesome-AI4Animation