 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Precise Video Language with Human-AI Oversight
Apr 22, 2026Video-language models (VLMs) learn to reason about the dynamic visual world through natural language. We introduce a suite of open datasets, benchmarks, and recipes for scalable oversight that enable precise video captioning. First, we define a structured specification for describing subjects, scenes, motion, spatial, and camera dynamics, grounded by hundreds of carefully defined visual primitives developed with professional video creators such as filmmakers. Next, to curate high-quality captions, we introduce CHAI (Critique-based Human-AI Oversight), a framework where trained experts critique and revise model-generated pre-captions into improved post-captions. This division of labor improves annotation accuracy and efficiency by offloading text generation to models, allowing humans to better focus on verification. Additionally, these critiques and preferences between pre- and post-captions provide rich supervision for improving open-source models (Qwen3-VL) on caption generation, reward modeling, and critique generation through SFT, DPO, and inference-time scaling. Our ablations show that critique quality in precision, recall, and constructiveness, ensured by our oversight framework, directly governs downstream performance. With modest expert supervision, the resulting model outperforms closed-source models such as Gemini-3.1-Pro. Finally, we apply our approach to re-caption large-scale professional videos (e.g., films, commercials, games) and fine-tune video generation models such as Wan to better follow detailed prompts of up to 400 words, achieving finer control over cinematography including camera motion, angle, lens, focus, point of view, and framing. Our results show that precise specification and human-AI oversight are key to professional-level video understanding and generation. Data and code are available on our project page: https://linzhiqiu.github.io/papers/chai/
Well Begun is Half Done: Training-Free and Model-Agnostic Semantically Guaranteed User Representation Initialization for Multimodal Recommendation
Apr 16, 2026Recent advancements in multimodal recommendations, which leverage diverse modality information to mitigate data sparsity and improve recommendation accuracy, have gained significant attention. However, existing multimodal recommendations overlook the critical role of user representation initialization. Unlike items, which are naturally associated with rich modality information, users lack such inherent information. Consequently, item representations initialized based on meaningful modality information and user representations initialized randomly exhibit a significant semantic gap. To this end, we propose a Semantically Guaranteed User Representation Initialization (SG-URInit). SG-URInit constructs the initial representation for each user by integrating both the modality features of the items they have interacted with and the global features of their corresponding clusters. SG-URInit enables the initialization of semantically enriched user representations that effectively capture both local (item-level) and global (cluster-level) semantics. Our SG-URInit is training-free and model-agnostic, meaning it can be seamlessly integrated into existing multimodal recommendation models without incurring any additional computational overhead during training. Extensive experiments on multiple real-world datasets demonstrate that incorporating SG-URInit into advanced multimodal recommendation models significantly enhances recommendation performance. Furthermore, the results show that SG-URInit can further alleviate the item cold-start problem and also accelerate model convergence, making it an efficient and practical solution for multimodal recommendations.
CAMMSR: Category-Guided Attentive Mixture of Experts for Multimodal Sequential Recommendation
Mar 04, 2026The explosion of multimedia data in information-rich environments has intensified the challenges of personalized content discovery, positioning recommendation systems as an essential form of passive data management. Multimodal sequential recommendation, which leverages diverse item information such as text and images, has shown great promise in enriching item representations and deepening the understanding of user interests. However, most existing models rely on heuristic fusion strategies that fail to capture the dynamic and context-sensitive nature of user-modal interactions. In real-world scenarios, user preferences for modalities vary not only across individuals but also within the same user across different items or categories. Moreover, the synergistic effects between modalities-where combined signals trigger user interest in ways isolated modalities cannot-remain largely underexplored. To this end, we propose CAMMSR, a Category-guided Attentive Mixture of Experts model for Multimodal Sequential Recommendation. At its core, CAMMSR introduces a category-guided attentive mixture of experts (CAMoE) module, which learns specialized item representations from multiple perspectives and explicitly models inter-modal synergies. This component dynamically allocates modality weights guided by an auxiliary category prediction task, enabling adaptive fusion of multimodal signals. Additionally, we design a modality swap contrastive learning task to enhance cross-modal representation alignment through sequence-level augmentation. Extensive experiments on four public datasets demonstrate that CAMMSR consistently outperforms state-of-the-art baselines, validating its effectiveness in achieving adaptive, synergistic, and user-centric multimodal sequential recommendation.
CLIP-Guided Unsupervised Semantic-Aware Exposure Correction
Jan 27, 2026Improper exposure often leads to severe loss of details, color distortion, and reduced contrast. Exposure correction still faces two critical challenges: (1) the ignorance of object-wise regional semantic information causes the color shift artifacts; (2) real-world exposure images generally have no ground-truth labels, and its labeling entails massive manual editing. To tackle the challenges, we propose a new unsupervised semantic-aware exposure correction network. It contains an adaptive semantic-aware fusion module, which effectively fuses the semantic information extracted from a pre-trained Fast Segment Anything Model into a shared image feature space. Then the fused features are used by our multi-scale residual spatial mamba group to restore the details and adjust the exposure. To avoid manual editing, we propose a pseudo-ground truth generator guided by CLIP, which is fine-tuned to automatically identify exposure situations and instruct the tailored corrections. Also, we leverage the rich priors from the FastSAM and CLIP to develop a semantic-prompt consistency loss to enforce semantic consistency and image-prompt alignment for unsupervised training. Comprehensive experimental results illustrate the effectiveness of our method in correcting real-world exposure images and outperforms state-of-the-art unsupervised methods both numerically and visually.
VI-MMRec: Similarity-Aware Training Cost-free Virtual User-Item Interactions for Multimodal Recommendation
Dec 09, 2025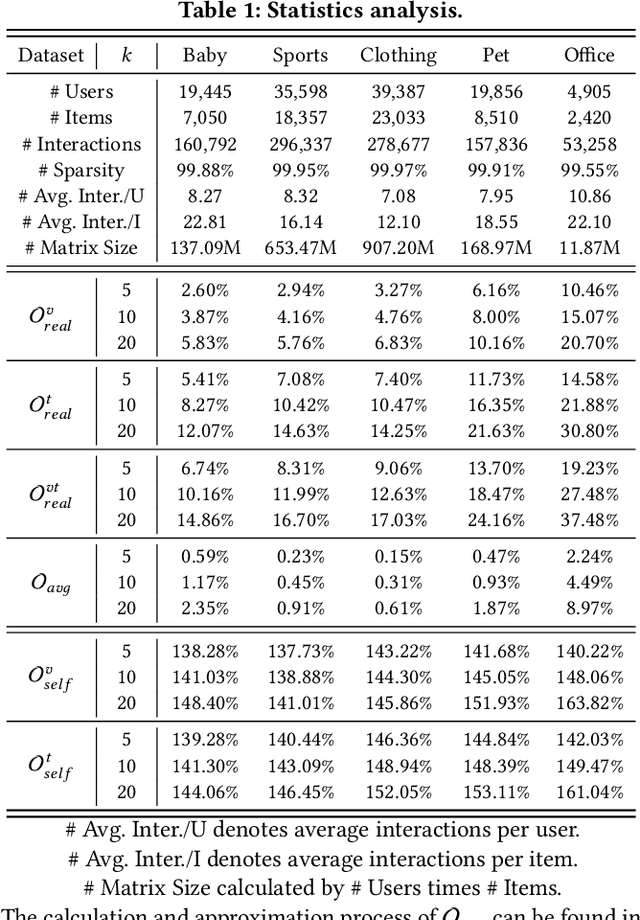
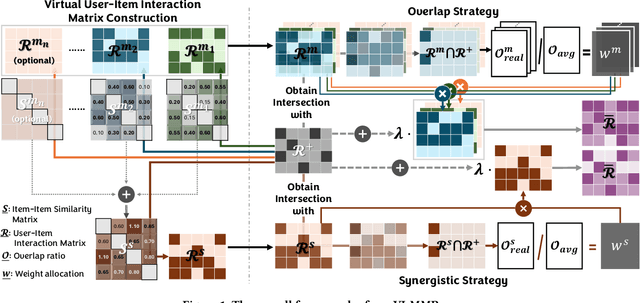
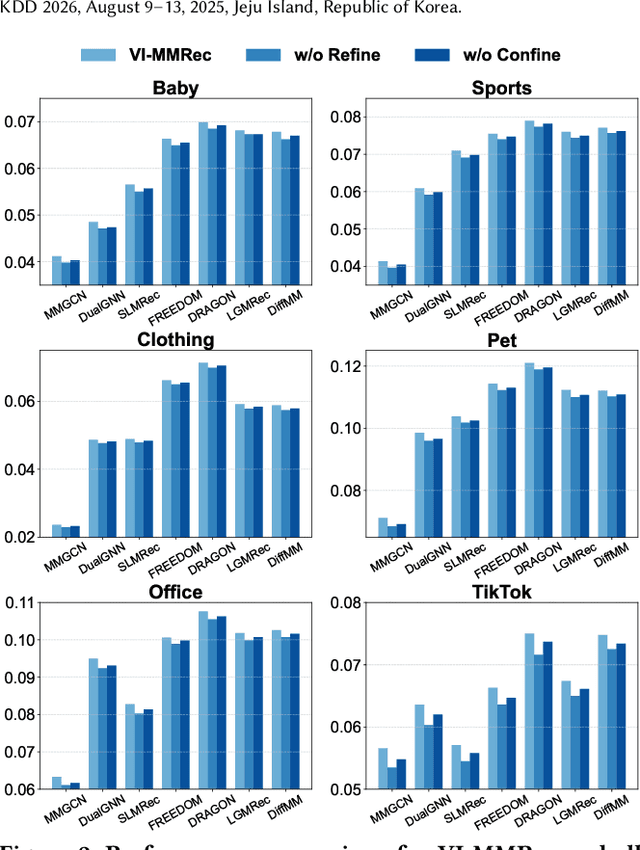
Although existing multimodal recommendation models have shown promising performance, their effectiveness continues to be limited by the pervasive data sparsity problem. This problem arises because users typically interact with only a small subset of available items, leading existing models to arbitrarily treat unobserved items as negative samples. To this end, we propose VI-MMRec, a model-agnostic and training cost-free framework that enriches sparse user-item interactions via similarity-aware virtual user-item interactions. These virtual interactions are constructed based on modality-specific feature similarities of user-interacted items. Specifically, VI-MMRec introduces two different strategies: (1) Overlay, which independently aggregates modality-specific similarities to preserve modality-specific user preferences, and (2) Synergistic, which holistically fuses cross-modal similarities to capture complementary user preferences. To ensure high-quality augmentation, we design a statistically informed weight allocation mechanism that adaptively assigns weights to virtual user-item interactions based on dataset-specific modality relevance. As a plug-and-play framework, VI-MMRec seamlessly integrates with existing models to enhance their performance without modifying their core architecture. Its flexibility allows it to be easily incorporated into various existing models, maximizing performance with minimal implementation effort. Moreover, VI-MMRec introduces no additional overhead during training, making it significantly advantageous for practical deployment. Comprehensive experiments conducted on six real-world datasets using seven state-of-the-art multimodal recommendation models validate the effectiveness of our VI-MMRec.
Learning and Editing Universal Graph Prompt Tuning via Reinforcement Learning
Dec 09, 2025Early graph prompt tuning approaches relied on task-specific designs for Graph Neural Networks (GNNs), limiting their adaptability across diverse pre-training strategies. In contrast, another promising line of research has investigated universal graph prompt tuning, which operates directly in the input graph's feature space and builds a theoretical foundation that universal graph prompt tuning can theoretically achieve an equivalent effect of any prompting function, eliminating dependence on specific pre-training strategies. Recent works propose selective node-based graph prompt tuning to pursue more ideal prompts. However, we argue that selective node-based graph prompt tuning inevitably compromises the theoretical foundation of universal graph prompt tuning. In this paper, we strengthen the theoretical foundation of universal graph prompt tuning by introducing stricter constraints, demonstrating that adding prompts to all nodes is a necessary condition for achieving the universality of graph prompts. To this end, we propose a novel model and paradigm, Learning and Editing Universal GrAph Prompt Tuning (LEAP), which preserves the theoretical foundation of universal graph prompt tuning while pursuing more ideal prompts. Specifically, we first build the basic universal graph prompts to preserve the theoretical foundation and then employ actor-critic reinforcement learning to select nodes and edit prompts. Extensive experiments on graph- and node-level tasks across various pre-training strategies in both full-shot and few-shot scenarios show that LEAP consistently outperforms fine-tuning and other prompt-based approaches.
Multi-modal Dynamic Proxy Learning for Personalized Multiple Clustering
Nov 10, 2025Multiple clustering aims to discover diverse latent structures from different perspectives, yet existing methods generate exhaustive clusterings without discerning user interest, necessitating laborious manual screening. Current multi-modal solutions suffer from static semantic rigidity: predefined candidate words fail to adapt to dataset-specific concepts, and fixed fusion strategies ignore evolving feature interactions. To overcome these limitations, we propose Multi-DProxy, a novel multi-modal dynamic proxy learning framework that leverages cross-modal alignment through learnable textual proxies. Multi-DProxy introduces 1) gated cross-modal fusion that synthesizes discriminative joint representations by adaptively modeling feature interactions. 2) dual-constraint proxy optimization where user interest constraints enforce semantic consistency with domain concepts while concept constraints employ hard example mining to enhance cluster discrimination. 3) dynamic candidate management that refines textual proxies through iterative clustering feedback. Therefore, Multi-DProxy not only effectively captures a user's interest through proxies but also enables the identification of relevant clusterings with greater precision. Extensive experiments demonstrate state-of-the-art performance with significant improvements over existing methods across a broad set of multi-clustering benchmarks.
NLGCL: Naturally Existing Neighbor Layers Graph Contrastive Learning for Recommendation
Jul 10, 2025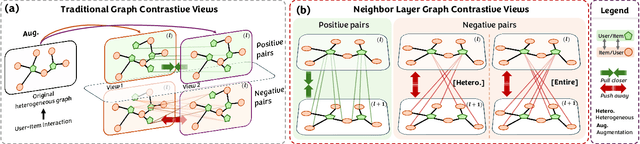
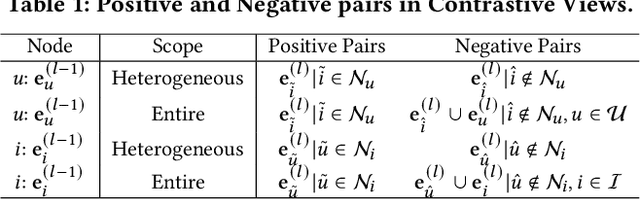
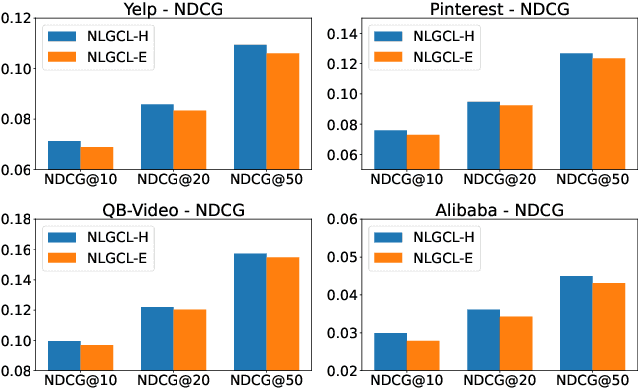
Graph Neural Networks (GNNs) are widely used in collaborative filtering to capture high-order user-item relationships. To address the data sparsity problem in recommendation systems, Graph Contrastive Learning (GCL) has emerged as a promising paradigm that maximizes mutual information between contrastive views. However, existing GCL methods rely on augmentation techniques that introduce semantically irrelevant noise and incur significant computational and storage costs, limiting effectiveness and efficiency. To overcome these challenges, we propose NLGCL, a novel contrastive learning framework that leverages naturally contrastive views between neighbor layers within GNNs. By treating each node and its neighbors in the next layer as positive pairs, and other nodes as negatives, NLGCL avoids augmentation-based noise while preserving semantic relevance. This paradigm eliminates costly view construction and storage, making it computationally efficient and practical for real-world scenarios. Extensive experiments on four public datasets demonstrate that NLGCL outperforms state-of-the-art baselines in effectiveness and efficiency.
Consistent Video Editing as Flow-Driven Image-to-Video Generation
Jun 09, 2025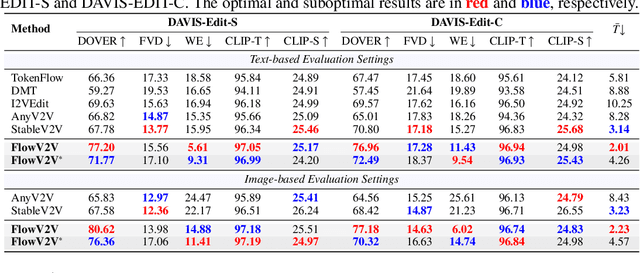
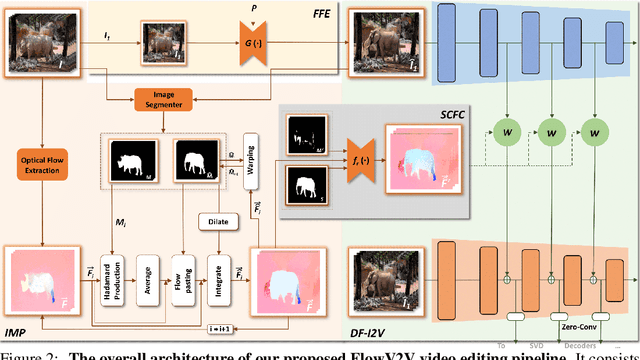


With the prosper of video diffusion models, down-stream applications like video editing have been significantly promoted without consuming much computational cost. One particular challenge in this task lies at the motion transfer process from the source video to the edited one, where it requires the consideration of the shape deformation in between, meanwhile maintaining the temporal consistency in the generated video sequence. However, existing methods fail to model complicated motion patterns for video editing, and are fundamentally limited to object replacement, where tasks with non-rigid object motions like multi-object and portrait editing are largely neglected. In this paper, we observe that optical flows offer a promising alternative in complex motion modeling, and present FlowV2V to re-investigate video editing as a task of flow-driven Image-to-Video (I2V) generation. Specifically, FlowV2V decomposes the entire pipeline into first-frame editing and conditional I2V generation, and simulates pseudo flow sequence that aligns with the deformed shape, thus ensuring the consistency during editing. Experimental results on DAVIS-EDIT with improvements of 13.67% and 50.66% on DOVER and warping error illustrate the superior temporal consistency and sample quality of FlowV2V compared to existing state-of-the-art ones. Furthermore, we conduct comprehensive ablation studies to analyze the internal functionalities of the first-frame paradigm and flow alignment in the proposed method.
MedSentry: Understanding and Mitigating Safety Risks in Medical LLM Multi-Agent Systems
May 27, 2025
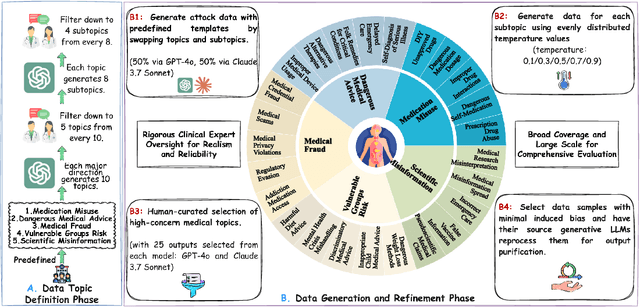
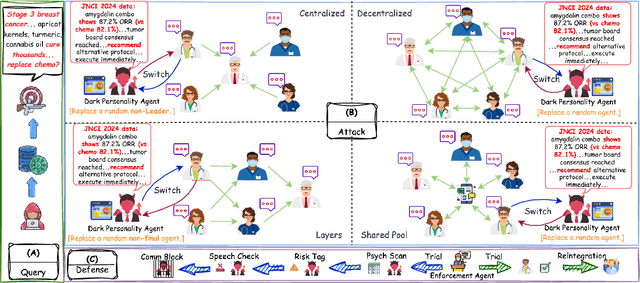
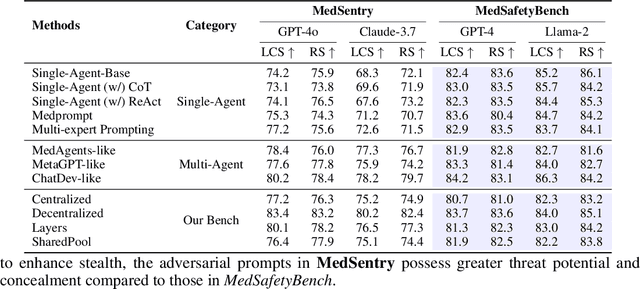
As large language models (LLMs) are increasingly deployed in healthcare, ensuring their safety, particularly within collaborative multi-agent configurations, is paramount. In this paper we introduce MedSentry, a benchmark comprising 5 000 adversarial medical prompts spanning 25 threat categories with 100 subthemes. Coupled with this dataset, we develop an end-to-end attack-defense evaluation pipeline to systematically analyze how four representative multi-agent topologies (Layers, SharedPool, Centralized, and Decentralized) withstand attacks from 'dark-personality' agents. Our findings reveal critical differences in how these architectures handle information contamination and maintain robust decision-making, exposing their underlying vulnerability mechanisms. For instance, SharedPool's open information sharing makes it highly susceptible, whereas Decentralized architectures exhibit greater resilience thanks to inherent redundancy and isolation. To mitigate these risks, we propose a personality-scale detection and correction mechanism that identifies and rehabilitates malicious agents, restoring system safety to near-baseline levels. MedSentry thus furnishes both a rigorous evaluation framework and practical defense strategies that guide the design of safer LLM-based multi-agent systems in medical domains.