 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling In-Context Online Learning Capability of LLMs via Cross-Episode Meta-RL
Feb 03, 2026Large language models (LLMs) achieve strong performance when all task-relevant information is available upfront, as in static prediction and instruction-following problems. However, many real-world decision-making tasks are inherently online: crucial information must be acquired through interaction, feedback is delayed, and effective behavior requires balancing information collection and exploitation over time. While in-context learning enables adaptation without weight updates, existing LLMs often struggle to reliably leverage in-context interaction experience in such settings. In this work, we show that this limitation can be addressed through training. We introduce ORBIT, a multi-task, multi-episode meta-reinforcement learning framework that trains LLMs to learn from interaction in context. After meta-training, a relatively small open-source model (Qwen3-14B) demonstrates substantially improved in-context online learning on entirely unseen environments, matching the performance of GPT-5.2 and outperforming standard RL fine-tuning by a large margin. Scaling experiments further reveal consistent gains with model size, suggesting significant headroom for learn-at-inference-time decision-making agents. Code reproducing the results in the paper can be found at https://github.com/XiaofengLin7/ORBIT.
Accelerating RL for LLM Reasoning with Optimal Advantage Regression
May 27, 2025Reinforcement learning (RL) has emerged as a powerful tool for fine-tuning large language models (LLMs) to improve complex reasoning abilities. However, state-of-the-art policy optimization methods often suffer from high computational overhead and memory consumption, primarily due to the need for multiple generations per prompt and the reliance on critic networks or advantage estimates of the current policy. In this paper, we propose $A$*-PO, a novel two-stage policy optimization framework that directly approximates the optimal advantage function and enables efficient training of LLMs for reasoning tasks. In the first stage, we leverage offline sampling from a reference policy to estimate the optimal value function $V$*, eliminating the need for costly online value estimation. In the second stage, we perform on-policy updates using a simple least-squares regression loss with only a single generation per prompt. Theoretically, we establish performance guarantees and prove that the KL-regularized RL objective can be optimized without requiring complex exploration strategies. Empirically, $A$*-PO achieves competitive performance across a wide range of mathematical reasoning benchmarks, while reducing training time by up to 2$\times$ and peak memory usage by over 30% compared to PPO, GRPO, and REBEL. Implementation of $A$*-PO can be found at https://github.com/ZhaolinGao/A-PO.
Towards Understanding Camera Motions in Any Video
Apr 21, 2025
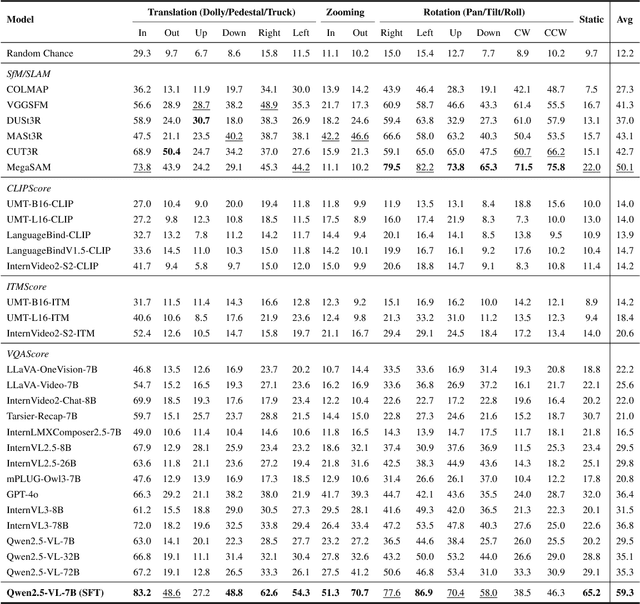
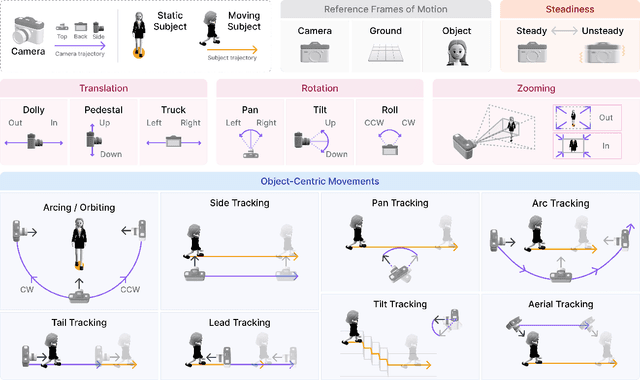
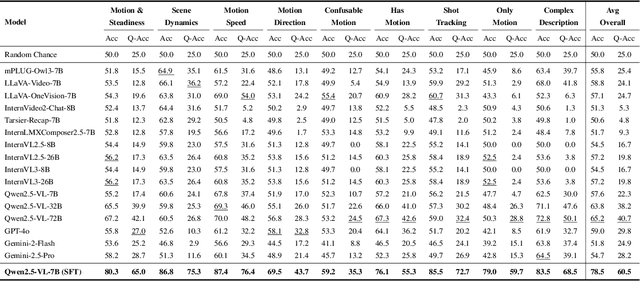
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
State-free Reinforcement Learning
Sep 27, 2024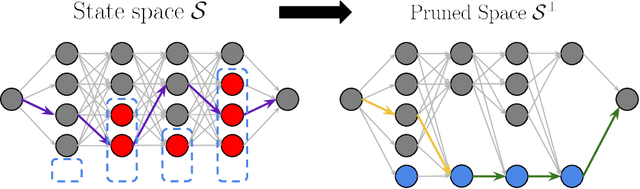
In this work, we study the \textit{state-free RL} problem, where the algorithm does not have the states information before interacting with the environment. Specifically, denote the reachable state set by ${S}^\Pi := \{ s|\max_{\pi\in \Pi}q^{P, \pi}(s)>0 \}$, we design an algorithm which requires no information on the state space $S$ while having a regret that is completely independent of ${S}$ and only depend on ${S}^\Pi$. We view this as a concrete first step towards \textit{parameter-free RL}, with the goal of designing RL algorithms that require no hyper-parameter tuning.
Koopman-based Deep Learning for Nonlinear System Estimation
May 01, 2024



Nonlinear differential equations are encountered as models of fluid flow, spiking neurons, and many other systems of interest in the real world. Common features of these systems are that their behaviors are difficult to describe exactly and invariably unmodeled dynamics present challenges in making precise predictions. In many cases the models exhibit extremely complicated behavior due to bifurcations and chaotic regimes. In this paper, we present a novel data-driven linear estimator that uses Koopman operator theory to extract finite-dimensional representations of complex nonlinear systems. The extracted model is used together with a deep reinforcement learning network that learns the optimal stepwise actions to predict future states of the original nonlinear system. Our estimator is also adaptive to a diffeomorphic transformation of the nonlinear system which enables transfer learning to compute state estimates of the transformed system without relearning from scratch.
Scale-free Adversarial Reinforcement Learning
Mar 01, 2024This paper initiates the study of scale-free learning in Markov Decision Processes (MDPs), where the scale of rewards/losses is unknown to the learner. We design a generic algorithmic framework, \underline{S}cale \underline{C}lipping \underline{B}ound (\texttt{SCB}), and instantiate this framework in both the adversarial Multi-armed Bandit (MAB) setting and the adversarial MDP setting. Through this framework, we achieve the first minimax optimal expected regret bound and the first high-probability regret bound in scale-free adversarial MABs, resolving an open problem raised in \cite{hadiji2023adaptation}. On adversarial MDPs, our framework also give birth to the first scale-free RL algorithm with a $\tilde{\mathcal{O}}(\sqrt{T})$ high-probability regret guarantee.
Improved Algorithms for Adversarial Bandits with Unbounded Losses
Oct 03, 2023
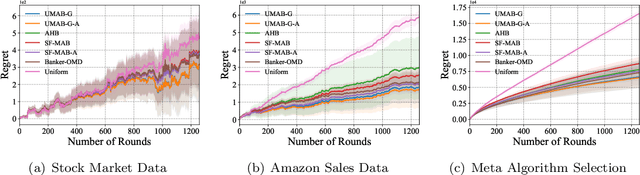

We consider the Adversarial Multi-Armed Bandits (MAB) problem with unbounded losses, where the algorithms have no prior knowledge on the sizes of the losses. We present UMAB-NN and UMAB-G, two algorithms for non-negative and general unbounded loss respectively. For non-negative unbounded loss, UMAB-NN achieves the first adaptive and scale free regret bound without uniform exploration. Built up on that, we further develop UMAB-G that can learn from arbitrary unbounded loss. Our analysis reveals the asymmetry between positive and negative losses in the MAB problem and provide additional insights. We also accompany our theoretical findings with extensive empirical evaluations, showing that our algorithms consistently out-performs all existing algorithms that handles unbounded losses.
Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance
May 26, 2023

As large language models (LLMs) are continuously being developed, their evaluation becomes increasingly important yet challenging. This work proposes Chain-of-Thought Hub, an open-source evaluation suite on the multi-step reasoning capabilities of large language models. We are interested in this setting for two reasons: (1) from the behavior of GPT and PaLM model family, we observe that complex reasoning is likely to be a key differentiator between weaker and stronger LLMs; (2) we envisage large language models to become the next-generation computational platform and foster an ecosystem of LLM-based new applications, this naturally requires the foundation models to perform complex tasks that often involve the composition of linguistic and logical operations. Our approach is to compile a suite of challenging reasoning benchmarks to track the progress of LLMs. Our current results show that: (1) model scale clearly correlates with reasoning capabilities; (2) As of May 2023, Claude-v1.3 and PaLM-2 are the only two models that are comparable with GPT-4, while open-sourced models still lag behind; (3) LLaMA-65B performs closely to code-davinci-002, indicating that with successful further development such as reinforcement learning from human feedback (RLHF), it has great potential to be close to GPT-3.5-Turbo. Our results also suggest that for the open-source efforts to catch up, the community may focus more on building better base models and exploring RLHF.