 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Camera Motions in Any Video
Apr 21, 2025
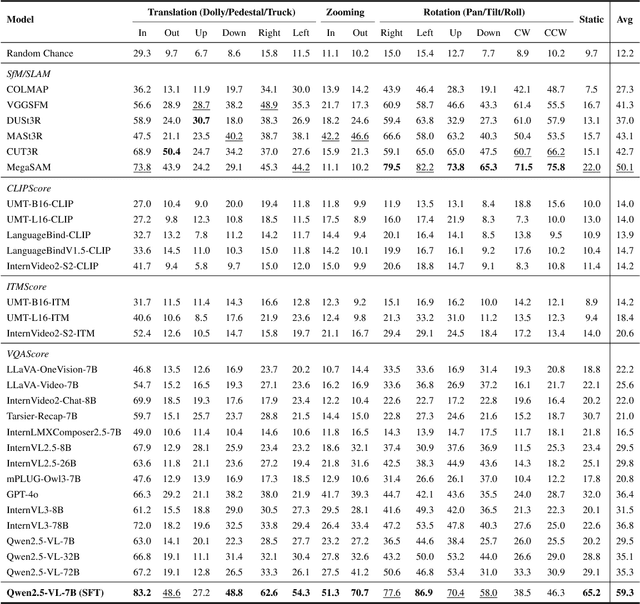
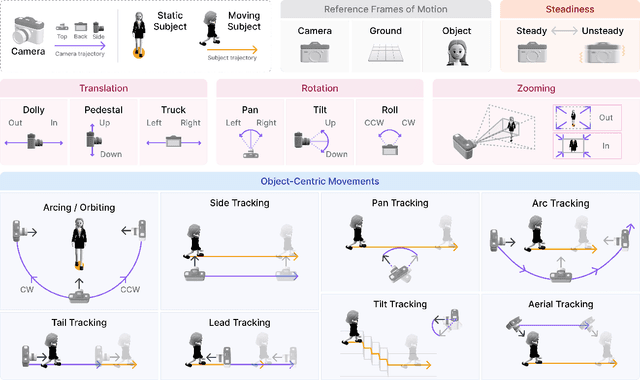
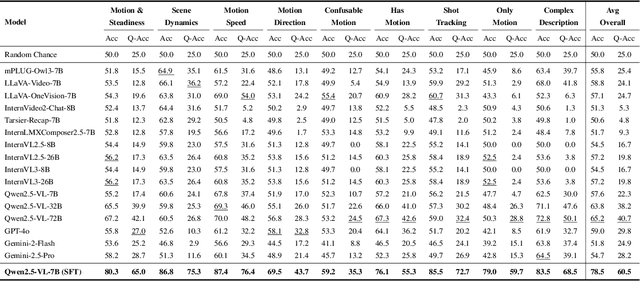
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation
Jun 19, 2024



While text-to-visual models now produce photo-realistic images and videos, they struggle with compositional text prompts involving attributes, relationships, and higher-order reasoning such as logic and comparison. In this work, we conduct an extensive human study on GenAI-Bench to evaluate the performance of leading image and video generation models in various aspects of compositional text-to-visual generation. We also compare automated evaluation metrics against our collected human ratings and find that VQAScore -- a metric measuring the likelihood that a VQA model views an image as accurately depicting the prompt -- significantly outperforms previous metrics such as CLIPScore. In addition, VQAScore can improve generation in a black-box manner (without finetuning) via simply ranking a few (3 to 9) candidate images. Ranking by VQAScore is 2x to 3x more effective than other scoring methods like PickScore, HPSv2, and ImageReward at improving human alignment ratings for DALL-E 3 and Stable Diffusion, especially on compositional prompts that require advanced visio-linguistic reasoning. We will release a new GenAI-Rank benchmark with over 40,000 human ratings to evaluate scoring metrics on ranking images generated from the same prompt. Lastly, we discuss promising areas for improvement in VQAScore, such as addressing fine-grained visual details. We will release all human ratings (over 80,000) to facilitate scientific benchmarking of both generative models and automated metrics.