 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyThermal: Towards Learning Universal Representations for Thermal Perception
Feb 05, 2026We present AnyThermal, a thermal backbone that captures robust task-agnostic thermal features suitable for a variety of tasks such as cross-modal place recognition, thermal segmentation, and monocular depth estimation using thermal images. Existing thermal backbones that follow task-specific training from small-scale data result in utility limited to a specific environment and task. Unlike prior methods, AnyThermal can be used for a wide range of environments (indoor, aerial, off-road, urban) and tasks, all without task-specific training. Our key insight is to distill the feature representations from visual foundation models such as DINOv2 into a thermal encoder using thermal data from these multiple environments. To bridge the diversity gap of the existing RGB-Thermal datasets, we introduce the TartanRGBT platform, the first open-source data collection platform with synced RGB-Thermal image acquisition. We use this payload to collect the TartanRGBT dataset - a diverse and balanced dataset collected in 4 environments. We demonstrate the efficacy of AnyThermal and TartanRGBT, achieving state-of-the-art results with improvements of up to 36% across diverse environments and downstream tasks on existing datasets.
Any4D: Unified Feed-Forward Metric 4D Reconstruction
Dec 11, 2025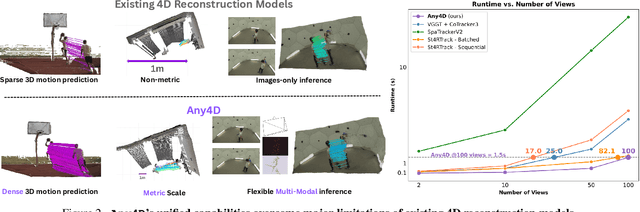
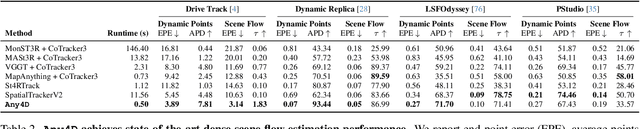
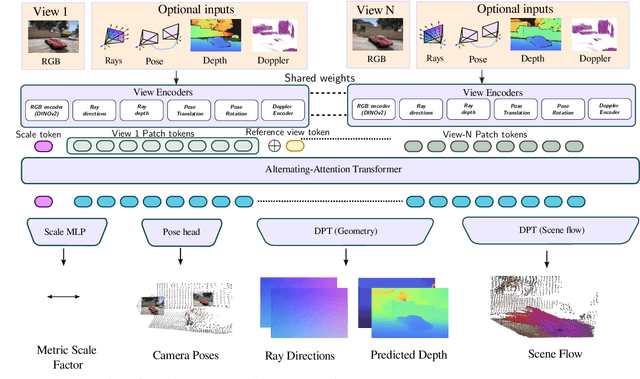
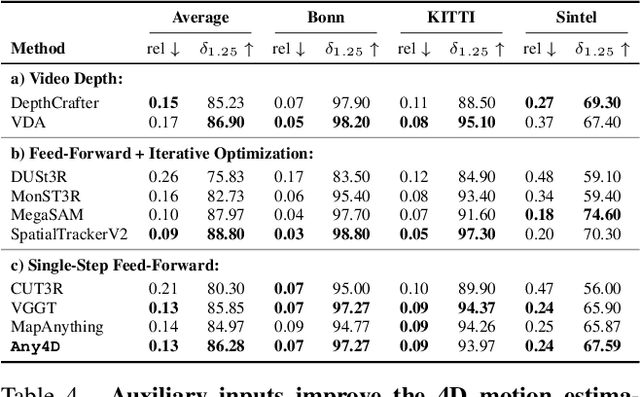
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.
Towards Foundational Models for Single-Chip Radar
Sep 15, 2025mmWave radars are compact, inexpensive, and durable sensors that are robust to occlusions and work regardless of environmental conditions, such as weather and darkness. However, this comes at the cost of poor angular resolution, especially for inexpensive single-chip radars, which are typically used in automotive and indoor sensing applications. Although many have proposed learning-based methods to mitigate this weakness, no standardized foundational models or large datasets for the mmWave radar have emerged, and practitioners have largely trained task-specific models from scratch using relatively small datasets. In this paper, we collect (to our knowledge) the largest available raw radar dataset with 1M samples (29 hours) and train a foundational model for 4D single-chip radar, which can predict 3D occupancy and semantic segmentation with quality that is typically only possible with much higher resolution sensors. We demonstrate that our Generalizable Radar Transformer (GRT) generalizes across diverse settings, can be fine-tuned for different tasks, and shows logarithmic data scaling of 20\% per $10\times$ data. We also run extensive ablations on common design decisions, and find that using raw radar data significantly outperforms widely-used lossy representations, equivalent to a $10\times$ increase in training data. Finally, we roughly estimate that $\approx$100M samples (3000 hours) of data are required to fully exploit the potential of GRT.
UFM: A Simple Path towards Unified Dense Correspondence with Flow
Jun 10, 2025Dense image correspondence is central to many applications, such as visual odometry, 3D reconstruction, object association, and re-identification. Historically, dense correspondence has been tackled separately for wide-baseline scenarios and optical flow estimation, despite the common goal of matching content between two images. In this paper, we develop a Unified Flow & Matching model (UFM), which is trained on unified data for pixels that are co-visible in both source and target images. UFM uses a simple, generic transformer architecture that directly regresses the (u,v) flow. It is easier to train and more accurate for large flows compared to the typical coarse-to-fine cost volumes in prior work. UFM is 28% more accurate than state-of-the-art flow methods (Unimatch), while also having 62% less error and 6.7x faster than dense wide-baseline matchers (RoMa). UFM is the first to demonstrate that unified training can outperform specialized approaches across both domains. This result enables fast, general-purpose correspondence and opens new directions for multi-modal, long-range, and real-time correspondence tasks.
Towards Understanding Camera Motions in Any Video
Apr 21, 2025
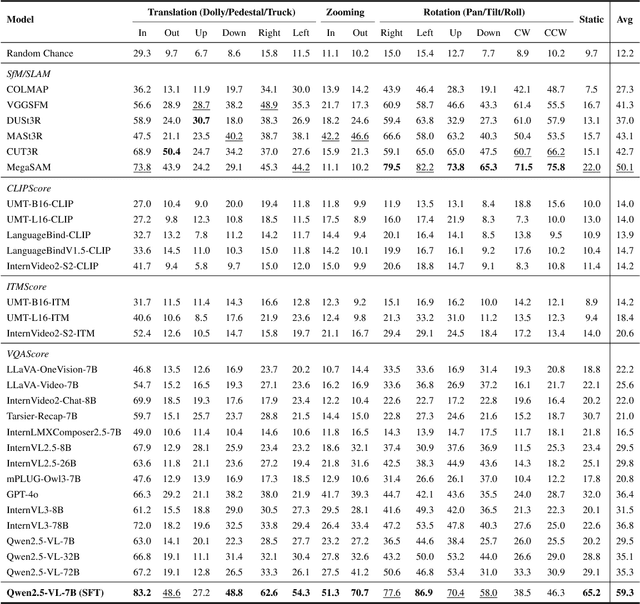
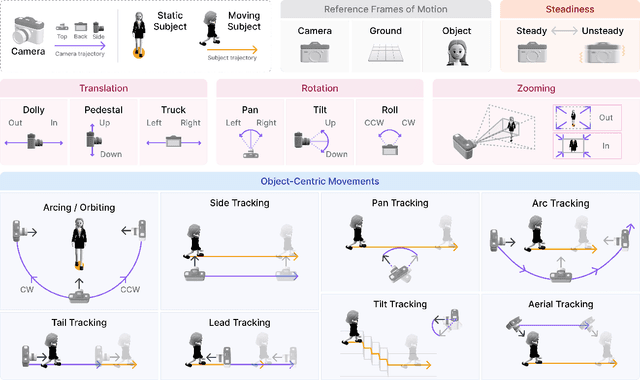
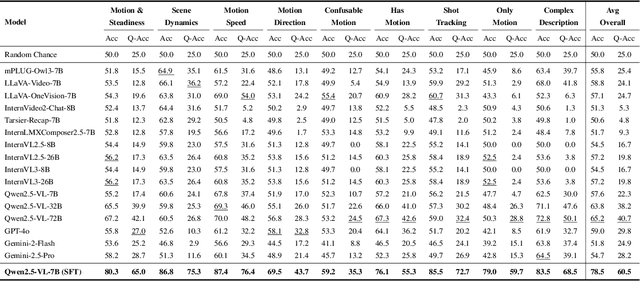
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
Dec 04, 2023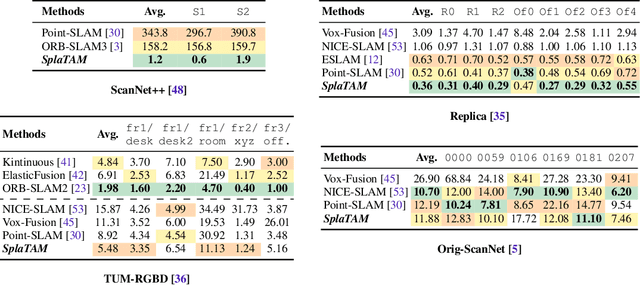
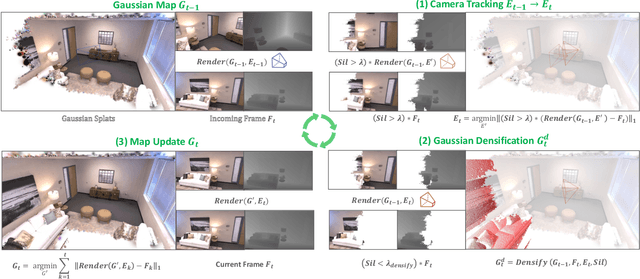
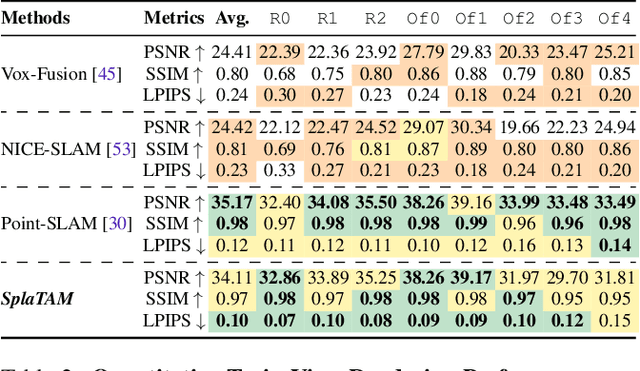

Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by 3D Gaussians can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. We employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments show that SplaTAM achieves up to 2X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches, while allowing real-time rendering of a high-resolution dense 3D map.
SubT-MRS: A Subterranean, Multi-Robot, Multi-Spectral and Multi-Degraded Dataset for Robust SLAM
Aug 02, 2023



In recent years, significant progress has been made in the field of simultaneous localization and mapping (SLAM) research. However, current state-of-the-art solutions still struggle with limited accuracy and robustness in real-world applications. One major reason is the lack of datasets that fully capture the conditions faced by robots in the wild. To address this problem, we present SubT-MRS, an extremely challenging real-world dataset designed to push the limits of SLAM and perception algorithms. SubT-MRS is a multi-modal, multi-robot dataset collected mainly from subterranean environments having multi-degraded conditions including structureless corridors, varying lighting conditions, and perceptual obscurants such as smoke and dust. Furthermore, the dataset packages information from a diverse range of time-synchronized sensors, including LiDAR, visual cameras, thermal cameras, and IMUs captured using varied vehicular motions like aerial, legged, and wheeled, to support research in sensor fusion, which is essential for achieving accurate and robust robotic perception in complex environments. To evaluate the accuracy of SLAM systems, we also provide a dense 3D model with sub-centimeter-level accuracy, as well as accurate 6DoF ground truth. Our benchmarking approach includes several state-of-the-art methods to demonstrate the challenges our datasets introduce, particularly in the case of multi-degraded environments.
AnyLoc: Towards Universal Visual Place Recognition
Aug 01, 2023Visual Place Recognition (VPR) is vital for robot localization. To date, the most performant VPR approaches are environment- and task-specific: while they exhibit strong performance in structured environments (predominantly urban driving), their performance degrades severely in unstructured environments, rendering most approaches brittle to robust real-world deployment. In this work, we develop a universal solution to VPR -- a technique that works across a broad range of structured and unstructured environments (urban, outdoors, indoors, aerial, underwater, and subterranean environments) without any re-training or fine-tuning. We demonstrate that general-purpose feature representations derived from off-the-shelf self-supervised models with no VPR-specific training are the right substrate upon which to build such a universal VPR solution. Combining these derived features with unsupervised feature aggregation enables our suite of methods, AnyLoc, to achieve up to 4X significantly higher performance than existing approaches. We further obtain a 6% improvement in performance by characterizing the semantic properties of these features, uncovering unique domains which encapsulate datasets from similar environments. Our detailed experiments and analysis lay a foundation for building VPR solutions that may be deployed anywhere, anytime, and across anyview. We encourage the readers to explore our project page and interactive demos: https://anyloc.github.io/.
Multi-Frequency-Aware Patch Adversarial Learning for Neural Point Cloud Rendering
Oct 07, 2022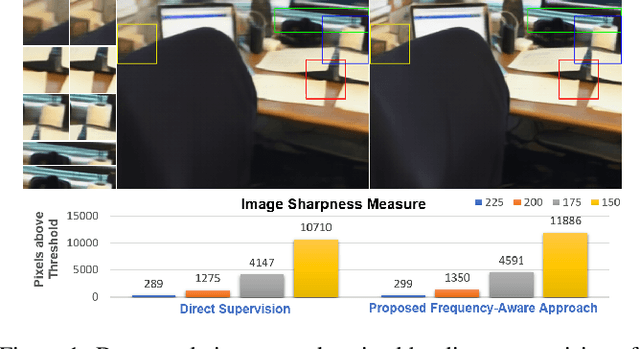
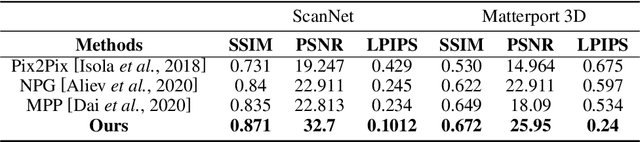
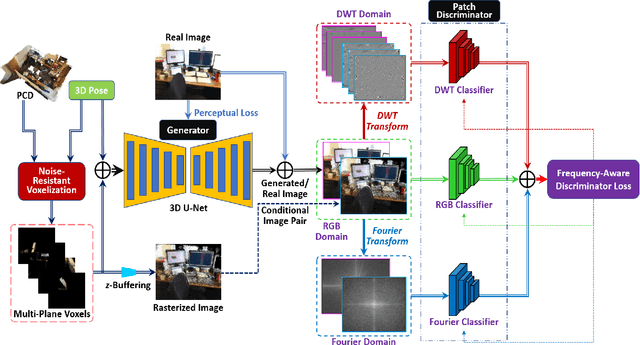
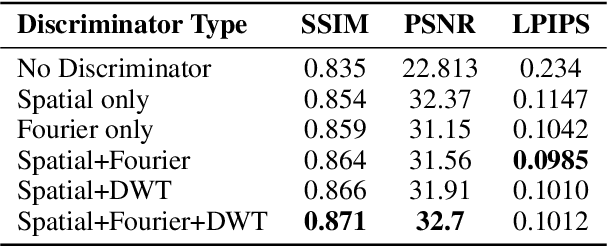
We present a neural point cloud rendering pipeline through a novel multi-frequency-aware patch adversarial learning framework. The proposed approach aims to improve the rendering realness by minimizing the spectrum discrepancy between real and synthesized images, especially on the high-frequency localized sharpness information which causes image blur visually. Specifically, a patch multi-discriminator scheme is proposed for the adversarial learning, which combines both spectral domain (Fourier Transform and Discrete Wavelet Transform) discriminators as well as the spatial (RGB) domain discriminator to force the generator to capture global and local spectral distributions of the real images. The proposed multi-discriminator scheme not only helps to improve rendering realness, but also enhance the convergence speed and stability of adversarial learning. Moreover, we introduce a noise-resistant voxelisation approach by utilizing both the appearance distance and spatial distance to exclude the spatial outlier points caused by depth noise. Our entire architecture is fully differentiable and can be learned in an end-to-end fashion. Extensive experiments show that our method produces state-of-the-art results for neural point cloud rendering by a significant margin. Our source code will be made public at a later date.