 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyNeT: Synthetic Negatives for Traversability Learning
Feb 03, 2026Reliable traversability estimation is crucial for autonomous robots to navigate complex outdoor environments safely. Existing self-supervised learning frameworks primarily rely on positive and unlabeled data; however, the lack of explicit negative data remains a critical limitation, hindering the model's ability to accurately identify diverse non-traversable regions. To address this issue, we introduce a method to explicitly construct synthetic negatives, representing plausible but non-traversable, and integrate them into vision-based traversability learning. Our approach is formulated as a training strategy that can be seamlessly integrated into both Positive-Unlabeled (PU) and Positive-Negative (PN) frameworks without modifying inference architectures. Complementing standard pixel-wise metrics, we introduce an object-centric FPR evaluation approach that analyzes predictions in regions where synthetic negatives are inserted. This evaluation provides an indirect measure of the model's ability to consistently identify non-traversable regions without additional manual labeling. Extensive experiments on both public and self-collected datasets demonstrate that our approach significantly enhances robustness and generalization across diverse environments. The source code and demonstration videos will be publicly available.
UFM: A Simple Path towards Unified Dense Correspondence with Flow
Jun 10, 2025Dense image correspondence is central to many applications, such as visual odometry, 3D reconstruction, object association, and re-identification. Historically, dense correspondence has been tackled separately for wide-baseline scenarios and optical flow estimation, despite the common goal of matching content between two images. In this paper, we develop a Unified Flow & Matching model (UFM), which is trained on unified data for pixels that are co-visible in both source and target images. UFM uses a simple, generic transformer architecture that directly regresses the (u,v) flow. It is easier to train and more accurate for large flows compared to the typical coarse-to-fine cost volumes in prior work. UFM is 28% more accurate than state-of-the-art flow methods (Unimatch), while also having 62% less error and 6.7x faster than dense wide-baseline matchers (RoMa). UFM is the first to demonstrate that unified training can outperform specialized approaches across both domains. This result enables fast, general-purpose correspondence and opens new directions for multi-modal, long-range, and real-time correspondence tasks.
Demonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
May 08, 2025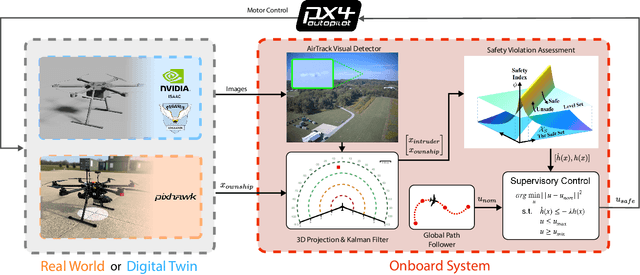
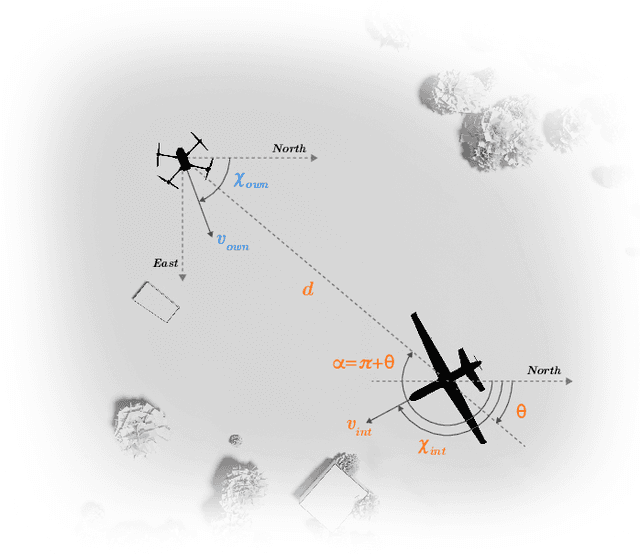

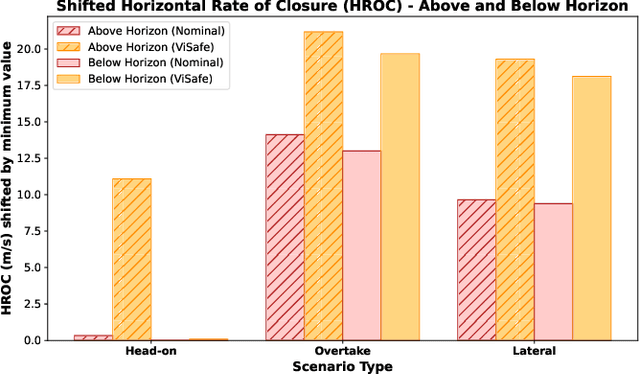
Assured safe-separation is essential for achieving seamless high-density operation of airborne vehicles in a shared airspace. To equip resource-constrained aerial systems with this safety-critical capability, we present ViSafe, a high-speed vision-only airborne collision avoidance system. ViSafe offers a full-stack solution to the Detect and Avoid (DAA) problem by tightly integrating a learning-based edge-AI framework with a custom multi-camera hardware prototype designed under SWaP-C constraints. By leveraging perceptual input-focused control barrier functions (CBF) to design, encode, and enforce safety thresholds, ViSafe can provide provably safe runtime guarantees for self-separation in high-speed aerial operations. We evaluate ViSafe's performance through an extensive test campaign involving both simulated digital twins and real-world flight scenarios. By independently varying agent types, closure rates, interaction geometries, and environmental conditions (e.g., weather and lighting), we demonstrate that ViSafe consistently ensures self-separation across diverse scenarios. In first-of-its-kind real-world high-speed collision avoidance tests with closure rates reaching 144 km/h, ViSafe sets a new benchmark for vision-only autonomous collision avoidance, establishing a new standard for safety in high-speed aerial navigation.
Bundle Adjustment in the Eager Mode
Sep 18, 2024



Bundle adjustment (BA) is a critical technique in various robotic applications, such as simultaneous localization and mapping (SLAM), augmented reality (AR), and photogrammetry. BA optimizes parameters such as camera poses and 3D landmarks to align them with observations. With the growing importance of deep learning in perception systems, there is an increasing need to integrate BA with deep learning frameworks for enhanced reliability and performance. However, widely-used C++-based BA frameworks, such as GTSAM, g$^2$o, and Ceres, lack native integration with modern deep learning libraries like PyTorch. This limitation affects their flexibility, adaptability, ease of debugging, and overall implementation efficiency. To address this gap, we introduce an eager-mode BA framework seamlessly integrated with PyPose, providing PyTorch-compatible interfaces with high efficiency. Our approach includes GPU-accelerated, differentiable, and sparse operations designed for 2nd-order optimization, Lie group and Lie algebra operations, and linear solvers. Our eager-mode BA on GPU demonstrates substantial runtime efficiency, achieving an average speedup of 18.5$\times$, 22$\times$, and 23$\times$ compared to GTSAM, g$^2$o, and Ceres, respectively.
FIReStereo: Forest InfraRed Stereo Dataset for UAS Depth Perception in Visually Degraded Environments
Sep 12, 2024



Robust depth perception in visually-degraded environments is crucial for autonomous aerial systems. Thermal imaging cameras, which capture infrared radiation, are robust to visual degradation. However, due to lack of a large-scale dataset, the use of thermal cameras for unmanned aerial system (UAS) depth perception has remained largely unexplored. This paper presents a stereo thermal depth perception dataset for autonomous aerial perception applications. The dataset consists of stereo thermal images, LiDAR, IMU and ground truth depth maps captured in urban and forest settings under diverse conditions like day, night, rain, and smoke. We benchmark representative stereo depth estimation algorithms, offering insights into their performance in degraded conditions. Models trained on our dataset generalize well to unseen smoky conditions, highlighting the robustness of stereo thermal imaging for depth perception. We aim for this work to enhance robotic perception in disaster scenarios, allowing for exploration and operations in previously unreachable areas. The dataset and source code are available at https://firestereo.github.io.
Geometry-Informed Distance Candidate Selection for Adaptive Lightweight Omnidirectional Stereo Vision with Fisheye Images
May 08, 2024Multi-view stereo omnidirectional distance estimation usually needs to build a cost volume with many hypothetical distance candidates. The cost volume building process is often computationally heavy considering the limited resources a mobile robot has. We propose a new geometry-informed way of distance candidates selection method which enables the use of a very small number of candidates and reduces the computational cost. We demonstrate the use of the geometry-informed candidates in a set of model variants. We find that by adjusting the candidates during robot deployment, our geometry-informed distance candidates also improve a pre-trained model's accuracy if the extrinsics or the number of cameras changes. Without any re-training or fine-tuning, our models outperform models trained with evenly distributed distance candidates. Models are also released as hardware-accelerated versions with a new dedicated large-scale dataset. The project page, code, and dataset can be found at https://theairlab.org/gicandidates/ .
FoundLoc: Vision-based Onboard Aerial Localization in the Wild
Oct 25, 2023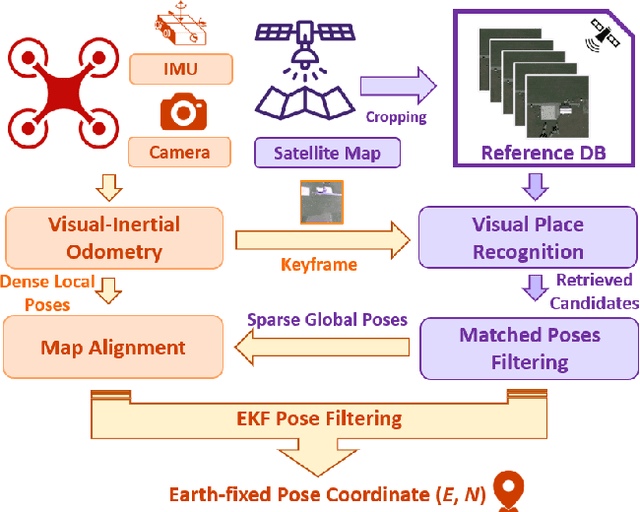
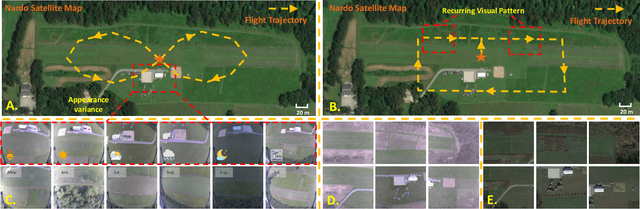

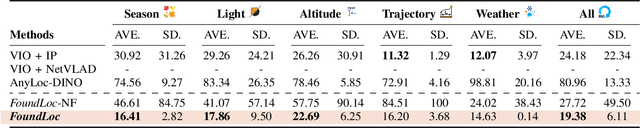
Robust and accurate localization for Unmanned Aerial Vehicles (UAVs) is an essential capability to achieve autonomous, long-range flights. Current methods either rely heavily on GNSS, face limitations in visual-based localization due to appearance variances and stylistic dissimilarities between camera and reference imagery, or operate under the assumption of a known initial pose. In this paper, we developed a GNSS-denied localization approach for UAVs that harnesses both Visual-Inertial Odometry (VIO) and Visual Place Recognition (VPR) using a foundation model. This paper presents a novel vision-based pipeline that works exclusively with a nadir-facing camera, an Inertial Measurement Unit (IMU), and pre-existing satellite imagery for robust, accurate localization in varied environments and conditions. Our system demonstrated average localization accuracy within a $20$-meter range, with a minimum error below $1$ meter, under real-world conditions marked by drastic changes in environmental appearance and with no assumption of the vehicle's initial pose. The method is proven to be effective and robust, addressing the crucial need for reliable UAV localization in GNSS-denied environments, while also being computationally efficient enough to be deployed on resource-constrained platforms.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
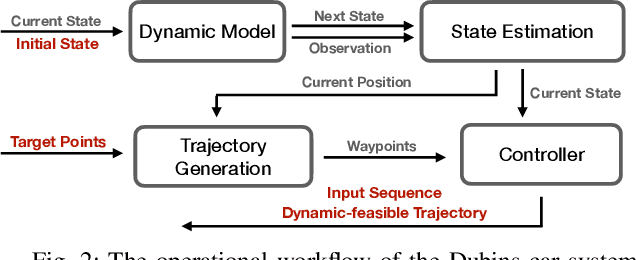
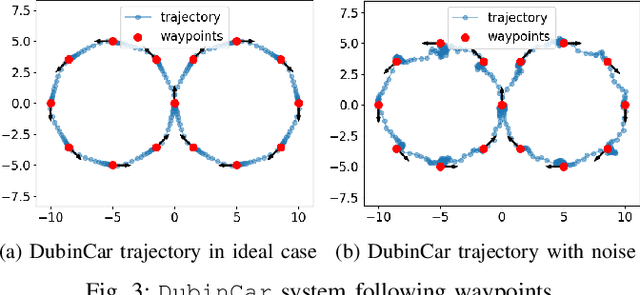
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
VoxDet: Voxel Learning for Novel Instance Detection
Jun 04, 2023Detecting unseen instances based on multi-view templates is a challenging problem due to its open-world nature. Traditional methodologies, which primarily rely on 2D representations and matching techniques, are often inadequate in handling pose variations and occlusions. To solve this, we introduce VoxDet, a pioneer 3D geometry-aware framework that fully utilizes the strong 3D voxel representation and reliable voxel matching mechanism. VoxDet first ingeniously proposes template voxel aggregation (TVA) module, effectively transforming multi-view 2D images into 3D voxel features. By leveraging associated camera poses, these features are aggregated into a compact 3D template voxel. In novel instance detection, this voxel representation demonstrates heightened resilience to occlusion and pose variations. We also discover that a 3D reconstruction objective helps to pre-train the 2D-3D mapping in TVA. Second, to quickly align with the template voxel, VoxDet incorporates a Query Voxel Matching (QVM) module. The 2D queries are first converted into their voxel representation with the learned 2D-3D mapping. We find that since the 3D voxel representations encode the geometry, we can first estimate the relative rotation and then compare the aligned voxels, leading to improved accuracy and efficiency. Exhaustive experiments are conducted on the demanding LineMod-Occlusion, YCB-video, and the newly built RoboTools benchmarks, where VoxDet outperforms various 2D baselines remarkably with 20% higher recall and faster speed. To the best of our knowledge, VoxDet is the first to incorporate implicit 3D knowledge for 2D detection tasks.
TartanCalib: Iterative Wide-Angle Lens Calibration using Adaptive SubPixel Refinement of AprilTags
Oct 05, 2022
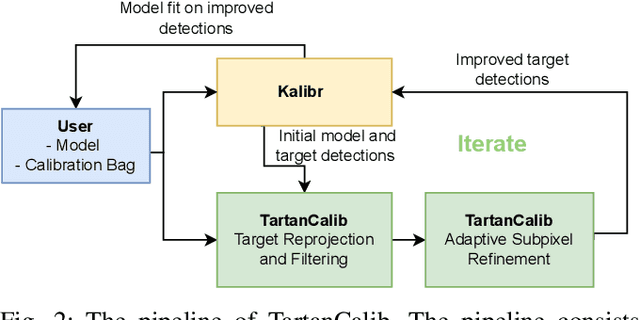

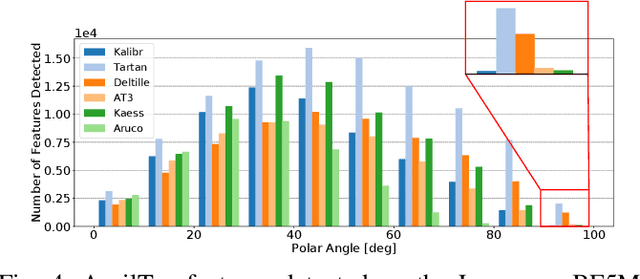
Wide-angle cameras are uniquely positioned for mobile robots, by virtue of the rich information they provide in a small, light, and cost-effective form factor. An accurate calibration of the intrinsics and extrinsics is a critical pre-requisite for using the edge of a wide-angle lens for depth perception and odometry. Calibrating wide-angle lenses with current state-of-the-art techniques yields poor results due to extreme distortion at the edge, as most algorithms assume a lens with low to medium distortion closer to a pinhole projection. In this work we present our methodology for accurate wide-angle calibration. Our pipeline generates an intermediate model, and leverages it to iteratively improve feature detection and eventually the camera parameters. We test three key methods to utilize intermediate camera models: (1) undistorting the image into virtual pinhole cameras, (2) reprojecting the target into the image frame, and (3) adaptive subpixel refinement. Combining adaptive subpixel refinement and feature reprojection significantly improves reprojection errors by up to 26.59 %, helps us detect up to 42.01 % more features, and improves performance in the downstream task of dense depth mapping. Finally, TartanCalib is open-source and implemented into an easy-to-use calibration toolbox. We also provide a translation layer with other state-of-the-art works, which allows for regressing generic models with thousands of parameters or using a more robust solver. To this end, TartanCalib is the tool of choice for wide-angle calibration. Project website and code: http://tartancalib.com.