 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEVO: Memory-Efficient Monocular Visual Odometry Using Gaussians
Sep 14, 2024Constructing a high-fidelity representation of the 3D scene using a monocular camera can enable a wide range of applications on mobile devices, such as micro-robots, smartphones, and AR/VR headsets. On these devices, memory is often limited in capacity and its access often dominates the consumption of compute energy. Although Gaussian Splatting (GS) allows for high-fidelity reconstruction of 3D scenes, current GS-based SLAM is not memory efficient as a large number of past images is stored to retrain Gaussians for reducing catastrophic forgetting. These images often require two-orders-of-magnitude higher memory than the map itself and thus dominate the total memory usage. In this work, we present GEVO, a GS-based monocular SLAM framework that achieves comparable fidelity as prior methods by rendering (instead of storing) them from the existing map. Novel Gaussian initialization and optimization techniques are proposed to remove artifacts from the map and delay the degradation of the rendered images over time. Across a variety of environments, GEVO achieves comparable map fidelity while reducing the memory overhead to around 58 MBs, which is up to 94x lower than prior works.
iMatching: Imperative Correspondence Learning
Dec 04, 2023Learning feature correspondence is a foundational task in computer vision, holding immense importance for downstream applications such as visual odometry and 3D reconstruction. Despite recent progress in data-driven models, feature correspondence learning is still limited by the lack of accurate per-pixel correspondence labels. To overcome this difficulty, we introduce a new self-supervised scheme, imperative learning (IL), for training feature correspondence. It enables correspondence learning on arbitrary uninterrupted videos without any camera pose or depth labels, heralding a new era for self-supervised correspondence learning. Specifically, we formulated the problem of correspondence learning as a bilevel optimization, which takes the reprojection error from bundle adjustment as a supervisory signal for the model. To avoid large memory and computation overhead, we leverage the stationary point to effectively back-propagate the implicit gradients through bundle adjustment. Through extensive experiments, we demonstrate superior performance on tasks including feature matching and pose estimation, in which we obtained an average of 30% accuracy gain over the state-of-the-art matching models.
PyPose: A Library for Robot Learning with Physics-based Optimization
Sep 30, 2022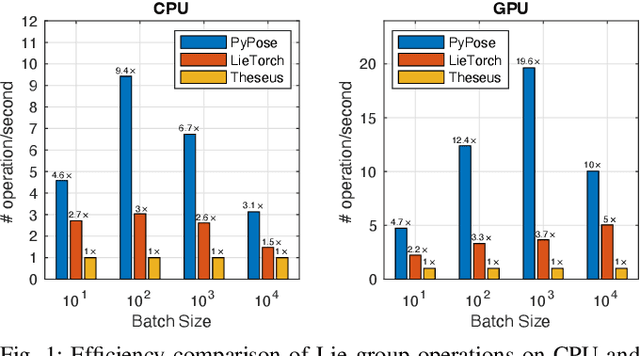
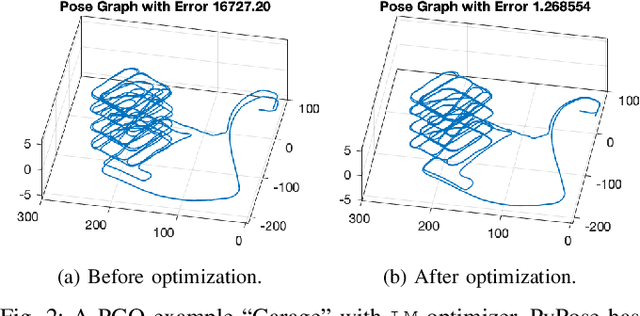
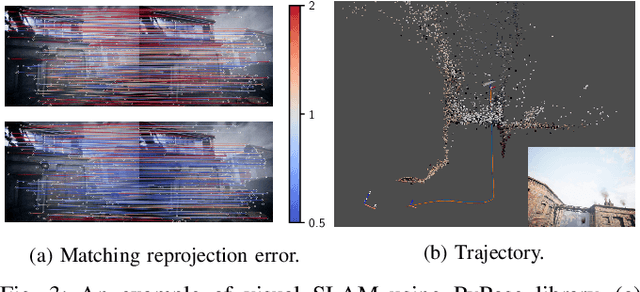
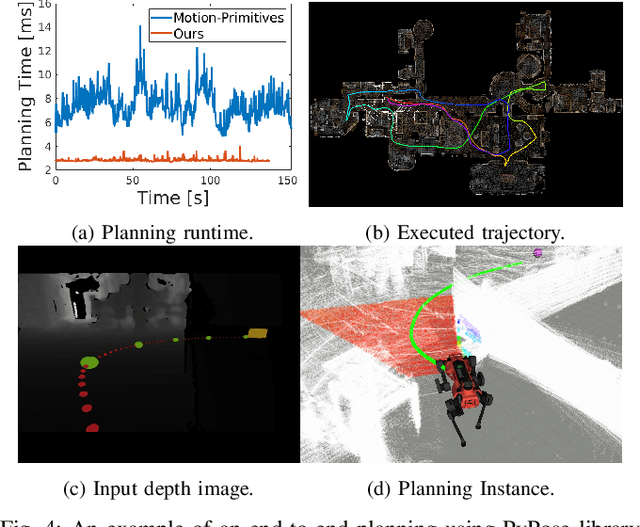
Deep learning has had remarkable success in robotic perception, but its data-centric nature suffers when it comes to generalizing to ever-changing environments. By contrast, physics-based optimization generalizes better, but it does not perform as well in complicated tasks due to the lack of high-level semantic information and the reliance on manual parametric tuning. To take advantage of these two complementary worlds, we present PyPose: a robotics-oriented, PyTorch-based library that combines deep perceptual models with physics-based optimization techniques. Our design goal for PyPose is to make it user-friendly, efficient, and interpretable with a tidy and well-organized architecture. Using an imperative style interface, it can be easily integrated into real-world robotic applications. Besides, it supports parallel computing of any order gradients of Lie groups and Lie algebras and $2^{\text{nd}}$-order optimizers, such as trust region methods. Experiments show that PyPose achieves 3-20$\times$ speedup in computation compared to state-of-the-art libraries. To boost future research, we provide concrete examples across several fields of robotics, including SLAM, inertial navigation, planning, and control.
AirLoop: Lifelong Loop Closure Detection
Sep 18, 2021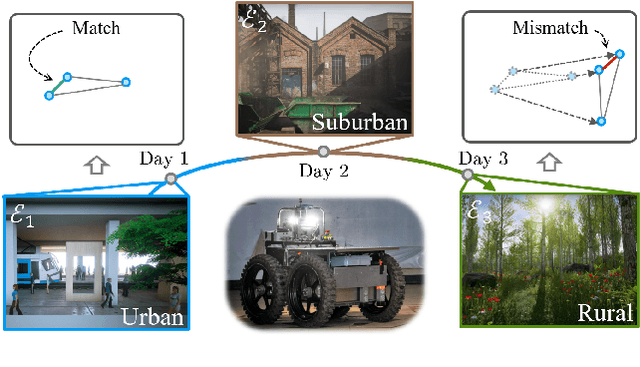
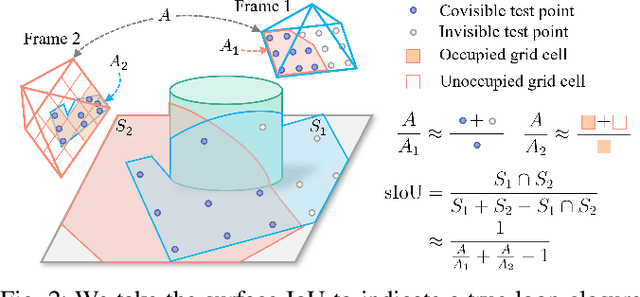

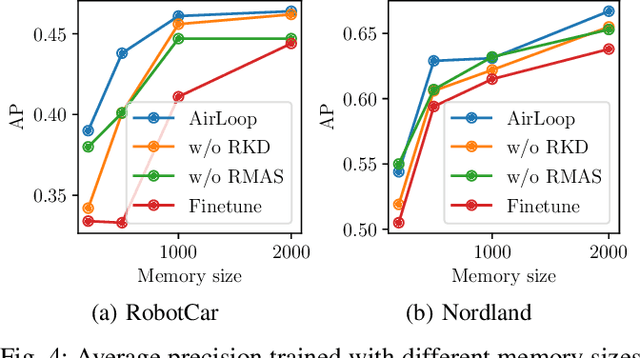
Loop closure detection is an important building block that ensures the accuracy and robustness of simultaneous localization and mapping (SLAM) systems. Due to their generalization ability, CNN-based approaches have received increasing attention. Although they normally benefit from training on datasets that are diverse and reflective of the environments, new environments often emerge after the model is deployed. It is therefore desirable to incorporate the data newly collected during operation for incremental learning. Nevertheless, simply finetuning the model on new data is infeasible since it may cause the model's performance on previously learned data to degrade over time, which is also known as the problem of catastrophic forgetting. In this paper, we present AirLoop, a method that leverages techniques from lifelong learning to minimize forgetting when training loop closure detection models incrementally. We experimentally demonstrate the effectiveness of AirLoop on TartanAir, Nordland, and RobotCar datasets. To the best of our knowledge, AirLoop is one of the first works to achieve lifelong learning of deep loop closure detectors.