 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
A Deployable Embodied Vision-Language Navigation System with Hierarchical Cognition and Context-Aware Exploration
Apr 23, 2026Bridging the gap between embodied intelligence and embedded deployment remains a key challenge in intelligent robotic systems, where perception, reasoning, and planning must operate under strict constraints on computation, memory, energy, and real-time execution. In vision-language navigation (VLN), existing approaches often face a fundamental trade-off between strong reasoning capabilities and efficient deployment on real-world platforms. In this paper, we present a deployable embodied VLN system that achieves both high efficiency and robust high-level reasoning on real-world robotic platforms. To achieve this, we decouple the system into three asynchronous modules: a real-time perception module for continuous environment sensing, a memory integration module for spatial-semantic aggregation, and a reasoning module for high-level decision making. We incrementally construct a cognitive memory graph to encode scene information, which is further decomposed into subgraphs to enable reasoning with a vision-language model (VLM). To further improve navigation efficiency and accuracy, we also leverage the cognitive memory graph to formulate the exploration problem as a context-aware Weighted Traveling Repairman Problem (WTRP), which minimizes the weighted waiting time of viewpoints. Extensive experiments in both simulation and real-world robotic platforms demonstrate improved navigation success and efficiency over existing VLN approaches, while maintaining real-time performance on resource-constrained hardware.
Beyond Imitation: Reinforcement Learning Fine-Tuning for Adaptive Diffusion Navigation Policies
Mar 13, 2026Diffusion-based robot navigation policies trained on large-scale imitation learning datasets, can generate multi-modal trajectories directly from the robot's visual observations, bypassing the traditional localization-mapping-planning pipeline and achieving strong zero-shot generalization. However, their performance remains constrained by the coverage of offline datasets, and when deployed in unseen settings, distribution shift often leads to accumulated trajectory errors and safety-critical failures. Adapting diffusion policies with reinforcement learning is challenging because their iterative denoising structure hinders effective gradient backpropagation, while also making the training of an additional value network computationally expensive and less stable. To address these issues, we propose a reinforcement learning fine-tuning framework tailored for diffusion-based navigation. The method leverages the inherent multi-trajectory sampling mechanism of diffusion models and adopts Group Relative Policy Optimization (GRPO), which estimates relative advantages across sampled trajectories without requiring a separate value network. To preserve pretrained representations while enabling adaptation, we freeze the visual encoder and selectively update the higher decoder layers and action head, enhancing safety-aware behaviors through online environmental feedback. On the PointGoal task in Isaac Sim, our approach improves the Success Rate from 52.0% to 58.7% and SPL from 0.49 to 0.54 on unseen scenes, while reducing collision frequency. Additional experiments show that the fine-tuned policy transfers zero-shot to a real quadruped platform and maintains stable performance in geometrically out-of-distribution environments, suggesting improved adaptability and safe generalization to new domains.
LST-SLAM: A Stereo Thermal SLAM System for Kilometer-Scale Dynamic Environments
Feb 24, 2026Thermal cameras offer strong potential for robot perception under challenging illumination and weather conditions. However, thermal Simultaneous Localization and Mapping (SLAM) remains difficult due to unreliable feature extraction, unstable motion tracking, and inconsistent global pose and map construction, particularly in dynamic large-scale outdoor environments. To address these challenges, we propose LST-SLAM, a novel large-scale stereo thermal SLAM system that achieves robust performance in complex, dynamic scenes. Our approach combines self-supervised thermal feature learning, stereo dual-level motion tracking, and geometric pose optimization. We also introduce a semantic-geometric hybrid constraint that suppresses potentially dynamic features lacking strong inter-frame geometric consistency. Furthermore, we develop an online incremental bag-of-words model for loop closure detection, coupled with global pose optimization to mitigate accumulated drift. Extensive experiments on kilometer-scale dynamic thermal datasets show that LST-SLAM significantly outperforms recent representative SLAM systems, including AirSLAM and DROID-SLAM, in both robustness and accuracy.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Learning to Search for Vehicle Routing with Multiple Time Windows
May 29, 2025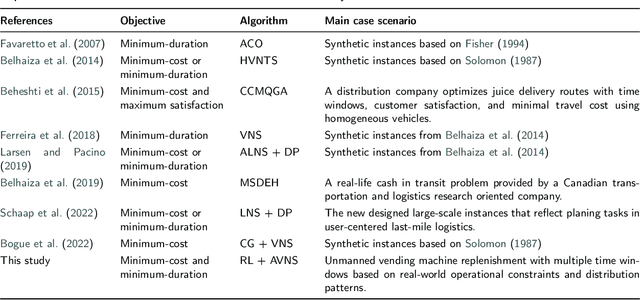

In this study, we propose a reinforcement learning-based adaptive variable neighborhood search (RL-AVNS) method designed for effectively solving the Vehicle Routing Problem with Multiple Time Windows (VRPMTW). Unlike traditional adaptive approaches that rely solely on historical operator performance, our method integrates a reinforcement learning framework to dynamically select neighborhood operators based on real-time solution states and learned experience. We introduce a fitness metric that quantifies customers' temporal flexibility to improve the shaking phase, and employ a transformer-based neural policy network to intelligently guide operator selection during the local search. Extensive computational experiments are conducted on realistic scenarios derived from the replenishment of unmanned vending machines, characterized by multiple clustered replenishment windows. Results demonstrate that RL-AVNS significantly outperforms traditional variable neighborhood search (VNS), adaptive VNS (AVNS), and state-of-the-art learning-based heuristics, achieving substantial improvements in solution quality and computational efficiency across various instance scales and time window complexities. Particularly notable is the algorithm's capability to generalize effectively to problem instances not encountered during training, underscoring its practical utility for complex logistics scenarios.
AirSwarm: Enabling Cost-Effective Multi-UAV Research with COTS drones
Mar 10, 2025Traditional unmanned aerial vehicle (UAV) swarm missions rely heavily on expensive custom-made drones with onboard perception or external positioning systems, limiting their widespread adoption in research and education. To address this issue, we propose AirSwarm. AirSwarm democratizes multi-drone coordination using low-cost commercially available drones such as Tello or Anafi, enabling affordable swarm aerial robotics research and education. Key innovations include a hierarchical control architecture for reliable multi-UAV coordination, an infrastructure-free visual SLAM system for precise localization without external motion capture, and a ROS-based software framework for simplified swarm development. Experiments demonstrate cm-level tracking accuracy, low-latency control, communication failure resistance, formation flight, and trajectory tracking. By reducing financial and technical barriers, AirSwarm makes multi-robot education and research more accessible. The complete instructions and open source code will be available at
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
ChorusCVR: Chorus Supervision for Entire Space Post-Click Conversion Rate Modeling
Feb 12, 2025



Post-click conversion rate (CVR) estimation is a vital task in many recommender systems of revenue businesses, e.g., e-commerce and advertising. In a perspective of sample, a typical CVR positive sample usually goes through a funnel of exposure to click to conversion. For lack of post-event labels for un-clicked samples, CVR learning task commonly only utilizes clicked samples, rather than all exposed samples as for click-through rate (CTR) learning task. However, during online inference, CVR and CTR are estimated on the same assumed exposure space, which leads to a inconsistency of sample space between training and inference, i.e., sample selection bias (SSB). To alleviate SSB, previous wisdom proposes to design novel auxiliary tasks to enable the CVR learning on un-click training samples, such as CTCVR and counterfactual CVR, etc. Although alleviating SSB to some extent, none of them pay attention to the discrimination between ambiguous negative samples (un-clicked) and factual negative samples (clicked but un-converted) during modelling, which makes CVR model lacks robustness. To full this gap, we propose a novel ChorusCVR model to realize debiased CVR learning in entire-space.