 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
SuperValid: Capability-Aligned OOD Validation for Generalizable Downstream Scaling
May 27, 2026Scaling laws guide large language model training by relating compute to cross-entropy loss, and recent work further extends them to predict downstream benchmark performance. However, prior approaches face generalization limitations from two aspects: focusing on benchmark-level performance introduces scenario-specific artifacts, while relying on IID validation loss fails to track capability improvements when training distributions vary. In this work, we argue that downstream scaling should be studied at the capability level, which captures shared skill factors across related tasks while abstracting away benchmark-specific noise. We propose SuperValid, a framework that synthesizes OOD (out-of-distribution), capability-aligned validation data by distilling core concepts from benchmarks within a capability domain and expanding them into diverse, knowledge-rich texts. Extensive experiments spanning 17 benchmarks grouped into 6 capability domains show that SuperValid loss exhibits strong and stable correlation with downstream performance across models of different architectures, scales, and training data distributions. As a training-free metric computable during training without benchmark evaluation, SuperValid enables effective model selection, early stopping, and scaling decisions.
HapticLDM: A Diffusion Model for Text-to-Vibrotactile Generation
May 11, 2026Text-to-vibration generation converts natural language into haptic feedback, enabling vibration-effect designers to get scenarios-fitted vibrations more efficiently, which shows great potentials in application fields such as metaverse, games, and film to enrich the user experience in interactive scenarios. The core challenge in this field is how to generate accurate, consistent, and complete vibrations according to textual semantics. Very recent autoregressive (AR) approaches (e.g., HapticGen) exhibit limited capacity in fully capturing global dependencies, owing to the inherent sequential nature of their modeling and prevailing data constraints. In this paper, we proposed HapticLDM, the first text-to-vibration generative model built upon Latent Diffusion Models (LDMs). Firstly, with respect to the data, we introduced a text-processing strategy that emphasizes dynamic characteristics to curate high-quality data pairs for fine-grained dynamic modeling. Secondly, HapticLDM incorporates a global denoising mechanism that regulates coherent and stable variations in the temporal envelope. Furthermore, we conduct extensive evaluations, including A/B testing against the state-of-the-art baseline and a user study involving 30 participants. The results demonstrate that our model enhances realism and semantic alignment. Qualitative feedback further indicates that HapticLDM simplifies the haptic design workflow while generating diverse, subtle, and physically precise vibrations.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
SHARP: Synthesizing High-quality Aligned Reasoning Problems for Large Reasoning Models Reinforcement Learning
May 21, 2025Training large reasoning models (LRMs) with reinforcement learning in STEM domains is hindered by the scarcity of high-quality, diverse, and verifiable problem sets. Existing synthesis methods, such as Chain-of-Thought prompting, often generate oversimplified or uncheckable data, limiting model advancement on complex tasks. To address these challenges, we introduce SHARP, a unified approach to Synthesizing High-quality Aligned Reasoning Problems for LRMs reinforcement learning with verifiable rewards (RLVR). SHARP encompasses a strategic set of self-alignment principles -- targeting graduate and Olympiad-level difficulty, rigorous logical consistency, and unambiguous, verifiable answers -- and a structured three-phase framework (Alignment, Instantiation, Inference) that ensures thematic diversity and fine-grained control over problem generation. We implement SHARP by leveraging a state-of-the-art LRM to infer and verify challenging STEM questions, then employ a reinforcement learning loop to refine the model's reasoning through verifiable reward signals. Experiments on benchmarks such as GPQA demonstrate that SHARP-augmented training substantially outperforms existing methods, markedly improving complex reasoning accuracy and pushing LRM performance closer to expert-level proficiency. Our contributions include the SHARP strategy, framework design, end-to-end implementation, and experimental evaluation of its effectiveness in elevating LRM reasoning capabilities.
Video sentence grounding with temporally global textual knowledge
Apr 21, 2024Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-based Optimization
Aug 24, 2021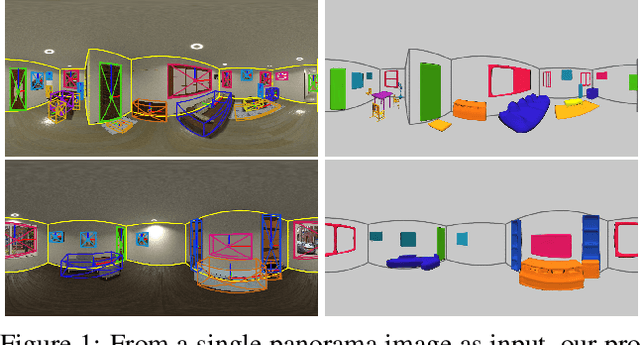

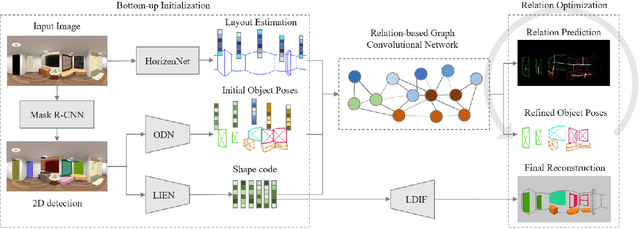

Panorama images have a much larger field-of-view thus naturally encode enriched scene context information compared to standard perspective images, which however is not well exploited in the previous scene understanding methods. In this paper, we propose a novel method for panoramic 3D scene understanding which recovers the 3D room layout and the shape, pose, position, and semantic category for each object from a single full-view panorama image. In order to fully utilize the rich context information, we design a novel graph neural network based context model to predict the relationship among objects and room layout, and a differentiable relationship-based optimization module to optimize object arrangement with well-designed objective functions on-the-fly. Realizing the existing data are either with incomplete ground truth or overly-simplified scene, we present a new synthetic dataset with good diversity in room layout and furniture placement, and realistic image quality for total panoramic 3D scene understanding. Experiments demonstrate that our method outperforms existing methods on panoramic scene understanding in terms of both geometry accuracy and object arrangement. Code is available at https://chengzhag.github.io/publication/dpc.
SlimConv: Reducing Channel Redundancy in Convolutional Neural Networks by Weights Flipping
Mar 16, 2020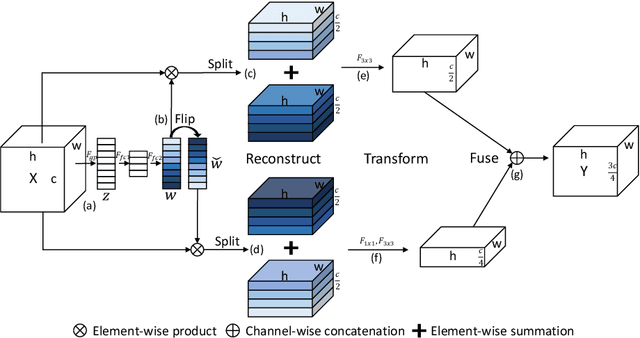
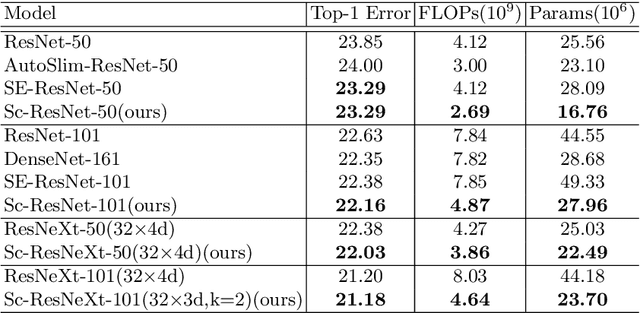
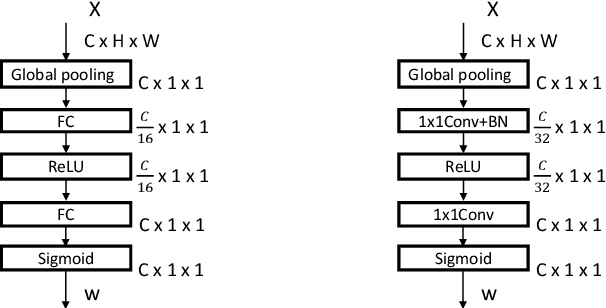
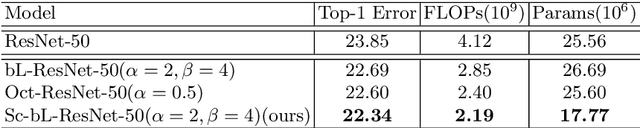
The channel redundancy in feature maps of convolutional neural networks (CNNs) results in the large consumption of memories and computational resources. In this work, we design a novel Slim Convolution (SlimConv) module to boost the performance of CNNs by reducing channel redundancies. Our SlimConv consists of three main steps: Reconstruct, Transform and Fuse, through which the features are splitted and reorganized in a more efficient way, such that the learned weights can be compressed effectively. In particular, the core of our model is a weight flipping operation which can largely improve the feature diversities, contributing to the performance crucially. Our SlimConv is a plug-and-play architectural unit which can be used to replace convolutional layers in CNNs directly. We validate the effectiveness of SlimConv by conducting comprehensive experiments on ImageNet, MS COCO2014, Pascal VOC2012 segmentation, and Pascal VOC2007 detection datasets. The experiments show that SlimConv-equipped models can achieve better performances consistently, less consumption of memory and computation resources than non-equipped conterparts. For example, the ResNet-101 fitted with SlimConv achieves 77.84% top-1 classification accuracy with 4.87 GFLOPs and 27.96M parameters on ImageNet, which shows almost 0.5% better performance with about 3 GFLOPs and 38% parameters reduced.