 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing the Complexity of Matrix Multiplication to $O(N^2log_2N)$ by an Asymptotically Optimal Quantum Algorithm
Feb 05, 2026Matrix multiplication is a fundamental classical computing operation whose efficiency becomes a major challenge at scale, especially for machine learning applications. Quantum computing, with its inherent parallelism and exponential storage capacity, offers a potential solution to these limitations. This work presents a quantum kernel-based matrix multiplication algorithm (QKMM) that achieves an asymptotically optimal computational complexity of $ O(N^2 \log_2 N) $, outperforming the classical optimal complexity of $ O(N^{2.371552}) $, where $N$ denotes the matrix dimension. Through noiseless and noisy quantum simulation experiments, we demonstrate that the proposed algorithm not only exhibits superior theoretical efficiency but also shows practical advantages in runtime performance and stability.
Improving Flexible Image Tokenizers for Autoregressive Image Generation
Jan 04, 2026Flexible image tokenizers aim to represent an image using an ordered 1D variable-length token sequence. This flexible tokenization is typically achieved through nested dropout, where a portion of trailing tokens is randomly truncated during training, and the image is reconstructed using the remaining preceding sequence. However, this tail-truncation strategy inherently concentrates the image information in the early tokens, limiting the effectiveness of downstream AutoRegressive (AR) image generation as the token length increases. To overcome these limitations, we propose \textbf{ReToK}, a flexible tokenizer with \underline{Re}dundant \underline{Tok}en Padding and Hierarchical Semantic Regularization, designed to fully exploit all tokens for enhanced latent modeling. Specifically, we introduce \textbf{Redundant Token Padding} to activate tail tokens more frequently, thereby alleviating information over-concentration in the early tokens. In addition, we apply \textbf{Hierarchical Semantic Regularization} to align the decoding features of earlier tokens with those from a pre-trained vision foundation model, while progressively reducing the regularization strength toward the tail to allow finer low-level detail reconstruction. Extensive experiments demonstrate the effectiveness of ReTok: on ImageNet 256$\times$256, our method achieves superior generation performance compared with both flexible and fixed-length tokenizers. Code will be available at: \href{https://github.com/zfu006/ReTok}{https://github.com/zfu006/ReTok}
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
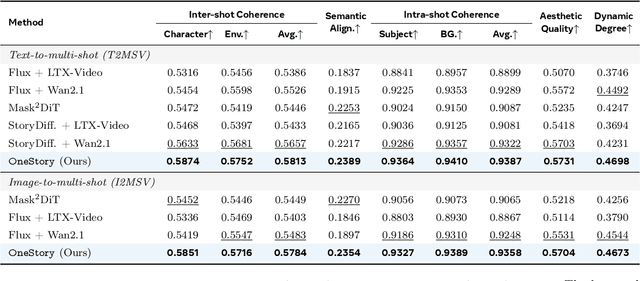
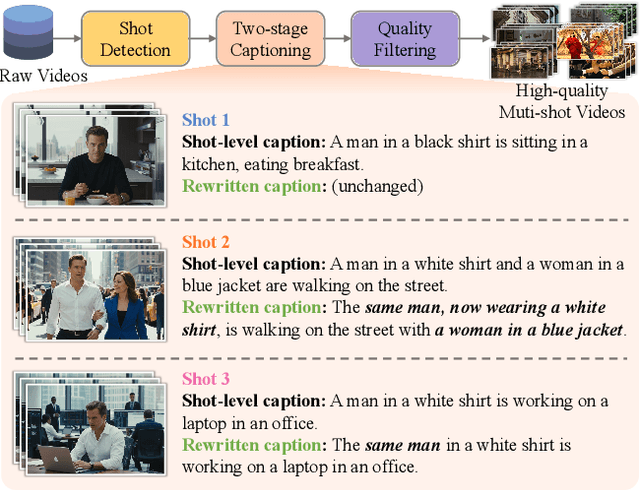

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
A Text-Based Knowledge-Embedded Soft Sensing Modeling Approach for General Industrial Process Tasks Based on Large Language Model
Jan 09, 2025Data-driven soft sensors (DDSS) have become mainstream methods for predicting key performance indicators in process industries. However, DDSS development requires complex and costly customized designs tailored to various tasks during the modeling process. Moreover, DDSS are constrained to a single structured data modality, limiting their ability to incorporate additional contextual knowledge. Furthermore, DDSSs' limited representation learning leads to weak predictive performance with scarce data. To address these challenges, we propose a general framework named LLM-TKESS (large language model for text-based knowledge-embedded soft sensing), harnessing the powerful general problem-solving capabilities, cross-modal knowledge transfer abilities, and few-shot capabilities of LLM for enhanced soft sensing modeling. Specifically, an auxiliary variable series encoder (AVS Encoder) is proposed to unleash LLM's potential for capturing temporal relationships within series and spatial semantic relationships among auxiliary variables. Then, we propose a two-stage fine-tuning alignment strategy: in the first stage, employing parameter-efficient fine-tuning through autoregressive training adjusts LLM to rapidly accommodate process variable data, resulting in a soft sensing foundation model (SSFM). Subsequently, by training adapters, we adapt the SSFM to various downstream tasks without modifying its architecture. Then, we propose two text-based knowledge-embedded soft sensors, integrating new natural language modalities to overcome the limitations of pure structured data models. Furthermore, benefiting from LLM's pre-existing world knowledge, our model demonstrates outstanding predictive capabilities in small sample conditions. Using the thermal deformation of air preheater rotor as a case study, we validate through extensive experiments that LLM-TKESS exhibits outstanding performance.
A Soft Sensor Method with Uncertainty-Awareness and Self-Explanation Based on Large Language Models Enhanced by Domain Knowledge Retrieval
Jan 08, 2025



Data-driven soft sensors are crucial in predicting key performance indicators in industrial systems. However, current methods predominantly rely on the supervised learning paradigms of parameter updating, which inherently faces challenges such as high development costs, poor robustness, training instability, and lack of interpretability. Recently, large language models (LLMs) have demonstrated significant potential across various domains, notably through In-Context Learning (ICL), which enables high-performance task execution with minimal input-label demonstrations and no prior training. This paper aims to replace supervised learning with the emerging ICL paradigm for soft sensor modeling to address existing challenges and explore new avenues for advancement. To achieve this, we propose a novel framework called the Few-shot Uncertainty-aware and self-Explaining Soft Sensor (LLM-FUESS), which includes the Zero-shot Auxiliary Variable Selector (LLM-ZAVS) and the Uncertainty-aware Few-shot Soft Sensor (LLM-UFSS). The LLM-ZAVS retrieves from the Industrial Knowledge Vector Storage to enhance LLMs' domain-specific knowledge, enabling zero-shot auxiliary variable selection. In the LLM-UFSS, we utilize text-based context demonstrations of structured data to prompt LLMs to execute ICL for predicting and propose a context sample retrieval augmentation strategy to improve performance. Additionally, we explored LLMs' AIGC and probabilistic characteristics to propose self-explanation and uncertainty quantification methods for constructing a trustworthy soft sensor. Extensive experiments demonstrate that our method achieved state-of-the-art predictive performance, strong robustness, and flexibility, effectively mitigates training instability found in traditional methods. To the best of our knowledge, this is the first work to establish soft sensor utilizing LLMs.
White-Box Diffusion Transformer for single-cell RNA-seq generation
Nov 16, 2024



As a powerful tool for characterizing cellular subpopulations and cellular heterogeneity, single cell RNA sequencing (scRNA-seq) technology offers advantages of high throughput and multidimensional analysis. However, the process of data acquisition is often constrained by high cost and limited sample availability. To overcome these limitations, we propose a hybrid model based on Diffusion model and White-Box transformer that aims to generate synthetic and biologically plausible scRNA-seq data. Diffusion model progressively introduce noise into the data and then recover the original data through a denoising process, a forward and reverse process that is particularly suitable for generating complex data distributions. White-Box transformer is a deep learning architecture that emphasizes mathematical interpretability. By minimizing the encoding rate of the data and maximizing the sparsity of the representation, it not only reduces the computational burden, but also provides clear insight into underlying structure. Our White-Box Diffusion Transformer combines the generative capabilities of Diffusion model with the mathematical interpretability of White-Box transformer. Through experiments using six different single-cell RNA-Seq datasets, we visualize both generated and real data using t-SNE dimensionality reduction technique, as well as quantify similarity between generated and real data using various metrics to demonstrate comparable performance of White-Box Diffusion Transformer and Diffusion Transformer in generating scRNA-seq data alongside significant improvements in training efficiency and resource utilization. Our code is available at https://github.com/lingximamo/White-Box-Diffusion-Transformer
Adaptive Caching for Faster Video Generation with Diffusion Transformers
Nov 04, 2024



Generating temporally-consistent high-fidelity videos can be computationally expensive, especially over longer temporal spans. More-recent Diffusion Transformers (DiTs) -- despite making significant headway in this context -- have only heightened such challenges as they rely on larger models and heavier attention mechanisms, resulting in slower inference speeds. In this paper, we introduce a training-free method to accelerate video DiTs, termed Adaptive Caching (AdaCache), which is motivated by the fact that "not all videos are created equal": meaning, some videos require fewer denoising steps to attain a reasonable quality than others. Building on this, we not only cache computations through the diffusion process, but also devise a caching schedule tailored to each video generation, maximizing the quality-latency trade-off. We further introduce a Motion Regularization (MoReg) scheme to utilize video information within AdaCache, essentially controlling the compute allocation based on motion content. Altogether, our plug-and-play contributions grant significant inference speedups (e.g. up to 4.7x on Open-Sora 720p - 2s video generation) without sacrificing the generation quality, across multiple video DiT baselines.
MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
Oct 26, 2024



We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini's MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.