 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBonnet: Ultra-fast whole-body bone segmentation from CT scans
Jan 30, 2026This work proposes Bonnet, an ultra-fast sparse-volume pipeline for whole-body bone segmentation from CT scans. Accurate bone segmentation is important for surgical planning and anatomical analysis, but existing 3D voxel-based models such as nnU-Net and STU-Net require heavy computation and often take several minutes per scan, which limits time-critical use. The proposed Bonnet addresses this by integrating a series of novel framework components including HU-based bone thresholding, patch-wise inference with a sparse spconv-based U-Net, and multi-window fusion into a full-volume prediction. Trained on TotalSegmentator and evaluated without additional tuning on RibSeg, CT-Pelvic1K, and CT-Spine1K, Bonnet achieves high Dice across ribs, pelvis, and spine while running in only 2.69 seconds per scan on an RTX A6000. Compared to strong voxel baselines, Bonnet attains a similar accuracy but reduces inference time by roughly 25x on the same hardware and tiling setup. The toolkit and pre-trained models will be released at https://github.com/HINTLab/Bonnet.
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
Jan 29, 2026High-definition (HD) maps provide essential semantic information of road structures for autonomous driving systems, yet current HD map construction methods require calibrated multi-camera setups and either implicit or explicit 2D-to-BEV transformations, making them fragile when sensors fail or camera configurations vary across vehicle fleets. We introduce FlexMap, unlike prior methods that are fixed to a specific N-camera rig, our approach adapts to variable camera configurations without any architectural changes or per-configuration retraining. Our key innovation eliminates explicit geometric projections by using a geometry-aware foundation model with cross-frame attention to implicitly encode 3D scene understanding in feature space. FlexMap features two core components: a spatial-temporal enhancement module that separates cross-view spatial reasoning from temporal dynamics, and a camera-aware decoder with latent camera tokens, enabling view-adaptive attention without the need for projection matrices. Experiments demonstrate that FlexMap outperforms existing methods across multiple configurations while maintaining robustness to missing views and sensor variations, enabling more practical real-world deployment.
Spatial-Conditioned Reasoning in Long-Egocentric Videos
Jan 26, 2026Long-horizon egocentric video presents significant challenges for visual navigation due to viewpoint drift and the absence of persistent geometric context. Although recent vision-language models perform well on image and short-video reasoning, their spatial reasoning capability in long egocentric sequences remains limited. In this work, we study how explicit spatial signals influence VLM-based video understanding without modifying model architectures or inference procedures. We introduce Sanpo-D, a fine-grained re-annotation of the Google Sanpo dataset, and benchmark multiple VLMs on navigation-oriented spatial queries. To examine input-level inductive bias, we further fuse depth maps with RGB frames and evaluate their impact on spatial reasoning. Our results reveal a trade-off between general-purpose accuracy and spatial specialization, showing that depth-aware and spatially grounded representations can improve performance on safety-critical tasks such as pedestrian and obstruction detection.
Motion Focus Recognition in Fast-Moving Egocentric Video
Jan 12, 2026From Vision-Language-Action (VLA) systems to robotics, existing egocentric datasets primarily focus on action recognition tasks, while largely overlooking the inherent role of motion analysis in sports and other fast-movement scenarios. To bridge this gap, we propose a real-time motion focus recognition method that estimates the subject's locomotion intention from any egocentric video. Our approach leverages the foundation model for camera pose estimation and introduces system-level optimizations to enable efficient and scalable inference. Evaluated on a collected egocentric action dataset, our method achieves real-time performance with manageable memory consumption through a sliding batch inference strategy. This work makes motion-centric analysis practical for edge deployment and offers a complementary perspective to existing egocentric studies on sports and fast-movement activities.
Fast 2DGS: Efficient Image Representation with Deep Gaussian Prior
Dec 14, 2025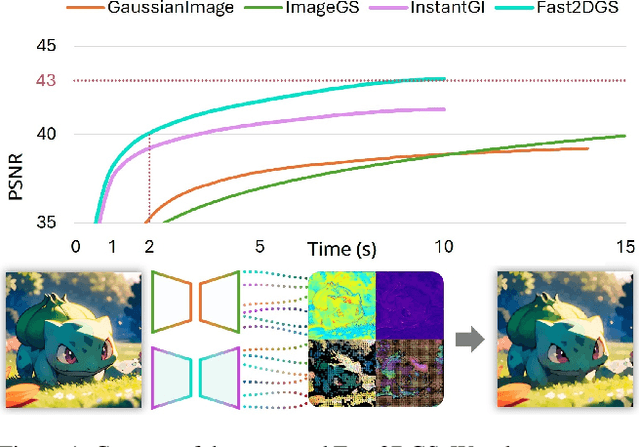

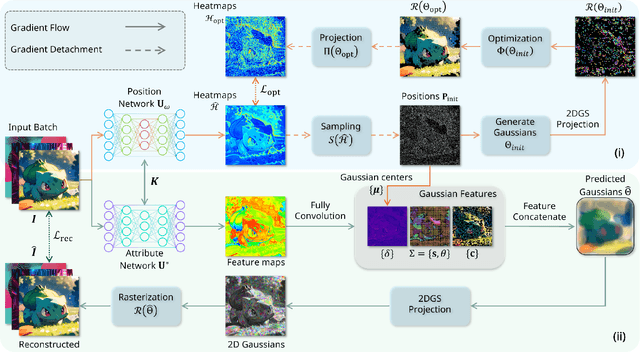
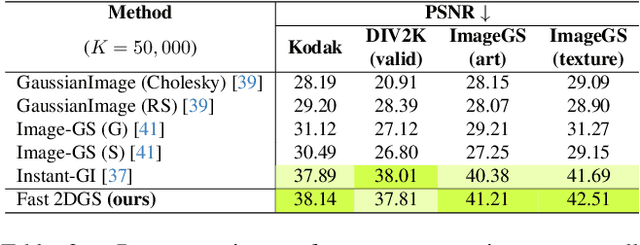
As generative models become increasingly capable of producing high-fidelity visual content, the demand for efficient, interpretable, and editable image representations has grown substantially. Recent advances in 2D Gaussian Splatting (2DGS) have emerged as a promising solution, offering explicit control, high interpretability, and real-time rendering capabilities (>1000 FPS). However, high-quality 2DGS typically requires post-optimization. Existing methods adopt random or heuristics (e.g., gradient maps), which are often insensitive to image complexity and lead to slow convergence (>10s). More recent approaches introduce learnable networks to predict initial Gaussian configurations, but at the cost of increased computational and architectural complexity. To bridge this gap, we present Fast-2DGS, a lightweight framework for efficient Gaussian image representation. Specifically, we introduce Deep Gaussian Prior, implemented as a conditional network to capture the spatial distribution of Gaussian primitives under different complexities. In addition, we propose an attribute regression network to predict dense Gaussian properties. Experiments demonstrate that this disentangled architecture achieves high-quality reconstruction in a single forward pass, followed by minimal fine-tuning. More importantly, our approach significantly reduces computational cost without compromising visual quality, bringing 2DGS closer to industry-ready deployment.
Inferring Diffusion Structures of Heterogeneous Network Cascade
Jun 23, 2025Network cascade refers to diffusion processes in which outcome changes within part of an interconnected population trigger a sequence of changes across the entire network. These cascades are governed by underlying diffusion networks, which are often latent. Inferring such networks is critical for understanding cascade pathways, uncovering Granger causality of interaction mechanisms among individuals, and enabling tasks such as forecasting or maximizing information propagation. In this project, we propose a novel double mixture directed graph model for inferring multi-layer diffusion networks from cascade data. The proposed model represents cascade pathways as a mixture of diffusion networks across different layers, effectively capturing the strong heterogeneity present in real-world cascades. Additionally, the model imposes layer-specific structural constraints, enabling diffusion networks at different layers to capture complementary cascading patterns at the population level. A key advantage of our model is its convex formulation, which allows us to establish both statistical and computational guarantees for the resulting diffusion network estimates. We conduct extensive simulation studies to demonstrate the model's performance in recovering diverse diffusion structures. Finally, we apply the proposed method to analyze cascades of research topics in the social sciences across U.S. universities, revealing the underlying diffusion networks of research topic propagation among institutions.
On the Natural Robustness of Vision-Language Models Against Visual Perception Attacks in Autonomous Driving
Jun 13, 2025Autonomous vehicles (AVs) rely on deep neural networks (DNNs) for critical tasks such as traffic sign recognition (TSR), automated lane centering (ALC), and vehicle detection (VD). However, these models are vulnerable to attacks that can cause misclassifications and compromise safety. Traditional defense mechanisms, including adversarial training, often degrade benign accuracy and fail to generalize against unseen attacks. In this work, we introduce Vehicle Vision Language Models (V2LMs), fine-tuned vision-language models specialized for AV perception. Our findings demonstrate that V2LMs inherently exhibit superior robustness against unseen attacks without requiring adversarial training, maintaining significantly higher accuracy than conventional DNNs under adversarial conditions. We evaluate two deployment strategies: Solo Mode, where individual V2LMs handle specific perception tasks, and Tandem Mode, where a single unified V2LM is fine-tuned for multiple tasks simultaneously. Experimental results reveal that DNNs suffer performance drops of 33% to 46% under attacks, whereas V2LMs maintain adversarial accuracy with reductions of less than 8% on average. The Tandem Mode further offers a memory-efficient alternative while achieving comparable robustness to Solo Mode. We also explore integrating V2LMs as parallel components to AV perception to enhance resilience against adversarial threats. Our results suggest that V2LMs offer a promising path toward more secure and resilient AV perception systems.
Securing the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
Apr 16, 2025Unmanned Aerial Vehicles (UAVs) are indispensable for infrastructure inspection, surveillance, and related tasks, yet they also introduce critical security challenges. This survey provides a wide-ranging examination of the anti-UAV domain, centering on three core objectives-classification, detection, and tracking-while detailing emerging methodologies such as diffusion-based data synthesis, multi-modal fusion, vision-language modeling, self-supervised learning, and reinforcement learning. We systematically evaluate state-of-the-art solutions across both single-modality and multi-sensor pipelines (spanning RGB, infrared, audio, radar, and RF) and discuss large-scale as well as adversarially oriented benchmarks. Our analysis reveals persistent gaps in real-time performance, stealth detection, and swarm-based scenarios, underscoring pressing needs for robust, adaptive anti-UAV systems. By highlighting open research directions, we aim to foster innovation and guide the development of next-generation defense strategies in an era marked by the extensive use of UAVs.
Bézier Splatting for Fast and Differentiable Vector Graphics
Mar 20, 2025



Differentiable vector graphics (VGs) are widely used in image vectorization and vector synthesis, while existing representations are costly to optimize and struggle to achieve high-quality rendering results for high-resolution images. This work introduces a new differentiable VG representation, dubbed B\'ezier splatting, that enables fast yet high-fidelity VG rasterization. B\'ezier splatting samples 2D Gaussians along B\'ezier curves, which naturally provide positional gradients at object boundaries. Thanks to the efficient splatting-based differentiable rasterizer, B\'ezier splatting achieves over 20x and 150x faster per forward and backward rasterization step for open curves compared to DiffVG. Additionally, we introduce an adaptive pruning and densification strategy that dynamically adjusts the spatial distribution of curves to escape local minima, further improving VG quality. Experimental results show that B\'ezier splatting significantly outperforms existing methods with better visual fidelity and 10x faster optimization speed.
Latent Radiance Fields with 3D-aware 2D Representations
Feb 13, 2025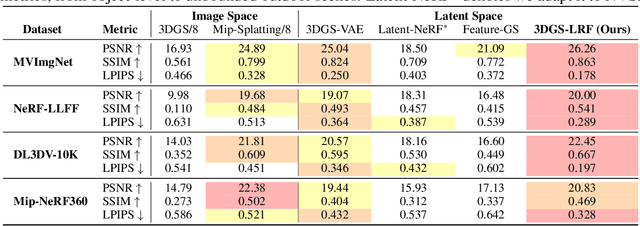
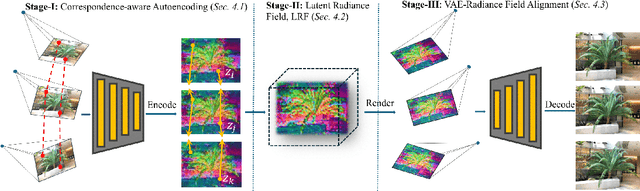


Latent 3D reconstruction has shown great promise in empowering 3D semantic understanding and 3D generation by distilling 2D features into the 3D space. However, existing approaches struggle with the domain gap between 2D feature space and 3D representations, resulting in degraded rendering performance. To address this challenge, we propose a novel framework that integrates 3D awareness into the 2D latent space. The framework consists of three stages: (1) a correspondence-aware autoencoding method that enhances the 3D consistency of 2D latent representations, (2) a latent radiance field (LRF) that lifts these 3D-aware 2D representations into 3D space, and (3) a VAE-Radiance Field (VAE-RF) alignment strategy that improves image decoding from the rendered 2D representations. Extensive experiments demonstrate that our method outperforms the state-of-the-art latent 3D reconstruction approaches in terms of synthesis performance and cross-dataset generalizability across diverse indoor and outdoor scenes. To our knowledge, this is the first work showing the radiance field representations constructed from 2D latent representations can yield photorealistic 3D reconstruction performance.