 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTxRay: Agentic Postmortem of Live Blockchain Attacks
Feb 01, 2026Decentralized Finance (DeFi) has turned blockchains into financial infrastructure, allowing anyone to trade, lend, and build protocols without intermediaries, but this openness exposes pools of value controlled by code. Within five years, the DeFi ecosystem has lost over 15.75B USD to reported exploits. Many exploits arise from permissionless opportunities that any participant can trigger using only public state and standard interfaces, which we call Anyone-Can-Take (ACT) opportunities. Despite on-chain transparency, postmortem analysis remains slow and manual: investigations start from limited evidence, sometimes only a single transaction hash, and must reconstruct the exploit lifecycle by recovering related transactions, contract code, and state dependencies. We present TxRay, a Large Language Model (LLM) agentic postmortem system that uses tool calls to reconstruct live ACT attacks from limited evidence. Starting from one or more seed transactions, TxRay recovers the exploit lifecycle, derives an evidence-backed root cause, and generates a runnable, self-contained Proof of Concept (PoC) that deterministically reproduces the incident. TxRay self-checks postmortems by encoding incident-specific semantic oracles as executable assertions. To evaluate PoC correctness and quality, we develop PoCEvaluator, an independent agentic execution-and-review evaluator. On 114 incidents from DeFiHackLabs, TxRay produces an expert-aligned root cause and an executable PoC for 105 incidents, achieving 92.11% end-to-end reproduction. Under PoCEvaluator, 98.1% of TxRay PoCs avoid hard-coding attacker addresses, a +24.8pp lift over DeFiHackLabs. In a live deployment, TxRay delivers validated root causes in 40 minutes and PoCs in 59 minutes at median latency. TxRay's oracle-validated PoCs enable attack imitation, improving coverage by 15.6% and 65.5% over STING and APE.
PathReasoner-R1: Instilling Structured Reasoning into Pathology Vision-Language Model via Knowledge-Guided Policy Optimization
Jan 29, 2026Vision-Language Models (VLMs) are advancing computational pathology with superior visual understanding capabilities. However, current systems often reduce diagnosis to directly output conclusions without verifiable evidence-linked reasoning, which severely limits clinical trust and hinders expert error rectification. To address these barriers, we construct PathReasoner, the first large-scale dataset of whole-slide image (WSI) reasoning. Unlike previous work reliant on unverified distillation, we develop a rigorous knowledge-guided generation pipeline. By leveraging medical knowledge graphs, we explicitly align structured pathological findings and clinical reasoning with diagnoses, generating over 20K high-quality instructional samples. Based on the database, we propose PathReasoner-R1, which synergizes trajectory-masked supervised fine-tuning with reasoning-oriented reinforcement learning to instill structured chain-of-thought capabilities. To ensure medical rigor, we engineer a knowledge-aware multi-granular reward function incorporating an Entity Reward mechanism strictly aligned with knowledge graphs. This effectively guides the model to optimize for logical consistency rather than mere outcome matching, thereby enhancing robustness. Extensive experiments demonstrate that PathReasoner-R1 achieves state-of-the-art performance on both PathReasoner and public benchmarks across various image scales, equipping pathology models with transparent, clinically grounded reasoning capabilities. Dataset and code are available at https://github.com/cyclexfy/PathReasoner-R1.
Video-KTR: Reinforcing Video Reasoning via Key Token Attribution
Jan 27, 2026Reinforcement learning (RL) has shown strong potential for enhancing reasoning in multimodal large language models, yet existing video reasoning methods often rely on coarse sequence-level rewards or single-factor token selection, neglecting fine-grained links among visual inputs, temporal dynamics, and linguistic outputs, limiting both accuracy and interpretability. We propose Video-KTR, a modality-aware policy shaping framework that performs selective, token-level RL by combining three attribution signals: (1) visual-aware tokens identified via counterfactual masking to reveal perceptual dependence; (2) temporal-aware tokens detected through frame shuffling to expose temporal sensitivity; and (3) high-entropy tokens signaling predictive uncertainty. By reinforcing only these key tokens, Video-KTR focuses learning on semantically informative, modality-sensitive content while filtering out low-value tokens. Across five challenging benchmarks, Video-KTR achieves state-of-the-art or highly competitive results, achieving 42.7\% on Video-Holmes (surpassing GPT-4o) with consistent gains on both reasoning and general video understanding tasks. Ablation studies verify the complementary roles of the attribution signals and the robustness of targeted token-level updates. Overall, Video-KTR improves accuracy and interpretability, offering a simple, drop-in extension to RL for complex video reasoning. Our code and models are available at https://github.com/zywang0104/Video-KTR.
PathFLIP: Fine-grained Language-Image Pretraining for Versatile Computational Pathology
Dec 19, 2025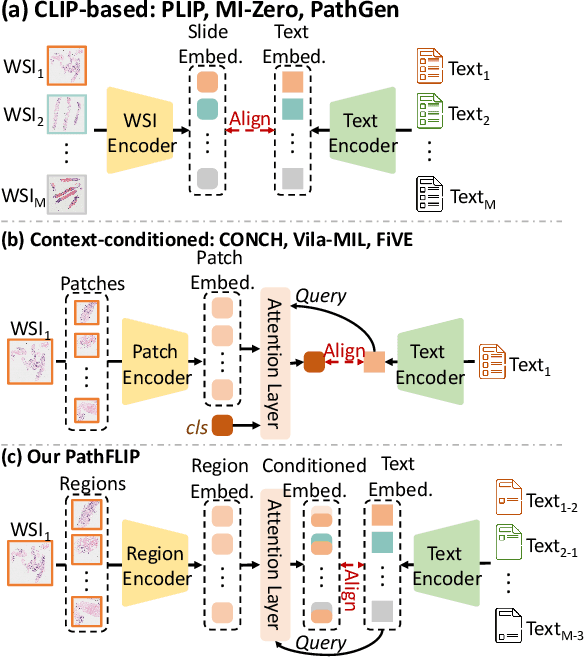
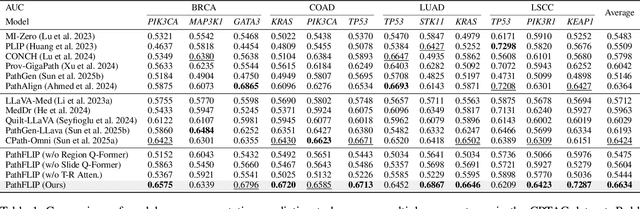
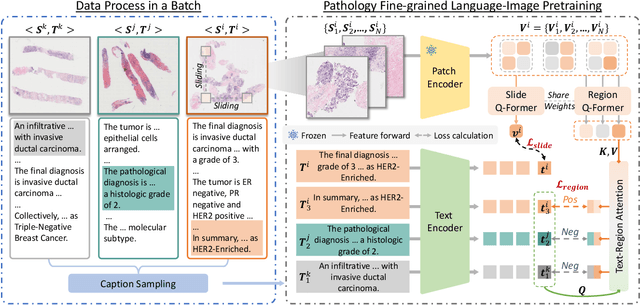
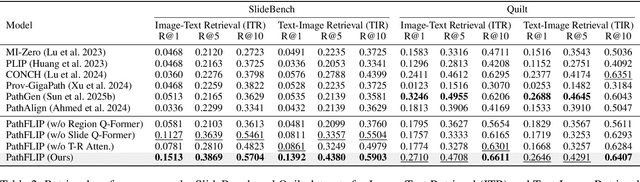
While Vision-Language Models (VLMs) have achieved notable progress in computational pathology (CPath), the gigapixel scale and spatial heterogeneity of Whole Slide Images (WSIs) continue to pose challenges for multimodal understanding. Existing alignment methods struggle to capture fine-grained correspondences between textual descriptions and visual cues across thousands of patches from a slide, compromising their performance on downstream tasks. In this paper, we propose PathFLIP (Pathology Fine-grained Language-Image Pretraining), a novel framework for holistic WSI interpretation. PathFLIP decomposes slide-level captions into region-level subcaptions and generates text-conditioned region embeddings to facilitate precise visual-language grounding. By harnessing Large Language Models (LLMs), PathFLIP can seamlessly follow diverse clinical instructions and adapt to varied diagnostic contexts. Furthermore, it exhibits versatile capabilities across multiple paradigms, efficiently handling slide-level classification and retrieval, fine-grained lesion localization, and instruction following. Extensive experiments demonstrate that PathFLIP outperforms existing large-scale pathological VLMs on four representative benchmarks while requiring significantly less training data, paving the way for fine-grained, instruction-aware WSI interpretation in clinical practice.
Doctor-R1: Mastering Clinical Inquiry with Experiential Agentic Reinforcement Learning
Oct 05, 2025The professionalism of a human doctor in outpatient service depends on two core abilities: the ability to make accurate medical decisions and the medical consultation skill to conduct strategic, empathetic patient inquiry. Existing Large Language Models (LLMs) have achieved remarkable accuracy on medical decision-making benchmarks. However, they often lack the ability to conduct the strategic and empathetic consultation, which is essential for real-world clinical scenarios. To address this gap, we propose Doctor-R1, an AI doctor agent trained to master both of the capabilities by ask high-yield questions and conduct strategic multi-turn inquiry to guide decision-making. Our framework introduces three key components: a multi-agent interactive environment, a two-tiered reward architecture that separately optimizes clinical decision-making and communicative inquiry skills, and an experience repository to ground policy learning in high-quality prior trajectories. We evaluate Doctor-R1 on OpenAI's HealthBench and MAQuE, assessed across multi-facet metrics, such as communication quality, user experience, and task accuracy. Remarkably, Doctor-R1 surpasses state-of-the-art open-source specialized LLMs by a substantial margin with higher parameter efficiency and outperforms powerful proprietary models. Furthermore, the human evaluations show a strong preference for Doctor-R1 to generate human-preferred clinical dialogue, demonstrating the effectiveness of the framework.
A Unified Distributed Algorithm for Hybrid Near-Far Field Activity Detection in Cell-Free Massive MIMO
Sep 18, 2025
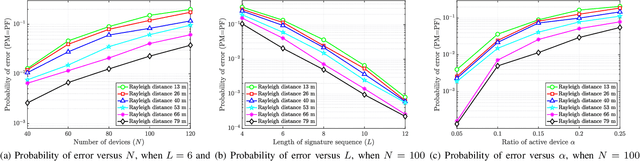
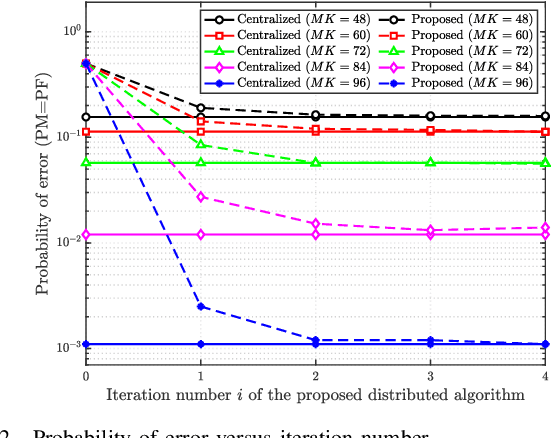
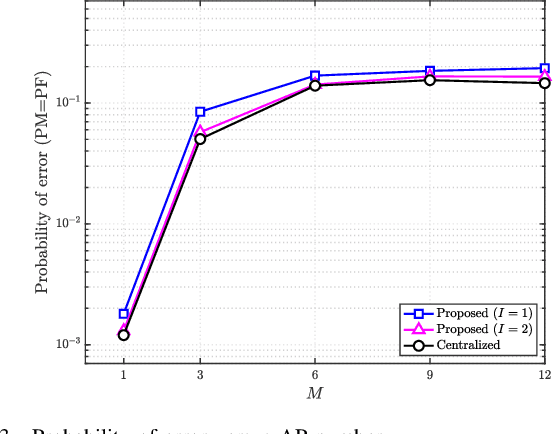
A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free multiple-input multiple-output (MIMO) systems. However, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper establishes a covariance-based formulation that can effectively capture the statistical property of hybrid near-far field channels. Based on this formulation, we theoretically reveal that increasing the proportion of near-field channels enhances the detection performance. Furthermore, we propose a distributed algorithm, where each AP performs local activity detection and only exchanges the detection results to the central processing unit, thus significantly reducing the computational complexity and the communication overhead. Not only with convergence guarantee, the proposed algorithm is unified in the sense that it can handle single-cell or cell-free systems with either near-field or far-field devices as special cases. Simulation results validate the theoretical analyses and demonstrate the superior performance of the proposed approach compared with existing methods.
Diving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Sep 17, 2025
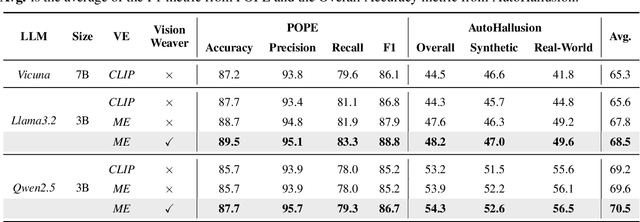
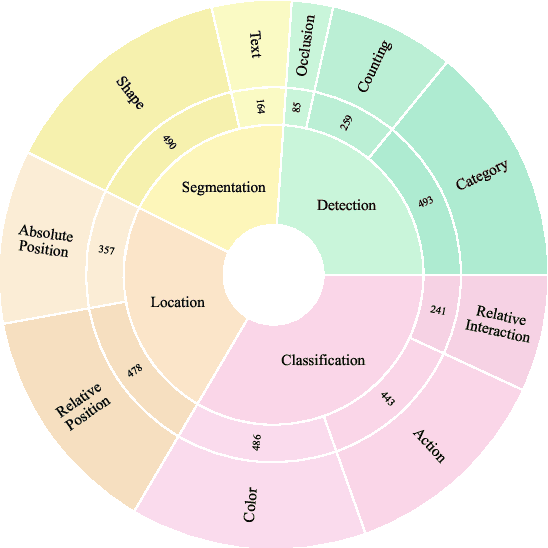
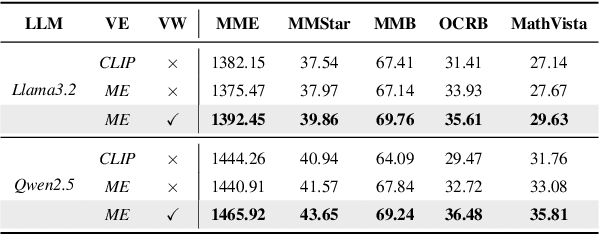
Object hallucination in Large Vision-Language Models (LVLMs) significantly impedes their real-world applicability. As the primary component for accurately interpreting visual information, the choice of visual encoder is pivotal. We hypothesize that the diverse training paradigms employed by different visual encoders instill them with distinct inductive biases, which leads to their diverse hallucination performances. Existing benchmarks typically focus on coarse-grained hallucination detection and fail to capture the diverse hallucinations elaborated in our hypothesis. To systematically analyze these effects, we introduce VHBench-10, a comprehensive benchmark with approximately 10,000 samples for evaluating LVLMs across ten fine-grained hallucination categories. Our evaluations confirm encoders exhibit unique hallucination characteristics. Building on these insights and the suboptimality of simple feature fusion, we propose VisionWeaver, a novel Context-Aware Routing Network. It employs global visual features to generate routing signals, dynamically aggregating visual features from multiple specialized experts. Comprehensive experiments confirm the effectiveness of VisionWeaver in significantly reducing hallucinations and improving overall model performance.
Distributed Activity Detection for Cell-Free Hybrid Near-Far Field Communications
Jun 17, 2025A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free massive MIMO. However, in practice, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper considers a hybrid near-far field activity detection in cell-free massive MIMO, and establishes a covariance-based formulation, which facilitates the development of a distributed algorithm to alleviate the computational burden at the central processing unit (CPU). Specifically, each AP performs local activity detection for the devices and then transmits the detection result to the CPU for further processing. In particular, a novel coordinate descent algorithm based on the Sherman-Morrison-Woodbury update with Taylor expansion is proposed to handle the local detection problem at each AP. Moreover, we theoretically analyze how the hybrid near-far field channels affect the detection performance. Simulation results validate the theoretical analysis and demonstrate the superior performance of the proposed approach compared with existing approaches.
The Four Color Theorem for Cell Instance Segmentation
Jun 11, 2025Cell instance segmentation is critical to analyzing biomedical images, yet accurately distinguishing tightly touching cells remains a persistent challenge. Existing instance segmentation frameworks, including detection-based, contour-based, and distance mapping-based approaches, have made significant progress, but balancing model performance with computational efficiency remains an open problem. In this paper, we propose a novel cell instance segmentation method inspired by the four-color theorem. By conceptualizing cells as countries and tissues as oceans, we introduce a four-color encoding scheme that ensures adjacent instances receive distinct labels. This reformulation transforms instance segmentation into a constrained semantic segmentation problem with only four predicted classes, substantially simplifying the instance differentiation process. To solve the training instability caused by the non-uniqueness of four-color encoding, we design an asymptotic training strategy and encoding transformation method. Extensive experiments on various modes demonstrate our approach achieves state-of-the-art performance. The code is available at https://github.com/zhangye-zoe/FCIS.
MUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
May 27, 2025Video temporal understanding is crucial for multimodal large language models (MLLMs) to reason over events in videos. Despite recent advances in general video understanding, current MLLMs still struggle with fine-grained temporal reasoning. While reinforcement learning (RL) has been explored to address this issue recently, existing RL approaches remain limited in effectiveness. In this work, we propose MUSEG, a novel RL-based method that enhances temporal understanding by introducing timestamp-aware multi-segment grounding. MUSEG enables MLLMs to align queries with multiple relevant video segments, promoting more comprehensive temporal reasoning. To facilitate effective learning, we design a customized RL training recipe with phased rewards that progressively guides the model toward temporally grounded reasoning. Extensive experiments on temporal grounding and time-sensitive video QA tasks demonstrate that MUSEG significantly outperforms existing methods and generalizes well across diverse temporal understanding scenarios. View our project at https://github.com/THUNLP-MT/MUSEG.