 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDySem: Uncovering Dynamic Semantic Components via Multilingual Consensus for Calculating Semantic Textual Similarity
May 28, 2026Calculating semantic textual similarity is a foundational task in natural language processing. Current large language models (LLMs) based methods typically rely on extracting last-layer hidden states with fixed dimensions to compute similarity for every text pairs. We argue that this paradigm is suffer from two limitations: (i) The last hidden layer encodes more general knowledge rather than just semantic knowledge, making it suboptimal for semantic similarity computation; (ii) The hidden layer dimensions of LLMs are generally very large, which introduces some redundancy and noise for representing semantics. In this work, we propose DySem, a novel training-free framework that investigates more semantic-related internal components of LLMs via multilingual consensus, and shifts away from static representation spaces in favor of dynamic, sample-specific semantic dimensions by constructing text-dependent joint semantic set and computes similarity over this shared dimensional subset. Extensive experiments across various LLMs show that our method consistently outperforms recent baselines while maintaining lower dimensions for similarity calculation. The code is released at https://github.com/szu-tera/DySem.
DeCoVec: Building Decoding Space based Task Vector for Large Language Models via In-Context Learning
Apr 13, 2026Task vectors, representing directions in model or activation spaces that encode task-specific behaviors, have emerged as a promising tool for steering large language models (LLMs). However, existing approaches typically require fine-tuning or invasive manipulation of internal states, limiting their flexibility and scalability. We propose \textsc{DeCoVec} (Decoding Space based Task Vector), a training-free and non-invasive framework that constructs task vectors directly in the \textit{decoding space} by leveraging in-context learning (ICL). Specifically, \textsc{DeCoVec} captures the task essence as the difference between the output logit distributions of few-shot and zero-shot prompts, then steers generation by injecting this vector into the decoding process. Experiments across seven LLMs (0.5B--9B) on TruthfulQA, Math-500, and AQUA-RAT show that \textsc{DeCoVec} consistently outperforms standard few-shot baselines, with gains up to +5.50 average accuracy. Further analysis demonstrates that \textsc{DeCoVec} effectively suppresses generation degeneration and logical flaws while exhibiting strong robustness to demonstration ordering, all without incurring additional input token costs. Our method offers a training-free and non-invasive solution for LLM steering without requiring weight updates or auxiliary models.
Evaluating Memory Capability in Continuous Lifelog Scenario
Apr 13, 2026Nowadays, wearable devices can continuously lifelog ambient conversations, creating substantial opportunities for memory systems. However, existing benchmarks primarily focus on online one-on-one chatting or human-AI interactions, thus neglecting the unique demands of real-world scenarios. Given the scarcity of public lifelogging audio datasets, we propose a hierarchical synthesis framework to curate \textbf{\textsc{LifeDialBench}}, a novel benchmark comprising two complementary subsets: \textbf{EgoMem}, built on real-world egocentric videos, and \textbf{LifeMem}, constructed using simulated virtual community. Crucially, to address the issue of temporal leakage in traditional offline settings, we propose an \textbf{Online Evaluation} protocol that strictly adheres to temporal causality, ensuring systems are evaluated in a realistic streaming fashion. Our experimental results reveal a counterintuitive finding: current sophisticated memory systems fail to outperform a simple RAG-based baseline. This highlights the detrimental impact of over-designed structures and lossy compression in current approaches, emphasizing the necessity of high-fidelity context preservation for lifelog scenarios. We release our code and data at https://github.com/qys77714/LifeDialBench.
Assessment of Generative Named Entity Recognition in the Era of Large Language Models
Jan 25, 2026Named entity recognition (NER) is evolving from a sequence labeling task into a generative paradigm with the rise of large language models (LLMs). We conduct a systematic evaluation of open-source LLMs on both flat and nested NER tasks. We investigate several research questions including the performance gap between generative NER and traditional NER models, the impact of output formats, whether LLMs rely on memorization, and the preservation of general capabilities after fine-tuning. Through experiments across eight LLMs of varying scales and four standard NER datasets, we find that: (1) With parameter-efficient fine-tuning and structured formats like inline bracketed or XML, open-source LLMs achieve performance competitive with traditional encoder-based models and surpass closed-source LLMs like GPT-3; (2) The NER capability of LLMs stems from instruction-following and generative power, not mere memorization of entity-label pairs; and (3) Applying NER instruction tuning has minimal impact on general capabilities of LLMs, even improving performance on datasets like DROP due to enhanced entity understanding. These findings demonstrate that generative NER with LLMs is a promising, user-friendly alternative to traditional methods. We release the data and code at https://github.com/szu-tera/LLMs4NER.
SemPA: Improving Sentence Embeddings of Large Language Models through Semantic Preference Alignment
Jan 08, 2026Traditional sentence embedding methods employ token-level contrastive learning on non-generative pre-trained models. Recently, there have emerged embedding methods based on generative large language models (LLMs). These methods either rely on fixed prompt templates or involve modifications to the model architecture. The former lacks further optimization of the model and results in limited performance, while the latter alters the internal computational mechanisms of the model, thereby compromising its generative capabilities. We propose SemPA, a novel approach that boosts the sentence representations while preserving the generative ability of LLMs via semantic preference alignment. We leverage sentence-level Direct Preference Optimization (DPO) to efficiently optimize LLMs on a paraphrase generation task, where the model learns to discriminate semantically equivalent sentences while preserving inherent generative capacity. Theoretically, we establish a formal connection between DPO and contrastive learning under the Plackett-Luce model framework. Empirically, experimental results on both semantic textual similarity tasks and various benchmarks for LLMs show that SemPA achieves better semantic representations without sacrificing the inherent generation capability of LLMs.
Beyond Majority Voting: Towards Fine-grained and More Reliable Reward Signal for Test-Time Reinforcement Learning
Dec 18, 2025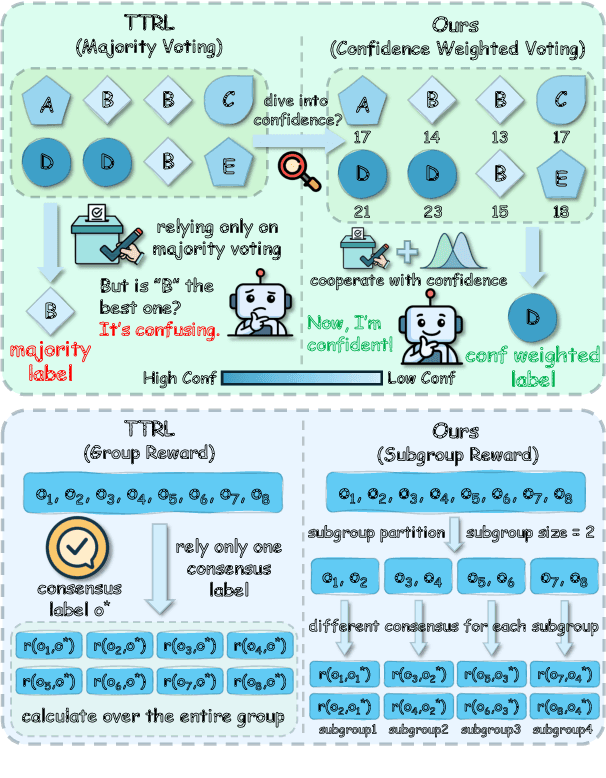



Test-time reinforcement learning mitigates the reliance on annotated data by using majority voting results as pseudo-labels, emerging as a complementary direction to reinforcement learning with verifiable rewards (RLVR) for improving reasoning ability of large language models (LLMs). However, this voting strategy often induces confirmation bias and suffers from sparse rewards, limiting the overall performance. In this work, we propose subgroup-specific step-wise confidence-weighted pseudo-label estimation (SCOPE), a framework integrating model confidence and dynamic subgroup partitioning to address these issues. Specifically, SCOPE integrates the proposed step-wise confidence into pseudo label deduction, prioritizing high-quality reasoning paths over simple frequency count. Furthermore, it dynamically partitions the candidate outputs pool into independent subgroups by balancing reasoning quality against exploration diversity. By deriving local consensus via repeat sampling for each sub group, SCOPE provides diverse supervision targets to encourage broader exploration. We conduct experiments across various models and benchmarks, experimental results show that SCOPE consistently outperforms recent baselines. Notably, SCOPE achieving relative improvements of 13.1% on challenging AIME 2025 and 8.1% on AMC. The code is released at https://github.com/szu-tera/SCOPE.
Ranked Voting based Self-Consistency of Large Language Models
May 16, 2025Majority voting is considered an effective method to enhance chain-of-thought reasoning, as it selects the answer with the highest "self-consistency" among different reasoning paths (Wang et al., 2023). However, previous chain-of-thought reasoning methods typically generate only a single answer in each trial, thereby ignoring the possibility of other potential answers. As a result, these alternative answers are often overlooked in subsequent voting processes. In this work, we propose to generate ranked answers in each reasoning process and conduct ranked voting among multiple ranked answers from different responses, thereby making the overall self-consistency more reliable. Specifically, we use three ranked voting methods: Instant-runoff voting, Borda count voting, and mean reciprocal rank voting. We validate our methods on six datasets, including three multiple-choice and three open-ended question-answering tasks, using both advanced open-source and closed-source large language models. Extensive experimental results indicate that our proposed method outperforms the baselines, showcasing the potential of leveraging the information of ranked answers and using ranked voting to improve reasoning performance. The code is available at https://github.com/szu-tera/RankedVotingSC.
LDIR: Low-Dimensional Dense and Interpretable Text Embeddings with Relative Representations
May 15, 2025Semantic text representation is a fundamental task in the field of natural language processing. Existing text embedding (e.g., SimCSE and LLM2Vec) have demonstrated excellent performance, but the values of each dimension are difficult to trace and interpret. Bag-of-words, as classic sparse interpretable embeddings, suffers from poor performance. Recently, Benara et al. (2024) propose interpretable text embeddings using large language models, which forms "0/1" embeddings based on responses to a series of questions. These interpretable text embeddings are typically high-dimensional (larger than 10,000). In this work, we propose Low-dimensional (lower than 500) Dense and Interpretable text embeddings with Relative representations (LDIR). The numerical values of its dimensions indicate semantic relatedness to different anchor texts through farthest point sampling, offering both semantic representation as well as a certain level of traceability and interpretability. We validate LDIR on multiple semantic textual similarity, retrieval, and clustering tasks. Extensive experimental results show that LDIR performs close to the black-box baseline models and outperforms the interpretable embeddings baselines with much fewer dimensions. Code is available at https://github.com/szu-tera/LDIR.
Perspective Transition of Large Language Models for Solving Subjective Tasks
Jan 16, 2025

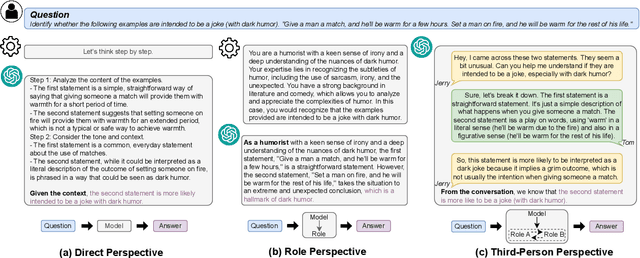
Large language models (LLMs) have revolutionized the field of natural language processing, enabling remarkable progress in various tasks. Different from objective tasks such as commonsense reasoning and arithmetic question-answering, the performance of LLMs on subjective tasks is still limited, where the perspective on the specific problem plays crucial roles for better interpreting the context and giving proper response. For example, in certain scenarios, LLMs may perform better when answering from an expert role perspective, potentially eliciting their relevant domain knowledge. In contrast, in some scenarios, LLMs may provide more accurate responses when answering from a third-person standpoint, enabling a more comprehensive understanding of the problem and potentially mitigating inherent biases. In this paper, we propose Reasoning through Perspective Transition (RPT), a method based on in-context learning that enables LLMs to dynamically select among direct, role, and third-person perspectives for the best way to solve corresponding subjective problem. Through extensive experiments on totally 12 subjective tasks by using both closed-source and open-source LLMs including GPT-4, GPT-3.5, Llama-3, and Qwen-2, our method outperforms widely used single fixed perspective based methods such as chain-of-thought prompting and expert prompting, highlights the intricate ways that LLMs can adapt their perspectives to provide nuanced and contextually appropriate responses for different problems.
Property Enhanced Instruction Tuning for Multi-task Molecule Generation with Large Language Models
Dec 24, 2024Large language models (LLMs) are widely applied in various natural language processing tasks such as question answering and machine translation. However, due to the lack of labeled data and the difficulty of manual annotation for biochemical properties, the performance for molecule generation tasks is still limited, especially for tasks involving multi-properties constraints. In this work, we present a two-step framework PEIT (Property Enhanced Instruction Tuning) to improve LLMs for molecular-related tasks. In the first step, we use textual descriptions, SMILES, and biochemical properties as multimodal inputs to pre-train a model called PEIT-GEN, by aligning multi-modal representations to synthesize instruction data. In the second step, we fine-tune existing open-source LLMs with the synthesized data, the resulting PEIT-LLM can handle molecule captioning, text-based molecule generation, molecular property prediction, and our newly proposed multi-constraint molecule generation tasks. Experimental results show that our pre-trained PEIT-GEN outperforms MolT5 and BioT5 in molecule captioning, demonstrating modalities align well between textual descriptions, structures, and biochemical properties. Furthermore, PEIT-LLM shows promising improvements in multi-task molecule generation, proving the scalability of the PEIT framework for various molecular tasks. We release the code, constructed instruction data, and model checkpoints in https://github.com/chenlong164/PEIT.