 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective Transition of Large Language Models for Solving Subjective Tasks
Jan 16, 2025

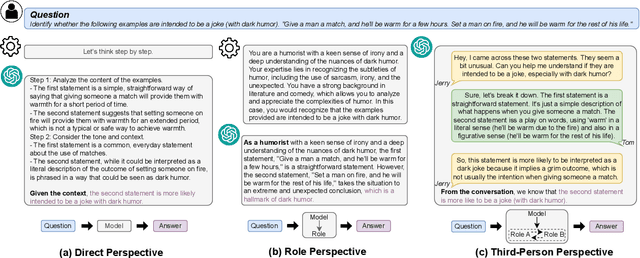
Large language models (LLMs) have revolutionized the field of natural language processing, enabling remarkable progress in various tasks. Different from objective tasks such as commonsense reasoning and arithmetic question-answering, the performance of LLMs on subjective tasks is still limited, where the perspective on the specific problem plays crucial roles for better interpreting the context and giving proper response. For example, in certain scenarios, LLMs may perform better when answering from an expert role perspective, potentially eliciting their relevant domain knowledge. In contrast, in some scenarios, LLMs may provide more accurate responses when answering from a third-person standpoint, enabling a more comprehensive understanding of the problem and potentially mitigating inherent biases. In this paper, we propose Reasoning through Perspective Transition (RPT), a method based on in-context learning that enables LLMs to dynamically select among direct, role, and third-person perspectives for the best way to solve corresponding subjective problem. Through extensive experiments on totally 12 subjective tasks by using both closed-source and open-source LLMs including GPT-4, GPT-3.5, Llama-3, and Qwen-2, our method outperforms widely used single fixed perspective based methods such as chain-of-thought prompting and expert prompting, highlights the intricate ways that LLMs can adapt their perspectives to provide nuanced and contextually appropriate responses for different problems.
ActiView: Evaluating Active Perception Ability for Multimodal Large Language Models
Oct 07, 2024



Active perception, a crucial human capability, involves setting a goal based on the current understanding of the environment and performing actions to achieve that goal. Despite significant efforts in evaluating Multimodal Large Language Models (MLLMs), active perception has been largely overlooked. To address this gap, we propose a novel benchmark named ActiView to evaluate active perception in MLLMs. Since comprehensively assessing active perception is challenging, we focus on a specialized form of Visual Question Answering (VQA) that eases the evaluation yet challenging for existing MLLMs. Given an image, we restrict the perceptual field of a model, requiring it to actively zoom or shift its perceptual field based on reasoning to answer the question successfully. We conduct extensive evaluation over 27 models, including proprietary and open-source models, and observe that the ability to read and comprehend multiple images simultaneously plays a significant role in enabling active perception. Results reveal a significant gap in the active perception capability of MLLMs, indicating that this area deserves more attention. We hope that our benchmark could help develop methods for MLLMs to understand multimodal inputs in more natural and holistic ways.
Reasoning in Conversation: Solving Subjective Tasks through Dialogue Simulation for Large Language Models
Feb 27, 2024



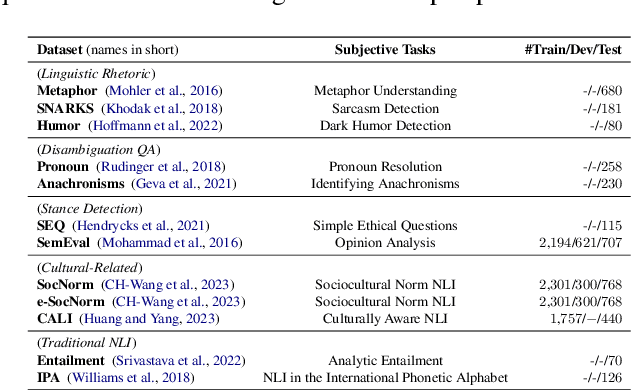
Large Language Models (LLMs) have achieved remarkable performance in objective tasks such as open-domain question answering and mathematical reasoning, which can often be solved through recalling learned factual knowledge or chain-of-thought style reasoning. However, we find that the performance of LLMs in subjective tasks is still unsatisfactory, such as metaphor recognition, dark humor detection, etc. Compared to objective tasks, subjective tasks focus more on interpretation or emotional response rather than a universally accepted reasoning pathway. Based on the characteristics of the tasks and the strong dialogue-generation capabilities of LLMs, we propose RiC (Reasoning in Conversation), a method that focuses on solving subjective tasks through dialogue simulation. The motivation of RiC is to mine useful contextual information by simulating dialogues instead of supplying chain-of-thought style rationales, thereby offering potential useful knowledge behind dialogues for giving the final answers. We evaluate both API-based and open-source LLMs including GPT-4, ChatGPT, and OpenChat across twelve tasks. Experimental results show that RiC can yield significant improvement compared with various baselines.
Enhancing Multilingual Capabilities of Large Language Models through Self-Distillation from Resource-Rich Languages
Feb 19, 2024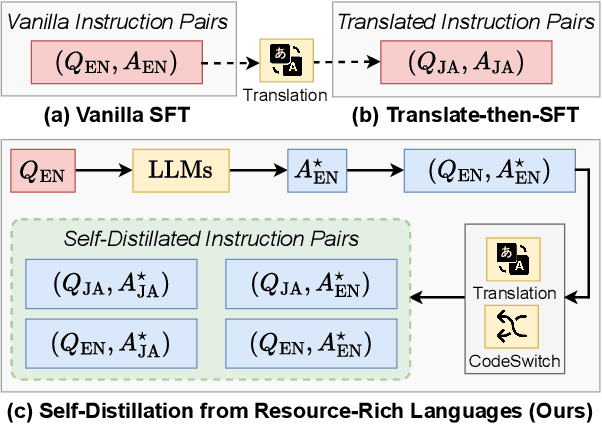


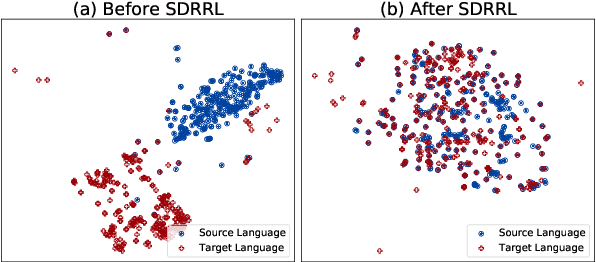
While large language models (LLMs) have been pre-trained on multilingual corpora, their performance still lags behind in most languages compared to a few resource-rich languages. One common approach to mitigate this issue is to translate training data from resource-rich languages into other languages and then continue training. However, using the data obtained solely relying on translation while ignoring the original capabilities of LLMs across languages is not always effective, which we show will limit the performance of cross-lingual knowledge transfer. In this work, we propose SDRRL, a method based on Self-Distillation from Resource-Rich Languages that effectively improve multilingual performance by leveraging the internal capabilities of LLMs on resource-rich languages. We evaluate on different LLMs (LLaMA-2 and SeaLLM) and source languages across various comprehension and generation tasks, experimental results demonstrate that SDRRL can significantly enhance multilingual capabilities while minimizing the impact on original performance in resource-rich languages.
Continually Learning from Existing Models: Knowledge Accumulation for Neural Machine Translation
Dec 18, 2022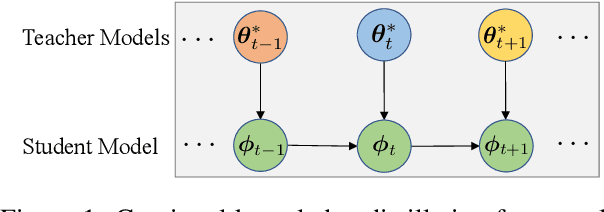
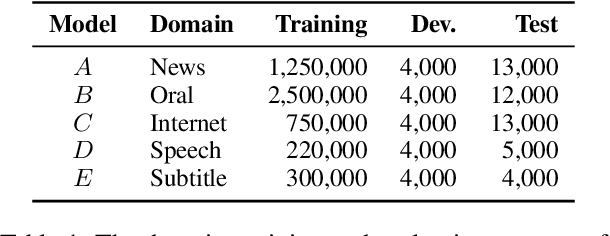
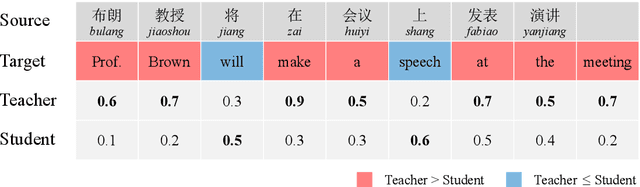
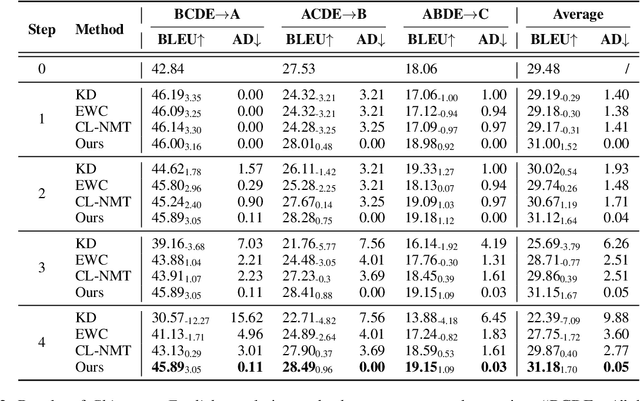
Although continually extending an existing NMT model to new domains or languages has attracted intensive interest in recent years, the equally valuable problem of continually improving a given NMT model in its domain by leveraging knowledge from an unlimited number of existing NMT models is not explored yet. To facilitate the study, we propose a formal definition for the problem named knowledge accumulation for NMT (KA-NMT) with corresponding datasets and evaluation metrics and develop a novel method for KA-NMT. We investigate a novel knowledge detection algorithm to identify beneficial knowledge from existing models at token level, and propose to learn from beneficial knowledge and learn against other knowledge simultaneously to improve learning efficiency. To alleviate catastrophic forgetting, we further propose to transfer knowledge from previous to current version of the given model. Extensive experiments show that our proposed method significantly and consistently outperforms representative baselines under homogeneous, heterogeneous, and malicious model settings for different language pairs.
DirectQuote: A Dataset for Direct Quotation Extraction and Attribution in News Articles
Oct 15, 2021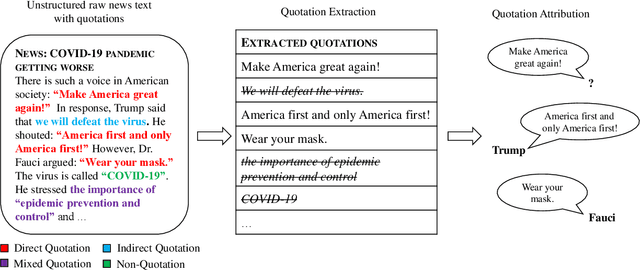
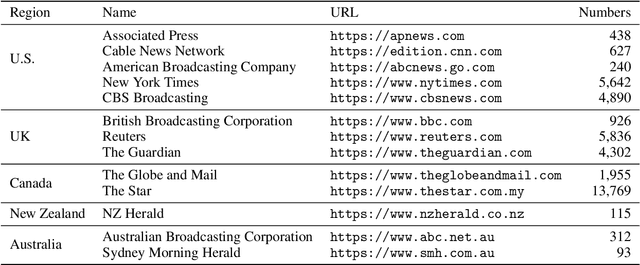


Quotation extraction and attribution are challenging tasks, aiming at determining the spans containing quotations and attributing each quotation to the original speaker. Applying this task to news data is highly related to fact-checking, media monitoring and news tracking. Direct quotations are more traceable and informative, and therefore of great significance among different types of quotations. Therefore, this paper introduces DirectQuote, a corpus containing 19,760 paragraphs and 10,279 direct quotations manually annotated from online news media. To the best of our knowledge, this is the largest and most complete corpus that focuses on direct quotations in news texts. We ensure that each speaker in the annotation can be linked to a specific named entity on Wikidata, benefiting various downstream tasks. In addition, for the first time, we propose several sequence labeling models as baseline methods to extract and attribute quotations simultaneously in an end-to-end manner.