 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
May 27, 2025Video temporal understanding is crucial for multimodal large language models (MLLMs) to reason over events in videos. Despite recent advances in general video understanding, current MLLMs still struggle with fine-grained temporal reasoning. While reinforcement learning (RL) has been explored to address this issue recently, existing RL approaches remain limited in effectiveness. In this work, we propose MUSEG, a novel RL-based method that enhances temporal understanding by introducing timestamp-aware multi-segment grounding. MUSEG enables MLLMs to align queries with multiple relevant video segments, promoting more comprehensive temporal reasoning. To facilitate effective learning, we design a customized RL training recipe with phased rewards that progressively guides the model toward temporally grounded reasoning. Extensive experiments on temporal grounding and time-sensitive video QA tasks demonstrate that MUSEG significantly outperforms existing methods and generalizes well across diverse temporal understanding scenarios. View our project at https://github.com/THUNLP-MT/MUSEG.
Visual Abstract Thinking Empowers Multimodal Reasoning
May 26, 2025Images usually convey richer detail than text, but often include redundant information which potentially downgrades multimodal reasoning performance. When faced with lengthy or complex messages, humans tend to employ abstract thinking to convert them into simple and concise abstracts. Inspired by this cognitive strategy, we introduce Visual Abstract Thinking (VAT), a novel thinking paradigm that prompts Multimodal Large Language Models (MLLMs) with visual abstract instead of explicit verbal thoughts or elaborate guidance, permitting a more concentrated visual reasoning mechanism. Explicit thinking, such as Chain-of-thought (CoT) or tool-augmented approaches, increases the complexity of reasoning process via inserting verbose intermediate steps, external knowledge or visual information. In contrast, VAT reduces redundant visual information and encourages models to focus their reasoning on more essential visual elements. Experimental results show that VAT consistently empowers different models, and achieves an average gain of 17% over GPT-4o baseline by employing diverse types of visual abstracts, demonstrating that VAT can enhance visual reasoning abilities for MLLMs regarding conceptual, structural and relational reasoning tasks. VAT is also compatible with CoT in knowledge-intensive multimodal reasoning tasks. These findings highlight the effectiveness of visual reasoning via abstract thinking and encourage further exploration of more diverse reasoning paradigms from the perspective of human cognition.
How Do Multimodal Large Language Models Handle Complex Multimodal Reasoning? Placing Them in An Extensible Escape Game
Mar 13, 2025The rapid advancing of Multimodal Large Language Models (MLLMs) has spurred interest in complex multimodal reasoning tasks in the real-world and virtual environment, which require coordinating multiple abilities, including visual perception, visual reasoning, spatial awareness, and target deduction. However, existing evaluations primarily assess the final task completion, often degrading assessments to isolated abilities such as visual grounding and visual question answering. Less attention is given to comprehensively and quantitatively analyzing reasoning process in multimodal environments, which is crucial for understanding model behaviors and underlying reasoning mechanisms beyond merely task success. To address this, we introduce MM-Escape, an extensible benchmark for investigating multimodal reasoning, inspired by real-world escape games. MM-Escape emphasizes intermediate model behaviors alongside final task completion. To achieve this, we develop EscapeCraft, a customizable and open environment that enables models to engage in free-form exploration for assessing multimodal reasoning. Extensive experiments show that MLLMs, regardless of scale, can successfully complete the simplest room escape tasks, with some exhibiting human-like exploration strategies. Yet, performance dramatically drops as task difficulty increases. Moreover, we observe that performance bottlenecks vary across models, revealing distinct failure modes and limitations in their multimodal reasoning abilities, such as repetitive trajectories without adaptive exploration, getting stuck in corners due to poor visual spatial awareness, and ineffective use of acquired props, such as the key. We hope our work sheds light on new challenges in multimodal reasoning, and uncovers potential improvements in MLLMs capabilities.
DongbaMIE: A Multimodal Information Extraction Dataset for Evaluating Semantic Understanding of Dongba Pictograms
Mar 05, 2025
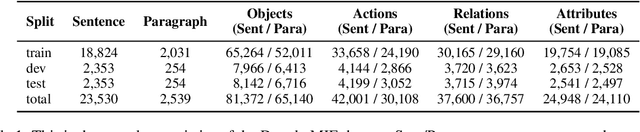
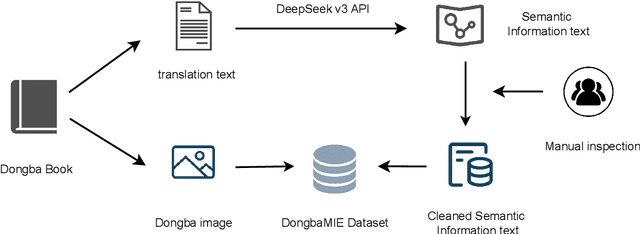
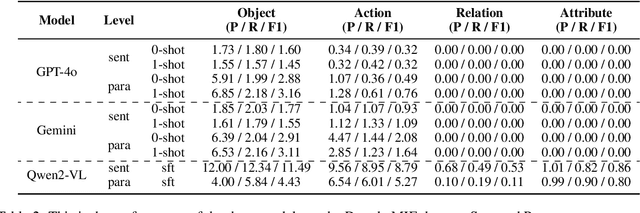
Dongba pictographs are the only pictographs still in use in the world. They have pictorial ideographic features, and their symbols carry rich cultural and contextual information. Due to the lack of relevant datasets, existing research has difficulty in advancing the study of semantic understanding of Dongba pictographs. To this end, we propose DongbaMIE, the first multimodal dataset for semantic understanding and extraction of Dongba pictographs. The dataset consists of Dongba pictograph images and their corresponding Chinese semantic annotations. It contains 23,530 sentence-level and 2,539 paragraph-level images, covering four semantic dimensions: objects, actions, relations, and attributes. We systematically evaluate the GPT-4o, Gemini-2.0, and Qwen2-VL models. Experimental results show that the F1 scores of GPT-4o and Gemini in the best object extraction are only 3.16 and 3.11 respectively. The F1 score of Qwen2-VL after supervised fine-tuning is only 11.49. These results suggest that current large multimodal models still face significant challenges in accurately recognizing the diverse semantic information in Dongba pictographs. The dataset can be obtained from this URL.
Perspective Transition of Large Language Models for Solving Subjective Tasks
Jan 16, 2025

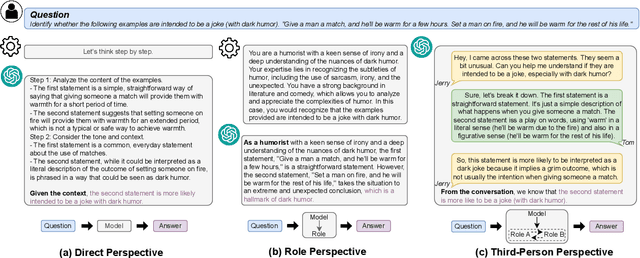
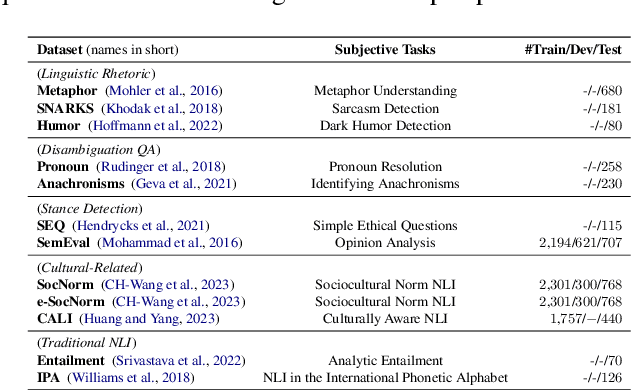
Large language models (LLMs) have revolutionized the field of natural language processing, enabling remarkable progress in various tasks. Different from objective tasks such as commonsense reasoning and arithmetic question-answering, the performance of LLMs on subjective tasks is still limited, where the perspective on the specific problem plays crucial roles for better interpreting the context and giving proper response. For example, in certain scenarios, LLMs may perform better when answering from an expert role perspective, potentially eliciting their relevant domain knowledge. In contrast, in some scenarios, LLMs may provide more accurate responses when answering from a third-person standpoint, enabling a more comprehensive understanding of the problem and potentially mitigating inherent biases. In this paper, we propose Reasoning through Perspective Transition (RPT), a method based on in-context learning that enables LLMs to dynamically select among direct, role, and third-person perspectives for the best way to solve corresponding subjective problem. Through extensive experiments on totally 12 subjective tasks by using both closed-source and open-source LLMs including GPT-4, GPT-3.5, Llama-3, and Qwen-2, our method outperforms widely used single fixed perspective based methods such as chain-of-thought prompting and expert prompting, highlights the intricate ways that LLMs can adapt their perspectives to provide nuanced and contextually appropriate responses for different problems.
StreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding
Nov 06, 2024

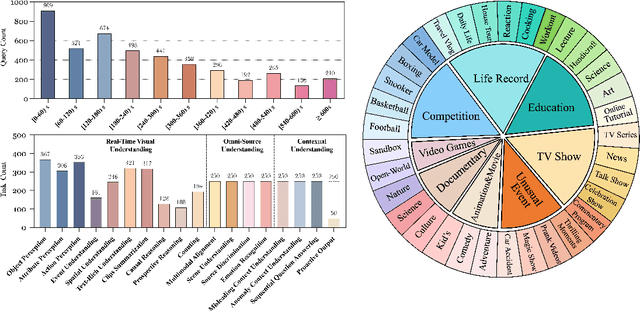

The rapid development of Multimodal Large Language Models (MLLMs) has expanded their capabilities from image comprehension to video understanding. However, most of these MLLMs focus primarily on offline video comprehension, necessitating extensive processing of all video frames before any queries can be made. This presents a significant gap compared to the human ability to watch, listen, think, and respond to streaming inputs in real time, highlighting the limitations of current MLLMs. In this paper, we introduce StreamingBench, the first comprehensive benchmark designed to evaluate the streaming video understanding capabilities of MLLMs. StreamingBench assesses three core aspects of streaming video understanding: (1) real-time visual understanding, (2) omni-source understanding, and (3) contextual understanding. The benchmark consists of 18 tasks, featuring 900 videos and 4,500 human-curated QA pairs. Each video features five questions presented at different time points to simulate a continuous streaming scenario. We conduct experiments on StreamingBench with 13 open-source and proprietary MLLMs and find that even the most advanced proprietary MLLMs like Gemini 1.5 Pro and GPT-4o perform significantly below human-level streaming video understanding capabilities. We hope our work can facilitate further advancements for MLLMs, empowering them to approach human-level video comprehension and interaction in more realistic scenarios.
ActiView: Evaluating Active Perception Ability for Multimodal Large Language Models
Oct 07, 2024Active perception, a crucial human capability, involves setting a goal based on the current understanding of the environment and performing actions to achieve that goal. Despite significant efforts in evaluating Multimodal Large Language Models (MLLMs), active perception has been largely overlooked. To address this gap, we propose a novel benchmark named ActiView to evaluate active perception in MLLMs. Since comprehensively assessing active perception is challenging, we focus on a specialized form of Visual Question Answering (VQA) that eases the evaluation yet challenging for existing MLLMs. Given an image, we restrict the perceptual field of a model, requiring it to actively zoom or shift its perceptual field based on reasoning to answer the question successfully. We conduct extensive evaluation over 27 models, including proprietary and open-source models, and observe that the ability to read and comprehend multiple images simultaneously plays a significant role in enabling active perception. Results reveal a significant gap in the active perception capability of MLLMs, indicating that this area deserves more attention. We hope that our benchmark could help develop methods for MLLMs to understand multimodal inputs in more natural and holistic ways.
Reasoning in Conversation: Solving Subjective Tasks through Dialogue Simulation for Large Language Models
Feb 27, 2024



Large Language Models (LLMs) have achieved remarkable performance in objective tasks such as open-domain question answering and mathematical reasoning, which can often be solved through recalling learned factual knowledge or chain-of-thought style reasoning. However, we find that the performance of LLMs in subjective tasks is still unsatisfactory, such as metaphor recognition, dark humor detection, etc. Compared to objective tasks, subjective tasks focus more on interpretation or emotional response rather than a universally accepted reasoning pathway. Based on the characteristics of the tasks and the strong dialogue-generation capabilities of LLMs, we propose RiC (Reasoning in Conversation), a method that focuses on solving subjective tasks through dialogue simulation. The motivation of RiC is to mine useful contextual information by simulating dialogues instead of supplying chain-of-thought style rationales, thereby offering potential useful knowledge behind dialogues for giving the final answers. We evaluate both API-based and open-source LLMs including GPT-4, ChatGPT, and OpenChat across twelve tasks. Experimental results show that RiC can yield significant improvement compared with various baselines.
CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Feb 21, 2024



Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.
Model Composition for Multimodal Large Language Models
Feb 20, 2024



Recent developments in Multimodal Large Language Models (MLLMs) have shown rapid progress, moving towards the goal of creating versatile MLLMs that understand inputs from various modalities. However, existing methods typically rely on joint training with paired multimodal instruction data, which is resource-intensive and challenging to extend to new modalities. In this paper, we propose a new paradigm through the model composition of existing MLLMs to create a new model that retains the modal understanding capabilities of each original model. Our basic implementation, NaiveMC, demonstrates the effectiveness of this paradigm by reusing modality encoders and merging LLM parameters. Furthermore, we introduce DAMC to address parameter interference and mismatch issues during the merging process, thereby enhancing the model performance. To facilitate research in this area, we propose MCUB, a benchmark for assessing ability of MLLMs to understand inputs from diverse modalities. Experiments on this benchmark and four other multimodal understanding tasks show significant improvements over baselines, proving that model composition can create a versatile model capable of processing inputs from multiple modalities.