 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DRaL: Bridging 4D Radar with LiDAR for Place Recognition using Knowledge Distillation
Mar 27, 2026Place recognition is crucial for loop closure detection and global localization in robotics. Although mainstream algorithms typically rely on cameras and LiDAR, these sensors are susceptible to adverse weather conditions. Fortunately, the recently developed 4D millimeter-wave radar (4D radar) offers a promising solution for all-weather place recognition. However, the inherent noise and sparsity in 4D radar data significantly limit its performance. Thus, in this paper, we propose a novel framework called 4DRaL that leverages knowledge distillation (KD) to enhance the place recognition performance of 4D radar. Its core is to adopt a high-performance LiDAR-to-LiDAR (L2L) place recognition model as a teacher to guide the training of a 4D radar-to-4D radar (R2R) place recognition model. 4DRaL comprises three key KD modules: a local image enhancement module to handle the sparsity of raw 4D radar points, a feature distribution distillation module that ensures the student model generates more discriminative features, and a response distillation module to maintain consistency in feature space between the teacher and student models. More importantly, 4DRaL can also be trained for 4D radar-to-LiDAR (R2L) place recognition through different module configurations. Experimental results prove that 4DRaL achieves state-of-the-art performance in both R2R and R2L tasks regardless of normal or adverse weather.
SurgFed: Language-guided Multi-Task Federated Learning for Surgical Video Understanding
Mar 10, 2026Surgical scene Multi-Task Federated Learning (MTFL) is essential for robot-assisted minimally invasive surgery (RAS) but remains underexplored in surgical video understanding due to two key challenges: (1) Tissue Diversity: Local models struggle to adapt to site-specific tissue features, limiting their effectiveness in heterogeneous clinical environments and leading to poor local predictions. (2) Task Diversity: Server-side aggregation, relying solely on gradient-based clustering, often produces suboptimal or incorrect parameter updates due to inter-site task heterogeneity, resulting in inaccurate localization. In light of these two issues, we propose SurgFed, a multi-task federated learning framework, enabling federated learning for surgical scene segmentation and depth estimation across diverse surgical types. SurgFed is powered by two appealing designs, i.e., Language-guided Channel Selection (LCS) and Language-guided Hyper Aggregation (LHA), to address the challenge of fully exploration on corss-site and cross-task. Technically, the LCS is first designed a lightweight personalized channel selection network that enhances site-specific adaptation using pre-defined text inputs, which optimally the local model learn the specific embeddings. We further introduce the LHA that employs a layer-wise cross-attention mechanism with pre-defined text inputs to model task interactions across sites and guide a hypernetwork for personalized parameter updates. Extensive empirical evidence shows that SurgFed yields improvements over the state-of-the-art methods in five public datasets across four surgical types. The code is available at https://anonymous.4open.science/r/SurgFed-070E/.
Devling into Adversarial Transferability on Image Classification: Review, Benchmark, and Evaluation
Feb 26, 2026Adversarial transferability refers to the capacity of adversarial examples generated on the surrogate model to deceive alternate, unexposed victim models. This property eliminates the need for direct access to the victim model during an attack, thereby raising considerable security concerns in practical applications and attracting substantial research attention recently. In this work, we discern a lack of a standardized framework and criteria for evaluating transfer-based attacks, leading to potentially biased assessments of existing approaches. To rectify this gap, we have conducted an exhaustive review of hundreds of related works, organizing various transfer-based attacks into six distinct categories. Subsequently, we propose a comprehensive framework designed to serve as a benchmark for evaluating these attacks. In addition, we delineate common strategies that enhance adversarial transferability and highlight prevalent issues that could lead to unfair comparisons. Finally, we provide a brief review of transfer-based attacks beyond image classification.
MetaToolAgent: Towards Generalizable Tool Usage in LLMs through Meta-Learning
Jan 19, 2026Tool learning is increasingly important for large language models (LLMs) to effectively coordinate and utilize a diverse set of tools in order to solve complex real-world tasks. By selecting and integrating appropriate tools, LLMs extend their capabilities beyond pure language understanding to perform specialized functions. However, existing methods for tool selection often focus on limited tool sets and struggle to generalize to novel tools encountered in practical deployments. To address these challenges, we introduce a comprehensive dataset spanning 7 domains, containing 155 tools and 9,377 question-answer pairs, which simulates realistic integration scenarios. Additionally, we propose MetaToolAgent (MTA), a meta-learning approach designed to improve cross-tool generalization. Experimental results show that MTA significantly outperforms baseline methods on unseen tools, demonstrating its promise for building flexible and scalable systems that require dynamic tool coordination.
Super4DR: 4D Radar-centric Self-supervised Odometry and Gaussian-based Map Optimization
Dec 10, 2025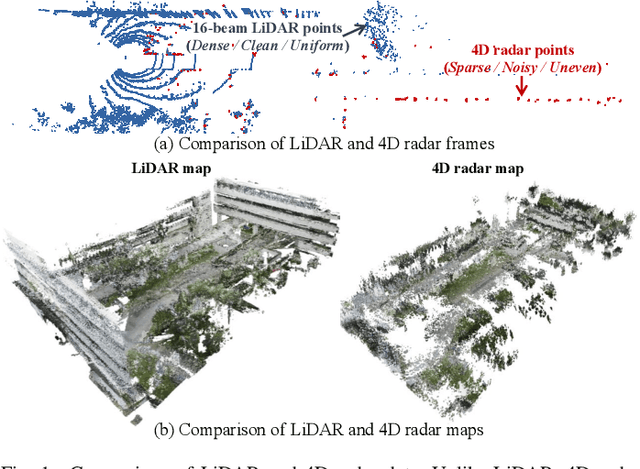
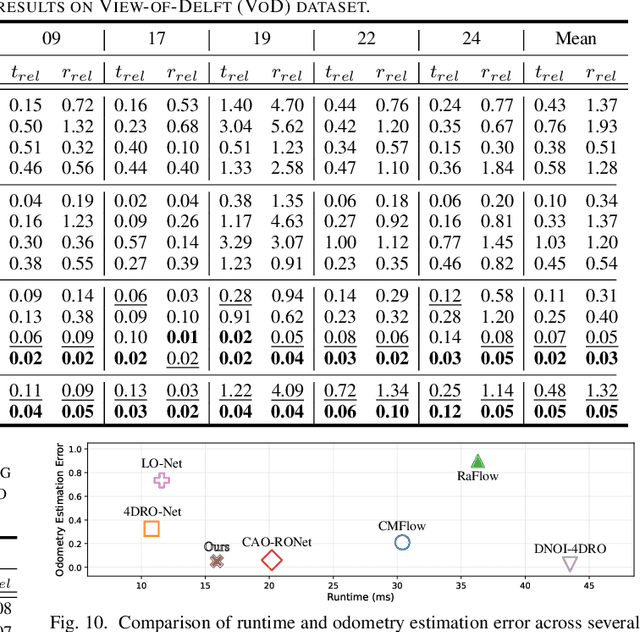
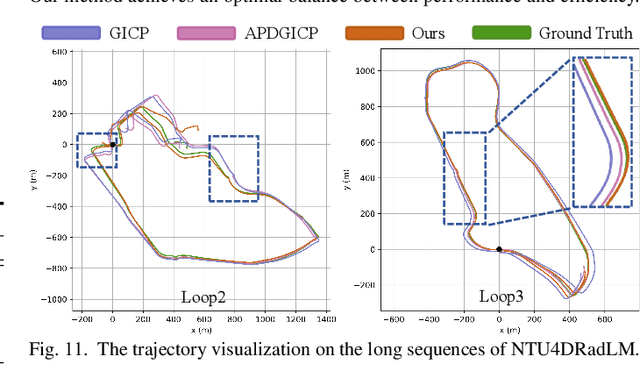

Conventional SLAM systems using visual or LiDAR data often struggle in poor lighting and severe weather. Although 4D radar is suited for such environments, its sparse and noisy point clouds hinder accurate odometry estimation, while the radar maps suffer from obscure and incomplete structures. Thus, we propose Super4DR, a 4D radar-centric framework for learning-based odometry estimation and gaussian-based map optimization. First, we design a cluster-aware odometry network that incorporates object-level cues from the clustered radar points for inter-frame matching, alongside a hierarchical self-supervision mechanism to overcome outliers through spatio-temporal consistency, knowledge transfer, and feature contrast. Second, we propose using 3D gaussians as an intermediate representation, coupled with a radar-specific growth strategy, selective separation, and multi-view regularization, to recover blurry map areas and those undetected based on image texture. Experiments show that Super4DR achieves a 67% performance gain over prior self-supervised methods, nearly matches supervised odometry, and narrows the map quality disparity with LiDAR while enabling multi-modal image rendering.
Debiased Bayesian Inference for High-dimensional Regression Models
Dec 10, 2025There has been significant progress in Bayesian inference based on sparsity-inducing (e.g., spike-and-slab and horseshoe-type) priors for high-dimensional regression models. The resulting posteriors, however, in general do not possess desirable frequentist properties, and the credible sets thus cannot serve as valid confidence sets even asymptotically. We introduce a novel debiasing approach that corrects the bias for the entire Bayesian posterior distribution. We establish a new Bernstein-von Mises theorem that guarantees the frequentist validity of the debiased posterior. We demonstrate the practical performance of our proposal through Monte Carlo simulations and two empirical applications in economics.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
Towards 3D Object-Centric Feature Learning for Semantic Scene Completion
Nov 18, 2025Vision-based 3D Semantic Scene Completion (SSC) has received growing attention due to its potential in autonomous driving. While most existing approaches follow an ego-centric paradigm by aggregating and diffusing features over the entire scene, they often overlook fine-grained object-level details, leading to semantic and geometric ambiguities, especially in complex environments. To address this limitation, we propose Ocean, an object-centric prediction framework that decomposes the scene into individual object instances to enable more accurate semantic occupancy prediction. Specifically, we first employ a lightweight segmentation model, MobileSAM, to extract instance masks from the input image. Then, we introduce a 3D Semantic Group Attention module that leverages linear attention to aggregate object-centric features in 3D space. To handle segmentation errors and missing instances, we further design a Global Similarity-Guided Attention module that leverages segmentation features for global interaction. Finally, we propose an Instance-aware Local Diffusion module that improves instance features through a generative process and subsequently refines the scene representation in the BEV space. Extensive experiments on the SemanticKITTI and SSCBench-KITTI360 benchmarks demonstrate that Ocean achieves state-of-the-art performance, with mIoU scores of 17.40 and 20.28, respectively.
RadioDUN: A Physics-Inspired Deep Unfolding Network for Radio Map Estimation
Jun 10, 2025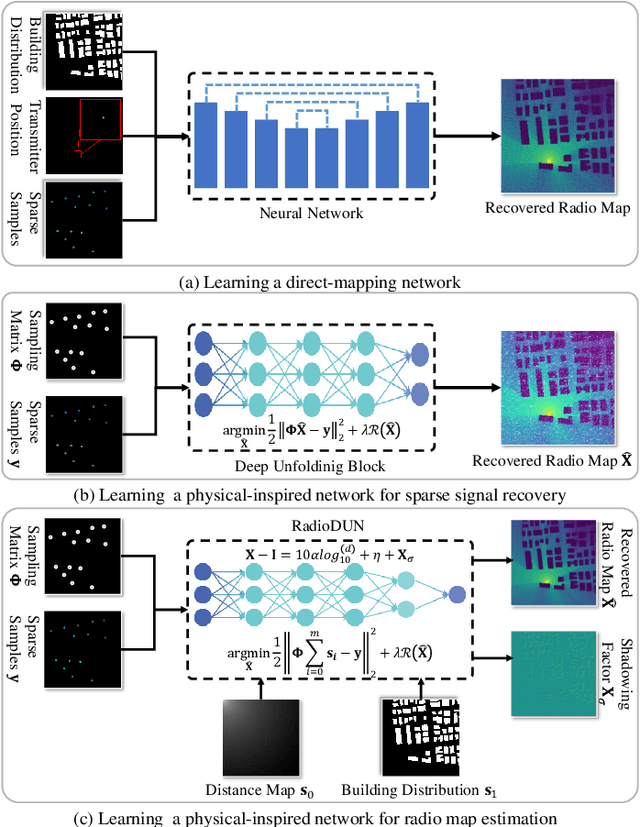

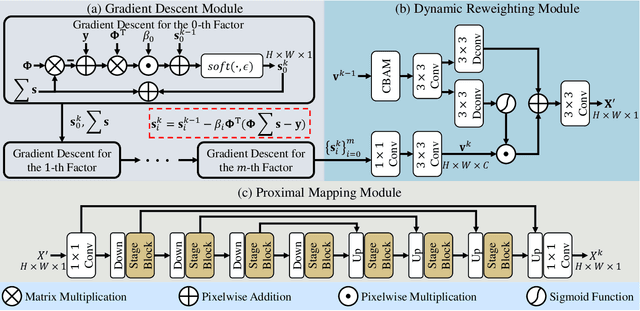
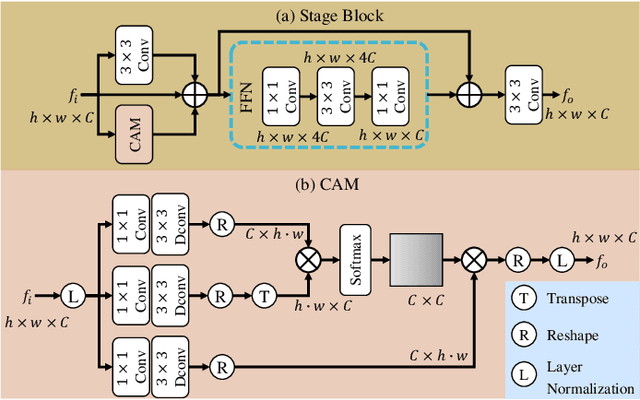
The radio map represents the spatial distribution of spectrum resources within a region, supporting efficient resource allocation and interference mitigation. However, it is difficult to construct a dense radio map as a limited number of samples can be measured in practical scenarios. While existing works have used deep learning to estimate dense radio maps from sparse samples, they are hard to integrate with the physical characteristics of the radio map. To address this challenge, we cast radio map estimation as the sparse signal recovery problem. A physical propagation model is further incorporated to decompose the problem into multiple factor optimization sub-problems, thereby reducing recovery complexity. Inspired by the existing compressive sensing methods, we propose the Radio Deep Unfolding Network (RadioDUN) to unfold the optimization process, achieving adaptive parameter adjusting and prior fitting in a learnable manner. To account for the radio propagation characteristics, we develop a dynamic reweighting module (DRM) to adaptively model the importance of each factor for the radio map. Inspired by the shadowing factor in the physical propagation model, we integrate obstacle-related factors to express the obstacle-induced signal stochastic decay. The shadowing loss is further designed to constrain the factor prediction and act as a supplementary supervised objective, which enhances the performance of RadioDUN. Extensive experiments have been conducted to demonstrate that the proposed method outperforms the state-of-the-art methods. Our code will be made publicly available upon publication.
A Novel, Human-in-the-Loop Computational Grounded Theory Framework for Big Social Data
Jun 06, 2025The availability of big data has significantly influenced the possibilities and methodological choices for conducting large-scale behavioural and social science research. In the context of qualitative data analysis, a major challenge is that conventional methods require intensive manual labour and are often impractical to apply to large datasets. One effective way to address this issue is by integrating emerging computational methods to overcome scalability limitations. However, a critical concern for researchers is the trustworthiness of results when Machine Learning (ML) and Natural Language Processing (NLP) tools are used to analyse such data. We argue that confidence in the credibility and robustness of results depends on adopting a 'human-in-the-loop' methodology that is able to provide researchers with control over the analytical process, while retaining the benefits of using ML and NLP. With this in mind, we propose a novel methodological framework for Computational Grounded Theory (CGT) that supports the analysis of large qualitative datasets, while maintaining the rigour of established Grounded Theory (GT) methodologies. To illustrate the framework's value, we present the results of testing it on a dataset collected from Reddit in a study aimed at understanding tutors' experiences in the gig economy.