 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval
Apr 02, 2025Traditional sparse and dense retrieval methods struggle to leverage general world knowledge and often fail to capture the nuanced features of queries and products. With the advent of large language models (LLMs), industrial search systems have started to employ LLMs to generate identifiers for product retrieval. Commonly used identifiers include (1) static/semantic IDs and (2) product term sets. The first approach requires creating a product ID system from scratch, missing out on the world knowledge embedded within LLMs. While the second approach leverages this general knowledge, the significant difference in word distribution between queries and products means that product-based identifiers often do not align well with user search queries, leading to missed product recalls. Furthermore, when queries contain numerous attributes, these algorithms generate a large number of identifiers, making it difficult to assess their quality, which results in low overall recall efficiency. To address these challenges, this paper introduces a novel e-commerce retrieval paradigm: the Generative Retrieval and Alignment Model (GRAM). GRAM employs joint training on text information from both queries and products to generate shared text identifier codes, effectively bridging the gap between queries and products. This approach not only enhances the connection between queries and products but also improves inference efficiency. The model uses a co-alignment strategy to generate codes optimized for maximizing retrieval efficiency. Additionally, it introduces a query-product scoring mechanism to compare product values across different codes, further boosting retrieval efficiency. Extensive offline and online A/B testing demonstrates that GRAM significantly outperforms traditional models and the latest generative retrieval models, confirming its effectiveness and practicality.
Unsupervised Distractor Generation via Large Language Model Distilling and Counterfactual Contrastive Decoding
Jun 03, 2024



Within the context of reading comprehension, the task of Distractor Generation (DG) aims to generate several incorrect options to confuse readers. Traditional supervised methods for DG rely heavily on expensive human-annotated distractor labels. In this paper, we propose an unsupervised DG framework, leveraging Large Language Models (LLMs) as cost-effective annotators to enhance the DG capability of smaller student models. Specially, to perform knowledge distilling, we propose a dual task training strategy that integrates pseudo distractors from LLMs and the original answer in-formation as the objective targets with a two-stage training process. Moreover, we devise a counterfactual contrastive decoding mechanism for increasing the distracting capability of the DG model. Experiments show that our unsupervised generation method with Bart-base greatly surpasses GPT-3.5-turbo performance with only 200 times fewer model parameters. Our proposed unsupervised DG method offers a cost-effective framework for practical reading comprehension applications, without the need of laborious distractor annotation and costly large-size models
Ungrammatical-syntax-based In-context Example Selection for Grammatical Error Correction
Mar 28, 2024In the era of large language models (LLMs), in-context learning (ICL) stands out as an effective prompting strategy that explores LLMs' potency across various tasks. However, applying LLMs to grammatical error correction (GEC) is still a challenging task. In this paper, we propose a novel ungrammatical-syntax-based in-context example selection strategy for GEC. Specifically, we measure similarity of sentences based on their syntactic structures with diverse algorithms, and identify optimal ICL examples sharing the most similar ill-formed syntax to the test input. Additionally, we carry out a two-stage process to further improve the quality of selection results. On benchmark English GEC datasets, empirical results show that our proposed ungrammatical-syntax-based strategies outperform commonly-used word-matching or semantics-based methods with multiple LLMs. This indicates that for a syntax-oriented task like GEC, paying more attention to syntactic information can effectively boost LLMs' performance. Our code will be publicly available after the publication of this paper.
Mixture-of-Prompt-Experts for Multi-modal Semantic Understanding
Mar 24, 2024Deep multimodal semantic understanding that goes beyond the mere superficial content relation mining has received increasing attention in the realm of artificial intelligence. The challenges of collecting and annotating high-quality multi-modal data have underscored the significance of few-shot learning. In this paper, we focus on two critical tasks under this context: few-shot multi-modal sarcasm detection (MSD) and multi-modal sentiment analysis (MSA). To address them, we propose Mixture-of-Prompt-Experts with Block-Aware Prompt Fusion (MoPE-BAF), a novel multi-modal soft prompt framework based on the unified vision-language model (VLM). Specifically, we design three experts of soft prompts: a text prompt and an image prompt that extract modality-specific features to enrich the single-modal representation, and a unified prompt to assist multi-modal interaction. Additionally, we reorganize Transformer layers into several blocks and introduce cross-modal prompt attention between adjacent blocks, which smoothens the transition from single-modal representation to multi-modal fusion. On both MSD and MSA datasets in few-shot setting, our proposed model not only surpasses the 8.2B model InstructBLIP with merely 2% parameters (150M), but also significantly outperforms other widely-used prompt methods on VLMs or task-specific methods.
Evaluating the Capability of Large-scale Language Models on Chinese Grammatical Error Correction Task
Jul 08, 2023Large-scale language models (LLMs) has shown remarkable capability in various of Natural Language Processing (NLP) tasks and attracted lots of attention recently. However, some studies indicated that large language models fail to achieve promising result beyond the state-of-the-art models in English grammatical error correction (GEC) tasks. In this report, we aim to explore the how large language models perform on Chinese grammatical error correction tasks and provide guidance for future work. We conduct experiments with 3 different LLMs of different model scale on 4 Chinese GEC dataset. Our experimental results indicate that the performances of LLMs on automatic evaluation metrics falls short of the previous sota models because of the problem of over-correction. Furthermore, we also discover notable variations in the performance of LLMs when evaluated on different data distributions. Our findings demonstrates that further investigation is required for the application of LLMs on Chinese GEC task.
Enhancing Pre-trained Models with Text Structure Knowledge for Question Generation
Sep 09, 2022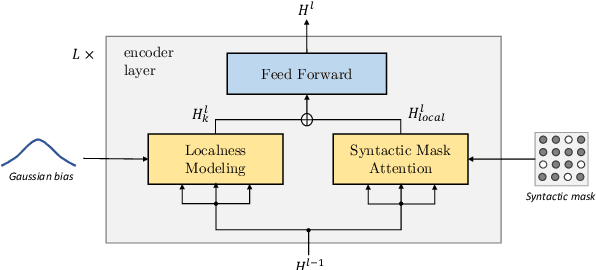
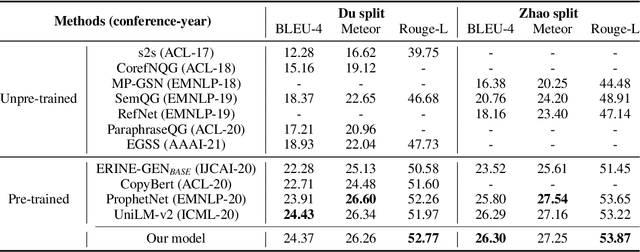
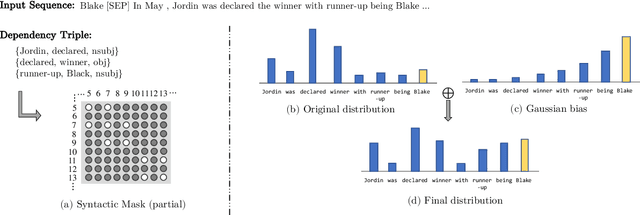

Today the pre-trained language models achieve great success for question generation (QG) task and significantly outperform traditional sequence-to-sequence approaches. However, the pre-trained models treat the input passage as a flat sequence and are thus not aware of the text structure of input passage. For QG task, we model text structure as answer position and syntactic dependency, and propose answer localness modeling and syntactic mask attention to address these limitations. Specially, we present localness modeling with a Gaussian bias to enable the model to focus on answer-surrounded context, and propose a mask attention mechanism to make the syntactic structure of input passage accessible in question generation process. Experiments on SQuAD dataset show that our proposed two modules improve performance over the strong pre-trained model ProphetNet, and combing them together achieves very competitive results with the state-of-the-art pre-trained model.
Asking Questions Like Educational Experts: Automatically Generating Question-Answer Pairs on Real-World Examination Data
Sep 17, 2021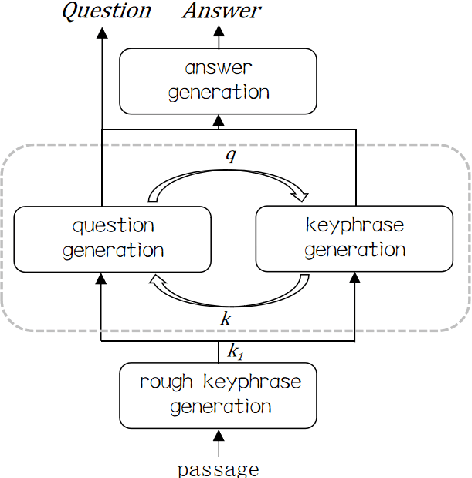
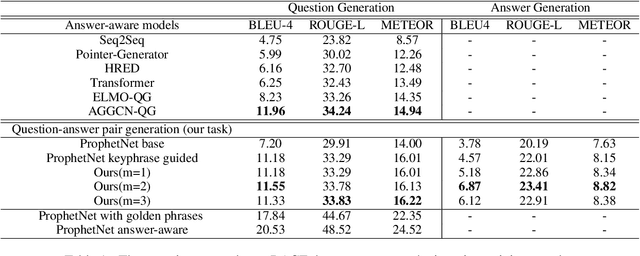

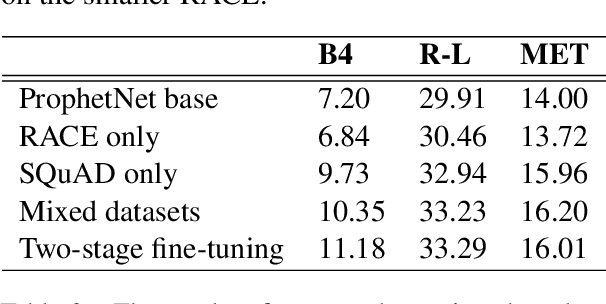
Generating high quality question-answer pairs is a hard but meaningful task. Although previous works have achieved great results on answer-aware question generation, it is difficult to apply them into practical application in the education field. This paper for the first time addresses the question-answer pair generation task on the real-world examination data, and proposes a new unified framework on RACE. To capture the important information of the input passage we first automatically generate(rather than extracting) keyphrases, thus this task is reduced to keyphrase-question-answer triplet joint generation. Accordingly, we propose a multi-agent communication model to generate and optimize the question and keyphrases iteratively, and then apply the generated question and keyphrases to guide the generation of answers. To establish a solid benchmark, we build our model on the strong generative pre-training model. Experimental results show that our model makes great breakthroughs in the question-answer pair generation task. Moreover, we make a comprehensive analysis on our model, suggesting new directions for this challenging task.