 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADWIN: Adaptive Windows for Horizon-Aware On-Policy Distillation
May 27, 2026On-policy distillation (OPD) transfers reasoning behavior by training a student on teacher feedback along student-generated trajectories, but standard full-rollout training ties every update to a costly completion and can over-allocate supervision to late positions with low marginal value for the current student. We revisit this assumption through the useful supervision horizon: student-induced rollouts can drift from teacher-preferred continuations, while aligned prefixes may already preserve the long-horizon OPD update direction. We propose ADWIN, an adaptive-window framework for OPD that treats rollout length as an online admissibility decision, training on short teacher-anchored prefixes while using delayed full-rollout probes to audit prefix--full alignment and adapt the next horizon with staleness control. Across math and code reasoning benchmarks in single-task, multi-task, and strong-to-weak settings, ADWIN improves the accuracy--compute trade-off over full-rollout OPD and prefix-based baselines, reducing end-to-end training cost by up to 4.1 times while achieving comparable or better accuracy.
RLVR Datasets and Where to Find Them: Tracing Data Lineage for Better Training Data
May 26, 2026The proliferation of Reinforcement Learning from Verifiable Rewards (RLVR) datasets has exacerbated provenance collapse due to unclear lineage among existing datasets. To bridge this fragmented RLVR data landscape, we propose Atomic-source Tracing via Lineage-Aware Search (ATLAS), a systematic framework for tracing RLVR datasets back to their atomic sources, attributing over 99.7% of 1.45M instances to 20 atomic sources. Our analysis reveals that most RLVR datasets are variants of a small set of shared upstream sources, with few introducing genuinely new data, and many facing data contamination risks. These findings naturally motivate us to curate a new RLVR dataset, DAPO++, and to benchmark existing datasets from a lineage-aware perspective. To this end, we propose Source-level Counterfactual Attribution (SCA) as a guiding principle to curate a decontaminated training dataset with concentrated learning signals. Essentially, SCA measures a sample's marginal utility by comparing per-atomic-source RL checkpoints against a shared base model. Building upon these attribution signals, we further design a composite dataset quality score Q that strongly correlates with downstream RLVR performance. Experiments on Qwen3 series models verify that DAPO++ consistently improves performance on held-out benchmarks, while Q reliably predicts downstream RLVR training effectiveness. Our code and data is available at https://github.com/Celine-hxy/ATLAS.
Tool Learning Needs Nothing More Than a Free 8B Language Model
Apr 20, 2026Reinforcement learning (RL) has become a prevalent paradigm for training tool calling agents, which typically requires online interactive environments. Existing approaches either rely on training data with ground truth annotations or require advanced commercial language models (LMs) to synthesize environments that keep fixed once created. In this work, we propose TRUSTEE, a data-free method training tool calling agents with dynamic environments fully simulated by free open-source LMs that can be as small as 8B, including task generation, user simulation, tool simulation and trajectory evaluation, paired with an adaptive curriculum learning mechanism that controls various aspects of the task difficulty dynamically during training. Our empirical results show that TRUSTEE brings consistent improvements across various domains and outperforms all the baselines which require extra external resources for training. These confirm that, with a sufficiently sophisticated design, even simulated environments with a local 8B LM as the backbone could set a strong baseline for tool learning, without expensive annotated data, realistic human interactions, executable tools or costly verifiable environments from human experts or commercial LMs. We hope our proposed paradigm could inspire future research on environment scaling with limited resources.
ORBIT: On-policy Exploration-Exploitation for Controllable Multi-Budget Reasoning
Jan 13, 2026Recent Large Reasoning Models (LRMs) achieve strong performance by leveraging long-form Chain-of-Thought (CoT) reasoning, but uniformly applying overlong reasoning at inference time incurs substantial and often unnecessary computational cost. To address this, prior work explores various strategies to infer an appropriate reasoning budget from the input. However, such approaches are unreliable in the worst case, as estimating the minimal required reasoning effort is fundamentally difficult, and they implicitly fix the trade-off between reasoning cost and accuracy during training, limiting flexibility under varying deployment scenarios. Motivated by these limitations, we propose ORBIT, a controllable multi-budget reasoning framework with well-separated reasoning modes triggered by input. ORBIT employs multi-stage reinforcement learning to discover Pareto-optimal reasoning behaviors at each effort, followed by on-policy distillation to fuse these behaviors into a single unified model. Experiments show that ORBIT achieves (1) controllable reasoning behavior over multiple modes, (2) competitive reasoning density within each mode, and (3) integration of these frontier policies into a single unified student model while preserving clear mode separation and high per-mode performance.
Think Outside the Policy: In-Context Steered Policy Optimization
Oct 30, 2025Existing Reinforcement Learning from Verifiable Rewards (RLVR) methods, such as Group Relative Policy Optimization (GRPO), have achieved remarkable progress in improving the reasoning capabilities of Large Reasoning Models (LRMs). However, they exhibit limited exploration due to reliance on on-policy rollouts where confined to the current policy's distribution, resulting in narrow trajectory diversity. Recent approaches attempt to expand policy coverage by incorporating trajectories generated from stronger expert models, yet this reliance increases computational cost and such advaned models are often inaccessible. To address these issues, we propose In-Context Steered Policy Optimization (ICPO), a unified framework that leverages the inherent in-context learning capability of LRMs to provide expert guidance using existing datasets. ICPO introduces Mixed-Policy GRPO with Implicit Expert Forcing, which expands exploration beyond the current policy distribution without requiring advanced LRM trajectories. To further stabilize optimization, ICPO integrates Expert Region Reject Sampling to filter unreliable off-policy trajectories and Annealed Expert-Bonus Reward Shaping to balance early expert guidance with later autonomous improvement. Results demonstrate that ICPO consistently enhances reinforcement learning performance and training stability on mathematical reasoning benchmarks, revealing a scalable and effective RLVR paradigm for LRMs.
Do Not Step Into the Same River Twice: Learning to Reason from Trial and Error
Oct 30, 2025Reinforcement learning with verifiable rewards (RLVR) has significantly boosted the reasoning capability of large language models (LLMs) recently. However, existing RLVR approaches merely train LLMs based on their own generated responses and are constrained by the initial capability of LLMs, thus prone to exploration stagnation, in which LLMs fail to solve more training problems and cannot further learn from the training data. Some work tries to address this by leveraging off-policy solutions to training problems but requires external guidance from experts which suffers from limited availability. In this work, we propose LTE (Learning to reason from Trial and Error), an approach hinting LLMs with their previously self-generated incorrect answers and problem of overlong responses, which does not require any external expert guidance. Experiments validate the effectiveness of LTE, which outperforms the normal group relative policy optimization (GRPO) by 6.38 in Pass@1 and 9.00 in Pass@k on average across six mathematics benchmarks for Qwen3-4B-Base. Further analysis confirms that LTE successfully mitigates the problem of exploration stagnation and enhances both exploitation and exploration during training.
Large Language Models Might Not Care What You Are Saying: Prompt Format Beats Descriptions
Aug 16, 2024
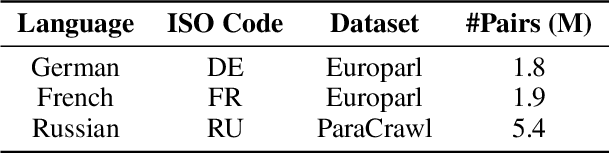

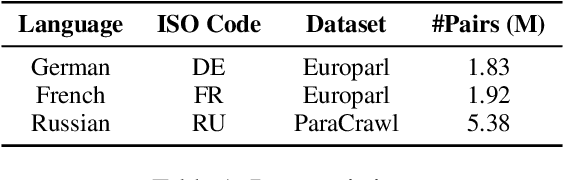
With the help of in-context learning (ICL), large language models (LLMs) have achieved impressive performance across various tasks. However, the function of descriptive instructions during ICL remains under-explored. In this work, we propose an ensemble prompt framework to describe the selection criteria of multiple in-context examples, and preliminary experiments on machine translation (MT) across six translation directions confirm that this framework boosts ICL perfromance. But to our surprise, LLMs might not necessarily care what the descriptions actually say, and the performance gain is primarily caused by the ensemble format, since the framework could lead to improvement even with random descriptive nouns. We further apply this new ensemble prompt on a range of commonsense, math, logical reasoning and hallucination tasks with three LLMs and achieve promising results, suggesting again that designing a proper prompt format would be much more effective and efficient than paying effort into specific descriptions. Our code will be publicly available once this paper is published.
SCOI: Syntax-augmented Coverage-based In-context Example Selection for Machine Translation
Aug 09, 2024

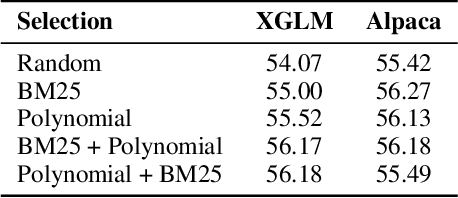
In-context learning (ICL) greatly improves the performance of large language models (LLMs) on various down-stream tasks, where the improvement highly depends on the quality of demonstrations. In this work, we introduce syntactic knowledge to select better in-context examples for machine translation (MT). We propose a new strategy, namely Syntax-augmented COverage-based In-context example selection (SCOI), leveraging the deep syntactic structure beyond conventional word matching. Specifically, we measure the set-level syntactic coverage by computing the coverage of polynomial terms with the help of a simplified tree-to-polynomial algorithm, and lexical coverage using word overlap. Furthermore, we devise an alternate selection approach to combine both coverage measures, taking advantage of syntactic and lexical information. We conduct experiments with two multi-lingual LLMs on six translation directions. Empirical results show that our proposed SCOI obtains the highest average COMET score among all learning-free methods, indicating that combining syntactic and lexical coverage successfully helps to select better in-context examples for MT.
Ungrammatical-syntax-based In-context Example Selection for Grammatical Error Correction
Mar 28, 2024In the era of large language models (LLMs), in-context learning (ICL) stands out as an effective prompting strategy that explores LLMs' potency across various tasks. However, applying LLMs to grammatical error correction (GEC) is still a challenging task. In this paper, we propose a novel ungrammatical-syntax-based in-context example selection strategy for GEC. Specifically, we measure similarity of sentences based on their syntactic structures with diverse algorithms, and identify optimal ICL examples sharing the most similar ill-formed syntax to the test input. Additionally, we carry out a two-stage process to further improve the quality of selection results. On benchmark English GEC datasets, empirical results show that our proposed ungrammatical-syntax-based strategies outperform commonly-used word-matching or semantics-based methods with multiple LLMs. This indicates that for a syntax-oriented task like GEC, paying more attention to syntactic information can effectively boost LLMs' performance. Our code will be publicly available after the publication of this paper.
Going Beyond Word Matching: Syntax Improves In-context Example Selection for Machine Translation
Mar 28, 2024



In-context learning (ICL) is the trending prompting strategy in the era of large language models (LLMs), where a few examples are demonstrated to evoke LLMs' power for a given task. How to select informative examples remains an open issue. Previous works on in-context example selection for machine translation (MT) focus on superficial word-level features while ignoring deep syntax-level knowledge. In this paper, we propose a syntax-based in-context example selection method for MT, by computing the syntactic similarity between dependency trees using Polynomial Distance. In addition, we propose an ensemble strategy combining examples selected by both word-level and syntax-level criteria. Experimental results between English and 6 common languages indicate that syntax can effectively enhancing ICL for MT, obtaining the highest COMET scores on 11 out of 12 translation directions.