 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORBIT: On-policy Exploration-Exploitation for Controllable Multi-Budget Reasoning
Jan 13, 2026Recent Large Reasoning Models (LRMs) achieve strong performance by leveraging long-form Chain-of-Thought (CoT) reasoning, but uniformly applying overlong reasoning at inference time incurs substantial and often unnecessary computational cost. To address this, prior work explores various strategies to infer an appropriate reasoning budget from the input. However, such approaches are unreliable in the worst case, as estimating the minimal required reasoning effort is fundamentally difficult, and they implicitly fix the trade-off between reasoning cost and accuracy during training, limiting flexibility under varying deployment scenarios. Motivated by these limitations, we propose ORBIT, a controllable multi-budget reasoning framework with well-separated reasoning modes triggered by input. ORBIT employs multi-stage reinforcement learning to discover Pareto-optimal reasoning behaviors at each effort, followed by on-policy distillation to fuse these behaviors into a single unified model. Experiments show that ORBIT achieves (1) controllable reasoning behavior over multiple modes, (2) competitive reasoning density within each mode, and (3) integration of these frontier policies into a single unified student model while preserving clear mode separation and high per-mode performance.
SyncThink: A Training-Free Strategy to Align Inference Termination with Reasoning Saturation
Jan 07, 2026Chain-of-Thought (CoT) prompting improves reasoning but often produces long and redundant traces that substantially increase inference cost. We present SyncThink, a training-free and plug-and-play decoding method that reduces CoT overhead without modifying model weights. We find that answer tokens attend weakly to early reasoning and instead focus on the special token "/think", indicating an information bottleneck. Building on this observation, SyncThink monitors the model's own reasoning-transition signal and terminates reasoning. Experiments on GSM8K, MMLU, GPQA, and BBH across three DeepSeek-R1 distilled models show that SyncThink achieves 62.00 percent average Top-1 accuracy using 656 generated tokens and 28.68 s latency, compared to 61.22 percent, 2141 tokens, and 92.01 s for full CoT decoding. On long-horizon tasks such as GPQA, SyncThink can further yield up to +8.1 absolute accuracy by preventing over-thinking.
Safety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis
Jan 07, 2026Safety alignment in Large Language Models (LLMs) inherently presents a multi-objective optimization conflict, often accompanied by an unintended degradation of general capabilities. Existing mitigation strategies typically rely on global gradient geometry to resolve these conflicts, yet they overlook Modular Heterogeneity within Transformers, specifically that the functional sensitivity and degree of conflict vary substantially across different attention heads. Such global approaches impose uniform update rules across all parameters, often resulting in suboptimal trade-offs by indiscriminately updating utility sensitive heads that exhibit intense gradient conflicts. To address this limitation, we propose Conflict-Aware Sparse Tuning (CAST), a framework that integrates head-level diagnosis with sparse fine-tuning. CAST first constructs a pre-alignment conflict map by synthesizing Optimization Conflict and Functional Sensitivity, which then guides the selective update of parameters. Experiments reveal that alignment conflicts in LLMs are not uniformly distributed. We find that the drop in general capabilities mainly comes from updating a small group of ``high-conflict'' heads. By simply skipping these heads during training, we significantly reduce this loss without compromising safety, offering an interpretable and parameter-efficient approach to improving the safety-utility trade-off.
One Tool Is Enough: Reinforcement Learning for Repository-Level LLM Agents
Dec 24, 2025Locating the files and functions requiring modification in large open-source software (OSS) repositories is challenging due to their scale and structural complexity. Existing large language model (LLM)-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool-jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a pretrained model, without any closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and even the 32B model exceeding closed-source models such as Claude-3.7. These results confirm that integrating a single, structurally grounded tool with RL training provides an efficient and scalable solution for repository-level issue localization.
Do Not Step Into the Same River Twice: Learning to Reason from Trial and Error
Oct 30, 2025Reinforcement learning with verifiable rewards (RLVR) has significantly boosted the reasoning capability of large language models (LLMs) recently. However, existing RLVR approaches merely train LLMs based on their own generated responses and are constrained by the initial capability of LLMs, thus prone to exploration stagnation, in which LLMs fail to solve more training problems and cannot further learn from the training data. Some work tries to address this by leveraging off-policy solutions to training problems but requires external guidance from experts which suffers from limited availability. In this work, we propose LTE (Learning to reason from Trial and Error), an approach hinting LLMs with their previously self-generated incorrect answers and problem of overlong responses, which does not require any external expert guidance. Experiments validate the effectiveness of LTE, which outperforms the normal group relative policy optimization (GRPO) by 6.38 in Pass@1 and 9.00 in Pass@k on average across six mathematics benchmarks for Qwen3-4B-Base. Further analysis confirms that LTE successfully mitigates the problem of exploration stagnation and enhances both exploitation and exploration during training.
Think Outside the Policy: In-Context Steered Policy Optimization
Oct 30, 2025Existing Reinforcement Learning from Verifiable Rewards (RLVR) methods, such as Group Relative Policy Optimization (GRPO), have achieved remarkable progress in improving the reasoning capabilities of Large Reasoning Models (LRMs). However, they exhibit limited exploration due to reliance on on-policy rollouts where confined to the current policy's distribution, resulting in narrow trajectory diversity. Recent approaches attempt to expand policy coverage by incorporating trajectories generated from stronger expert models, yet this reliance increases computational cost and such advaned models are often inaccessible. To address these issues, we propose In-Context Steered Policy Optimization (ICPO), a unified framework that leverages the inherent in-context learning capability of LRMs to provide expert guidance using existing datasets. ICPO introduces Mixed-Policy GRPO with Implicit Expert Forcing, which expands exploration beyond the current policy distribution without requiring advanced LRM trajectories. To further stabilize optimization, ICPO integrates Expert Region Reject Sampling to filter unreliable off-policy trajectories and Annealed Expert-Bonus Reward Shaping to balance early expert guidance with later autonomous improvement. Results demonstrate that ICPO consistently enhances reinforcement learning performance and training stability on mathematical reasoning benchmarks, revealing a scalable and effective RLVR paradigm for LRMs.
Beyond Spurious Signals: Debiasing Multimodal Large Language Models via Counterfactual Inference and Adaptive Expert Routing
Sep 18, 2025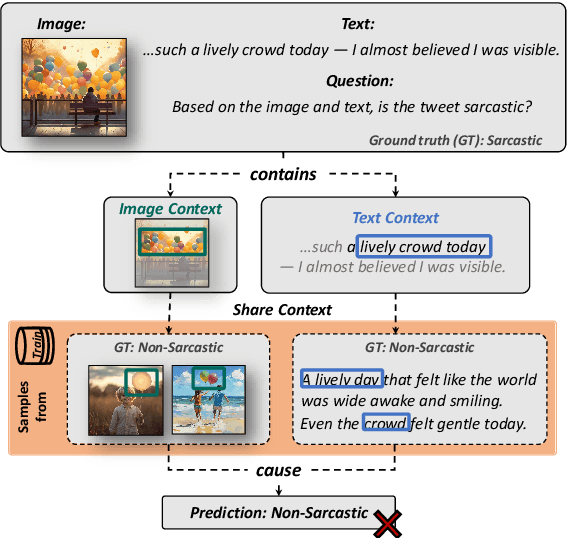

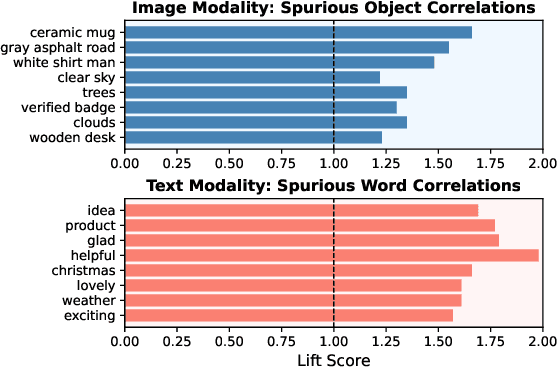
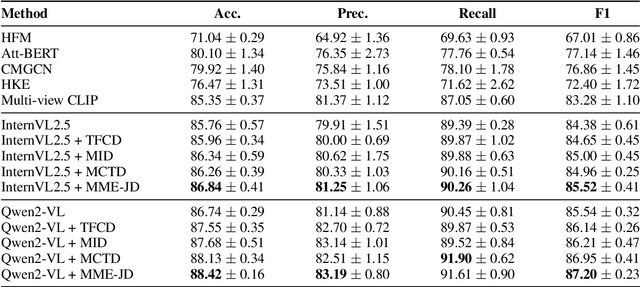
Multimodal Large Language Models (MLLMs) have shown substantial capabilities in integrating visual and textual information, yet frequently rely on spurious correlations, undermining their robustness and generalization in complex multimodal reasoning tasks. This paper addresses the critical challenge of superficial correlation bias in MLLMs through a novel causal mediation-based debiasing framework. Specially, we distinguishing core semantics from spurious textual and visual contexts via counterfactual examples to activate training-stage debiasing and employ a Mixture-of-Experts (MoE) architecture with dynamic routing to selectively engages modality-specific debiasing experts. Empirical evaluation on multimodal sarcasm detection and sentiment analysis tasks demonstrates that our framework significantly surpasses unimodal debiasing strategies and existing state-of-the-art models.
Composable Cross-prompt Essay Scoring by Merging Models
May 24, 2025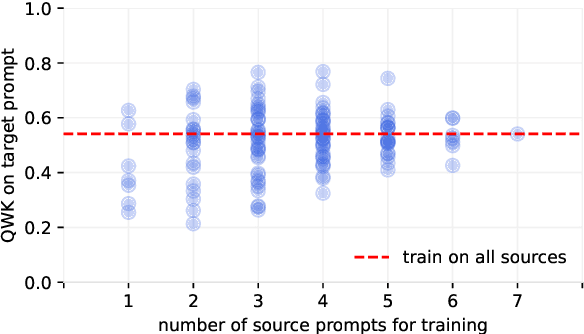

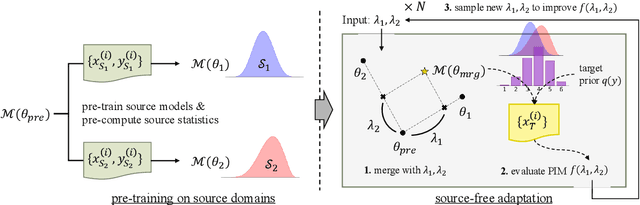
Recent advances in cross-prompt automated essay scoring (AES) typically train models jointly on all source prompts, often requiring additional access to unlabeled target prompt essays simultaneously. However, using all sources is suboptimal in our pilot study, and re-accessing source datasets during adaptation raises privacy concerns. We propose a source-free adaptation approach that selectively merges individually trained source models' parameters instead of datasets. In particular, we simulate joint training through linear combinations of task vectors -- the parameter updates from fine-tuning. To optimize the combination's coefficients, we propose Prior-encoded Information Maximization (PIM), an unsupervised objective which promotes the model's score discriminability regularized by priors pre-computed from the sources. We employ Bayesian optimization as an efficient optimizer of PIM. Experimental results with LLMs on in-dataset and cross-dataset adaptation show that our method (1) consistently outperforms training jointly on all sources, (2) maintains superior robustness compared to other merging methods, (3) excels under severe distribution shifts where recent leading cross-prompt methods struggle, all while retaining computational efficiency.
ThinkLess: A Training-Free Inference-Efficient Method for Reducing Reasoning Redundancy
May 21, 2025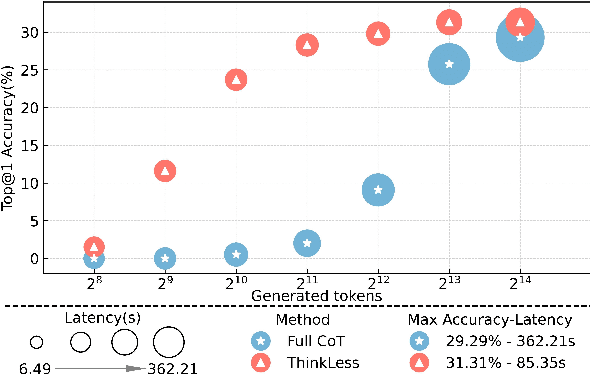
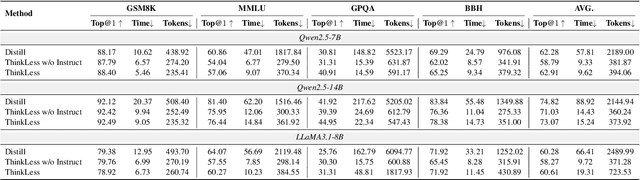
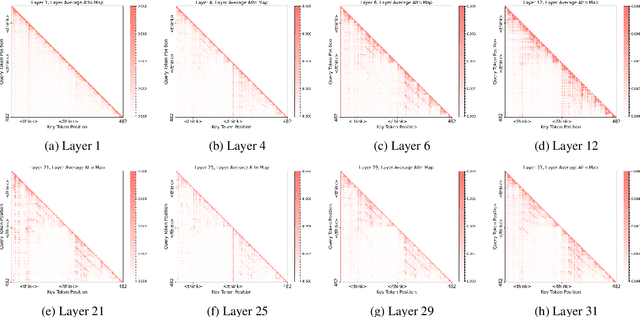

While Chain-of-Thought (CoT) prompting improves reasoning in large language models (LLMs), the excessive length of reasoning tokens increases latency and KV cache memory usage, and may even truncate final answers under context limits. We propose ThinkLess, an inference-efficient framework that terminates reasoning generation early and maintains output quality without modifying the model. Atttention analysis reveals that answer tokens focus minimally on earlier reasoning steps and primarily attend to the reasoning terminator token, due to information migration under causal masking. Building on this insight, ThinkLess inserts the terminator token at earlier positions to skip redundant reasoning while preserving the underlying knowledge transfer. To prevent format discruption casued by early termination, ThinkLess employs a lightweight post-regulation mechanism, relying on the model's natural instruction-following ability to produce well-structured answers. Without fine-tuning or auxiliary data, ThinkLess achieves comparable accuracy to full-length CoT decoding while greatly reducing decoding time and memory consumption.
Dynamic Fisher-weighted Model Merging via Bayesian Optimization
Apr 26, 2025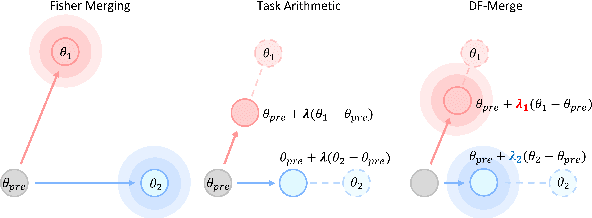



The fine-tuning of pre-trained language models has resulted in the widespread availability of task-specific models. Model merging offers an efficient way to create multi-task models by combining these fine-tuned models at the parameter level, without the need for training data or joint training on multiple datasets. Existing merging approaches typically involve scaling the parameters model-wise or integrating parameter importance parameter-wise. Both approaches exhibit their own weaknesses, leading to a notable performance gap compared to multi-task fine-tuning. In this paper, we unify these seemingly distinct strategies into a more general merging framework, and introduce Dynamic Fisher-weighted Merging (DF-Merge). Specifically, candidate models are associated with a set of coefficients that linearly scale their fine-tuned parameters. Bayesian optimization is applied to dynamically adjust these coefficients, aiming to maximize overall performance on validation sets. Each iteration of this process integrates parameter importance based on the Fisher information conditioned by the coefficients. Experimental results show that DF-Merge outperforms strong baselines across models of different sizes and a variety of tasks. Our analysis shows that the effectiveness of DF-Merge arises from the unified view of merging and that near-optimal performance is achievable in a few iterations, even with minimal validation data.