 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrait-Aware Policy Optimization for Autoregressive Multi-Trait Essay Scoring
May 26, 2026Multi-trait essay scoring aims to provide fine-grained evaluation of writing quality across multiple dimensions. However, how to effectively post-train autoregressive scoring models remains underexplored. In this paper, we propose Trait-Aware Policy Optimization (TAPO), a post-training framework tailored to autoregressive multi-trait scoring. Our method decomposes rewards along both the sample and trait dimensions, combining global scoring consistency, trait-level accuracy, format validity, and inter-trait dependency preservation. In addition, we use enhanced prompts throughout training by incorporating original prompt texts and trait descriptions, providing richer semantic information for trait-specific score generation. Experiments across multiple backbone models show that our method consistently improves multi-trait scoring performance over supervised fine-tuning and scalar-reward optimization baselines, demonstrating the effectiveness and transferability of trait-aware post-training for essay scoring.
RLVR Datasets and Where to Find Them: Tracing Data Lineage for Better Training Data
May 26, 2026The proliferation of Reinforcement Learning from Verifiable Rewards (RLVR) datasets has exacerbated provenance collapse due to unclear lineage among existing datasets. To bridge this fragmented RLVR data landscape, we propose Atomic-source Tracing via Lineage-Aware Search (ATLAS), a systematic framework for tracing RLVR datasets back to their atomic sources, attributing over 99.7% of 1.45M instances to 20 atomic sources. Our analysis reveals that most RLVR datasets are variants of a small set of shared upstream sources, with few introducing genuinely new data, and many facing data contamination risks. These findings naturally motivate us to curate a new RLVR dataset, DAPO++, and to benchmark existing datasets from a lineage-aware perspective. To this end, we propose Source-level Counterfactual Attribution (SCA) as a guiding principle to curate a decontaminated training dataset with concentrated learning signals. Essentially, SCA measures a sample's marginal utility by comparing per-atomic-source RL checkpoints against a shared base model. Building upon these attribution signals, we further design a composite dataset quality score Q that strongly correlates with downstream RLVR performance. Experiments on Qwen3 series models verify that DAPO++ consistently improves performance on held-out benchmarks, while Q reliably predicts downstream RLVR training effectiveness. Our code and data is available at https://github.com/Celine-hxy/ATLAS.
ORBIT: On-policy Exploration-Exploitation for Controllable Multi-Budget Reasoning
Jan 13, 2026Recent Large Reasoning Models (LRMs) achieve strong performance by leveraging long-form Chain-of-Thought (CoT) reasoning, but uniformly applying overlong reasoning at inference time incurs substantial and often unnecessary computational cost. To address this, prior work explores various strategies to infer an appropriate reasoning budget from the input. However, such approaches are unreliable in the worst case, as estimating the minimal required reasoning effort is fundamentally difficult, and they implicitly fix the trade-off between reasoning cost and accuracy during training, limiting flexibility under varying deployment scenarios. Motivated by these limitations, we propose ORBIT, a controllable multi-budget reasoning framework with well-separated reasoning modes triggered by input. ORBIT employs multi-stage reinforcement learning to discover Pareto-optimal reasoning behaviors at each effort, followed by on-policy distillation to fuse these behaviors into a single unified model. Experiments show that ORBIT achieves (1) controllable reasoning behavior over multiple modes, (2) competitive reasoning density within each mode, and (3) integration of these frontier policies into a single unified student model while preserving clear mode separation and high per-mode performance.
Composable Cross-prompt Essay Scoring by Merging Models
May 24, 2025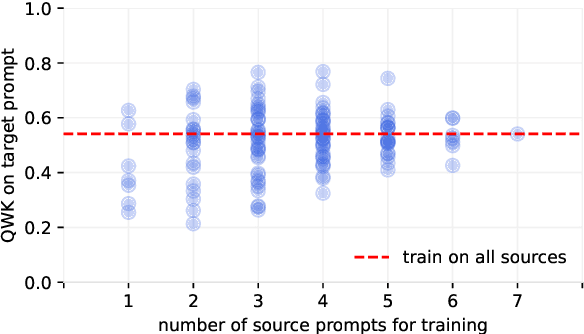

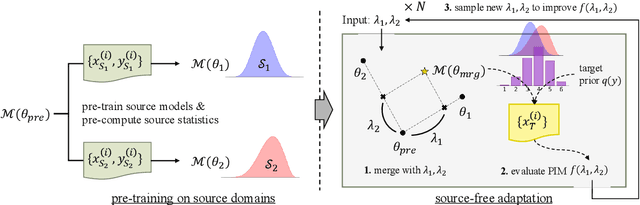
Recent advances in cross-prompt automated essay scoring (AES) typically train models jointly on all source prompts, often requiring additional access to unlabeled target prompt essays simultaneously. However, using all sources is suboptimal in our pilot study, and re-accessing source datasets during adaptation raises privacy concerns. We propose a source-free adaptation approach that selectively merges individually trained source models' parameters instead of datasets. In particular, we simulate joint training through linear combinations of task vectors -- the parameter updates from fine-tuning. To optimize the combination's coefficients, we propose Prior-encoded Information Maximization (PIM), an unsupervised objective which promotes the model's score discriminability regularized by priors pre-computed from the sources. We employ Bayesian optimization as an efficient optimizer of PIM. Experimental results with LLMs on in-dataset and cross-dataset adaptation show that our method (1) consistently outperforms training jointly on all sources, (2) maintains superior robustness compared to other merging methods, (3) excels under severe distribution shifts where recent leading cross-prompt methods struggle, all while retaining computational efficiency.
Dynamic Fisher-weighted Model Merging via Bayesian Optimization
Apr 26, 2025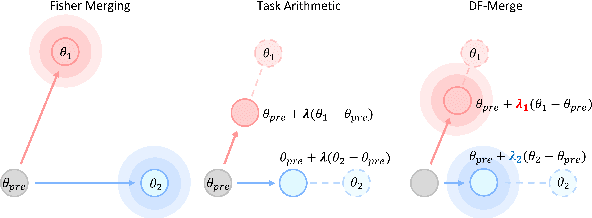



The fine-tuning of pre-trained language models has resulted in the widespread availability of task-specific models. Model merging offers an efficient way to create multi-task models by combining these fine-tuned models at the parameter level, without the need for training data or joint training on multiple datasets. Existing merging approaches typically involve scaling the parameters model-wise or integrating parameter importance parameter-wise. Both approaches exhibit their own weaknesses, leading to a notable performance gap compared to multi-task fine-tuning. In this paper, we unify these seemingly distinct strategies into a more general merging framework, and introduce Dynamic Fisher-weighted Merging (DF-Merge). Specifically, candidate models are associated with a set of coefficients that linearly scale their fine-tuned parameters. Bayesian optimization is applied to dynamically adjust these coefficients, aiming to maximize overall performance on validation sets. Each iteration of this process integrates parameter importance based on the Fisher information conditioned by the coefficients. Experimental results show that DF-Merge outperforms strong baselines across models of different sizes and a variety of tasks. Our analysis shows that the effectiveness of DF-Merge arises from the unified view of merging and that near-optimal performance is achievable in a few iterations, even with minimal validation data.
Rank-Then-Score: Enhancing Large Language Models for Automated Essay Scoring
Apr 08, 2025In recent years, large language models (LLMs) achieve remarkable success across a variety of tasks. However, their potential in the domain of Automated Essay Scoring (AES) remains largely underexplored. Moreover, compared to English data, the methods for Chinese AES is not well developed. In this paper, we propose Rank-Then-Score (RTS), a fine-tuning framework based on large language models to enhance their essay scoring capabilities. Specifically, we fine-tune the ranking model (Ranker) with feature-enriched data, and then feed the output of the ranking model, in the form of a candidate score set, with the essay content into the scoring model (Scorer) to produce the final score. Experimental results on two benchmark datasets, HSK and ASAP, demonstrate that RTS consistently outperforms the direct prompting (Vanilla) method in terms of average QWK across all LLMs and datasets, and achieves the best performance on Chinese essay scoring using the HSK dataset.
A Survey of Uncertainty Estimation in LLMs: Theory Meets Practice
Oct 20, 2024
As large language models (LLMs) continue to evolve, understanding and quantifying the uncertainty in their predictions is critical for enhancing application credibility. However, the existing literature relevant to LLM uncertainty estimation often relies on heuristic approaches, lacking systematic classification of the methods. In this survey, we clarify the definitions of uncertainty and confidence, highlighting their distinctions and implications for model predictions. On this basis, we integrate theoretical perspectives, including Bayesian inference, information theory, and ensemble strategies, to categorize various classes of uncertainty estimation methods derived from heuristic approaches. Additionally, we address challenges that arise when applying these methods to LLMs. We also explore techniques for incorporating uncertainty into diverse applications, including out-of-distribution detection, data annotation, and question clarification. Our review provides insights into uncertainty estimation from both definitional and theoretical angles, contributing to a comprehensive understanding of this critical aspect in LLMs. We aim to inspire the development of more reliable and effective uncertainty estimation approaches for LLMs in real-world scenarios.
FPT: Feature Prompt Tuning for Few-shot Readability Assessment
Apr 10, 2024



Prompt-based methods have achieved promising results in most few-shot text classification tasks. However, for readability assessment tasks, traditional prompt methods lackcrucial linguistic knowledge, which has already been proven to be essential. Moreover, previous studies on utilizing linguistic features have shown non-robust performance in few-shot settings and may even impair model performance.To address these issues, we propose a novel prompt-based tuning framework that incorporates rich linguistic knowledge, called Feature Prompt Tuning (FPT). Specifically, we extract linguistic features from the text and embed them into trainable soft prompts. Further, we devise a new loss function to calibrate the similarity ranking order between categories. Experimental results demonstrate that our proposed method FTP not only exhibits a significant performance improvement over the prior best prompt-based tuning approaches, but also surpasses the previous leading methods that incorporate linguistic features. Also, our proposed model significantly outperforms the large language model gpt-3.5-turbo-16k in most cases. Our proposed method establishes a new architecture for prompt tuning that sheds light on how linguistic features can be easily adapted to linguistic-related tasks.
Prompting Large Language Models for Zero-shot Essay Scoring via Multi-trait Specialization
Apr 07, 2024Advances in automated essay scoring (AES) have traditionally relied on labeled essays, requiring tremendous cost and expertise for their acquisition. Recently, large language models (LLMs) have achieved great success in various tasks, but their potential is less explored in AES. In this paper, we propose Multi Trait Specialization (MTS), a zero-shot prompting framework to elicit essay scoring capabilities in LLMs. Specifically, we leverage ChatGPT to decompose writing proficiency into distinct traits and generate scoring criteria for each trait. Then, an LLM is prompted to extract trait scores from several conversational rounds, each round scoring one of the traits based on the scoring criteria. Finally, we derive the overall score via trait averaging and min-max scaling. Experimental results on two benchmark datasets demonstrate that MTS consistently outperforms straightforward prompting (Vanilla) in average QWK across all LLMs and datasets, with maximum gains of 0.437 on TOEFL11 and 0.355 on ASAP. Additionally, with the help of MTS, the small-sized Llama2-13b-chat substantially outperforms ChatGPT, facilitating an effective deployment in real applications.