 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Reasoning to Generative Recommendation Through the Lens of Cascaded Ranking
Feb 03, 2026Generative Recommendation (GR) has become a promising end-to-end approach with high FLOPS utilization for resource-efficient recommendation. Despite the effectiveness, we show that current GR models suffer from a critical \textbf{bias amplification} issue, where token-level bias escalates as token generation progresses, ultimately limiting the recommendation diversity and hurting the user experience. By comparing against the key factor behind the success of traditional multi-stage pipelines, we reveal two limitations in GR that can amplify the bias: homogeneous reliance on the encoded history, and fixed computational budgets that prevent deeper user preference understanding. To combat the bias amplification issue, it is crucial for GR to 1) incorporate more heterogeneous information, and 2) allocate greater computational resources at each token generation step. To this end, we propose CARE, a simple yet effective cascaded reasoning framework for debiased GR. To incorporate heterogeneous information, we introduce a progressive history encoding mechanism, which progressively incorporates increasingly fine-grained history information as the generation process advances. To allocate more computations, we propose a query-anchored reasoning mechanism, which seeks to perform a deeper understanding of historical information through parallel reasoning steps. We instantiate CARE on three GR backbones. Empirical results on four datasets show the superiority of CARE in recommendation accuracy, diversity, efficiency, and promising scalability. The codes and datasets are available at https://github.com/Linxyhaha/CARE.
Adversarial Reward Auditing for Active Detection and Mitigation of Reward Hacking
Feb 02, 2026Reinforcement Learning from Human Feedback (RLHF) remains vulnerable to reward hacking, where models exploit spurious correlations in learned reward models to achieve high scores while violating human intent. Existing mitigations rely on static defenses that cannot adapt to novel exploitation strategies. We propose Adversarial Reward Auditing (ARA), a framework that reconceptualizes reward hacking as a dynamic, competitive game. ARA operates in two stages: first, a Hacker policy discovers reward model vulnerabilities while an Auditor learns to detect exploitation from latent representations; second, Auditor-Guided RLHF (AG-RLHF) gates reward signals to penalize detected hacking, transforming reward hacking from an unobservable failure into a measurable, controllable signal. Experiments across three hacking scenarios demonstrate that ARA achieves the best alignment-utility tradeoff among all baselines: reducing sycophancy to near-SFT levels while improving helpfulness, decreasing verbosity while achieving the highest ROUGE-L, and suppressing code gaming while improving Pass@1. Beyond single-domain evaluation, we show that reward hacking, detection, and mitigation all generalize across domains -- a Hacker trained on code gaming exhibits increased sycophancy despite no reward for this behavior, and an Auditor trained on one domain effectively suppresses exploitation in others, enabling efficient multi-domain defense with a single model.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Jan 13, 2026Vision-Language-Action models have recently emerged as a powerful paradigm for general-purpose robot learning, enabling agents to map visual observations and natural-language instructions into executable robotic actions. Though popular, they are primarily trained via supervised fine-tuning or training-time reinforcement learning, requiring explicit fine-tuning phases, human interventions, or controlled data collection. Consequently, existing methods remain unsuitable for challenging simulated- or physical-world deployments, where robots must respond autonomously and flexibly to evolving environments. To address this limitation, we introduce a Test-Time Reinforcement Learning for VLAs (TT-VLA), a framework that enables on-the-fly policy adaptation during inference. TT-VLA formulates a dense reward mechanism that leverages step-by-step task-progress signals to refine action policies during test time while preserving the SFT/RL-trained priors, making it an effective supplement to current VLA models. Empirical results show that our approach enhances overall adaptability, stability, and task success in dynamic, previously unseen scenarios under simulated and real-world settings. We believe TT-VLA offers a principled step toward self-improving, deployment-ready VLAs.
How Do Large Language Models Learn Concepts During Continual Pre-Training?
Jan 07, 2026Human beings primarily understand the world through concepts (e.g., dog), abstract mental representations that structure perception, reasoning, and learning. However, how large language models (LLMs) acquire, retain, and forget such concepts during continual pretraining remains poorly understood. In this work, we study how individual concepts are acquired and forgotten, as well as how multiple concepts interact through interference and synergy. We link these behavioral dynamics to LLMs' internal Concept Circuits, computational subgraphs associated with specific concepts, and incorporate Graph Metrics to characterize circuit structure. Our analysis reveals: (1) LLMs concept circuits provide a non-trivial, statistically significant signal of concept learning and forgetting; (2) Concept circuits exhibit a stage-wise temporal pattern during continual pretraining, with an early increase followed by gradual decrease and stabilization; (3) concepts with larger learning gains tend to exhibit greater forgetting under subsequent training; (4) semantically similar concepts induce stronger interference than weakly related ones; (5) conceptual knowledge differs in their transferability, with some significantly facilitating the learning of others. Together, our findings offer a circuit-level view of concept learning dynamics and inform the design of more interpretable and robust concept-aware training strategies for LLMs.
Demystifying Hybrid Thinking: Can LLMs Truly Switch Between Think and No-Think?
Oct 14, 2025



Hybrid thinking enables LLMs to switch between reasoning and direct answering, offering a balance between efficiency and reasoning capability. Yet our experiments reveal that current hybrid thinking LLMs only achieve partial mode separation: reasoning behaviors often leak into the no-think mode. To understand and mitigate this, we analyze the factors influencing controllability and identify four that matter most: (1) larger data scale, (2) using think and no-think answers from different questions rather than the same question, (3) a moderate increase in no-think data number, and (4) a two-phase strategy that first trains reasoning ability and then applies hybrid think training. Building on these findings, we propose a practical recipe that, compared to standard training, can maintain accuracy in both modes while significantly reducing no-think output length (from $1085$ to $585$ on MATH500) and occurrences of reasoning-supportive tokens such as ``\texttt{wait}'' (from $5917$ to $522$ on MATH500). Our findings highlight the limitations of current hybrid thinking and offer directions for strengthening its controllability.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025
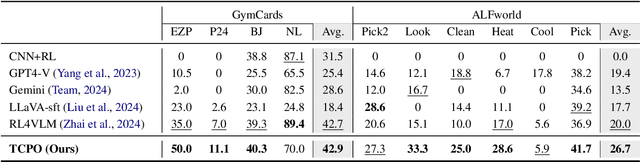
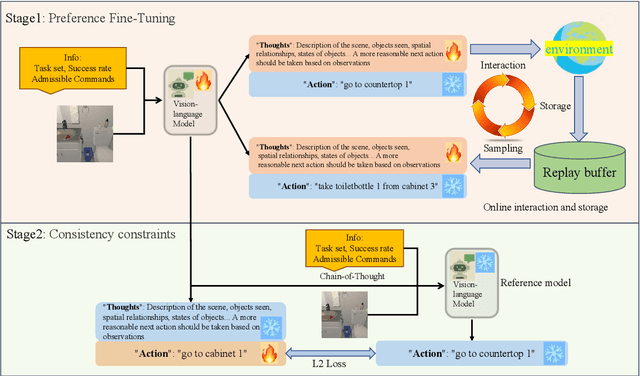

Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
Pisces: An Auto-regressive Foundation Model for Image Understanding and Generation
Jun 12, 2025Recent advances in large language models (LLMs) have enabled multimodal foundation models to tackle both image understanding and generation within a unified framework. Despite these gains, unified models often underperform compared to specialized models in either task. A key challenge in developing unified models lies in the inherent differences between the visual features needed for image understanding versus generation, as well as the distinct training processes required for each modality. In this work, we introduce Pisces, an auto-regressive multimodal foundation model that addresses this challenge through a novel decoupled visual encoding architecture and tailored training techniques optimized for multimodal generation. Combined with meticulous data curation, pretraining, and finetuning, Pisces achieves competitive performance in both image understanding and image generation. We evaluate Pisces on over 20 public benchmarks for image understanding, where it demonstrates strong performance across a wide range of tasks. Additionally, on GenEval, a widely adopted benchmark for image generation, Pisces exhibits robust generative capabilities. Our extensive analysis reveals the synergistic relationship between image understanding and generation, and the benefits of using separate visual encoders, advancing the field of unified multimodal models.
FinHEAR: Human Expertise and Adaptive Risk-Aware Temporal Reasoning for Financial Decision-Making
Jun 10, 2025Financial decision-making presents unique challenges for language models, demanding temporal reasoning, adaptive risk assessment, and responsiveness to dynamic events. While large language models (LLMs) show strong general reasoning capabilities, they often fail to capture behavioral patterns central to human financial decisions-such as expert reliance under information asymmetry, loss-averse sensitivity, and feedback-driven temporal adjustment. We propose FinHEAR, a multi-agent framework for Human Expertise and Adaptive Risk-aware reasoning. FinHEAR orchestrates specialized LLM-based agents to analyze historical trends, interpret current events, and retrieve expert-informed precedents within an event-centric pipeline. Grounded in behavioral economics, it incorporates expert-guided retrieval, confidence-adjusted position sizing, and outcome-based refinement to enhance interpretability and robustness. Empirical results on curated financial datasets show that FinHEAR consistently outperforms strong baselines across trend prediction and trading tasks, achieving higher accuracy and better risk-adjusted returns.
Guideline Forest: Experience-Induced Multi-Guideline Reasoning with Stepwise Aggregation
Jun 09, 2025



Human reasoning is flexible, adaptive, and grounded in prior experience-qualities that large language models (LLMs) still struggle to emulate. Existing methods either explore diverse reasoning paths at inference time or search for optimal workflows through expensive operations, but both fall short in leveraging multiple reusable strategies in a structured, efficient manner. We propose Guideline Forest, a framework that enhances LLMs reasoning by inducing structured reasoning strategies-called guidelines-from verified examples and executing them via step-wise aggregation. Unlike test-time search or single-path distillation, our method draws on verified reasoning experiences by inducing reusable guidelines and expanding each into diverse variants. Much like human reasoning, these variants reflect alternative thought patterns, are executed in parallel, refined via self-correction, and aggregated step by step-enabling the model to adaptively resolve uncertainty and synthesize robust solutions.We evaluate Guideline Forest on four benchmarks-GSM8K, MATH-500, MBPP, and HumanEval-spanning mathematical and programmatic reasoning. Guideline Forest consistently outperforms strong baselines, including CoT, ReAct, ToT, FoT, and AFlow. Ablation studies further highlight the effectiveness of multi-path reasoning and stepwise aggregation, underscoring the Guideline Forest's adaptability and generalization potential.