 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
Don't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
Nov 16, 2025Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Oct 02, 2025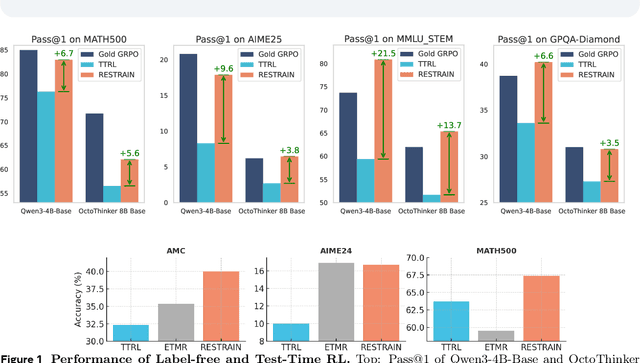
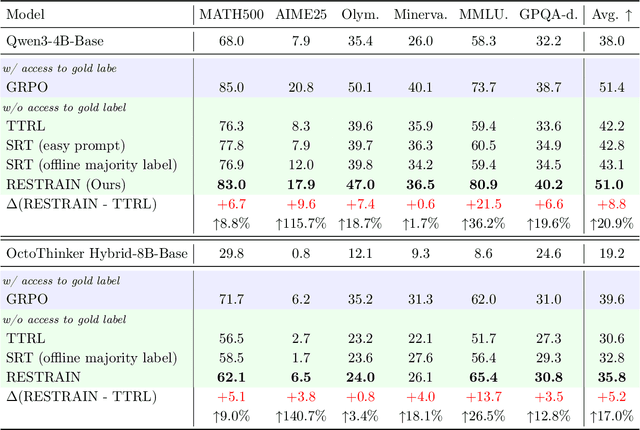
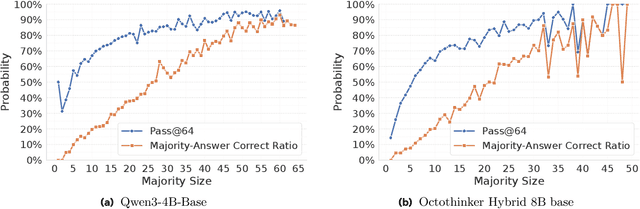
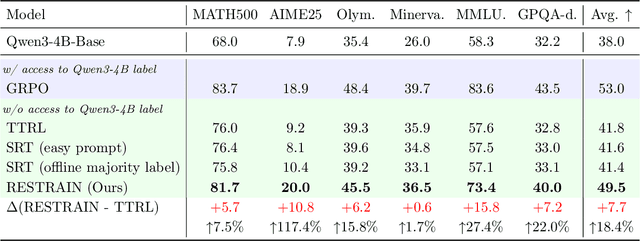
Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
Optimizing Recall or Relevance? A Multi-Task Multi-Head Approach for Item-to-Item Retrieval in Recommendation
Jun 06, 2025The task of item-to-item (I2I) retrieval is to identify a set of relevant and highly engaging items based on a given trigger item. It is a crucial component in modern recommendation systems, where users' previously engaged items serve as trigger items to retrieve relevant content for future engagement. However, existing I2I retrieval models in industry are primarily built on co-engagement data and optimized using the recall measure, which overly emphasizes co-engagement patterns while failing to capture semantic relevance. This often leads to overfitting short-term co-engagement trends at the expense of long-term benefits such as discovering novel interests and promoting content diversity. To address this challenge, we propose MTMH, a Multi-Task and Multi-Head I2I retrieval model that achieves both high recall and semantic relevance. Our model consists of two key components: 1) a multi-task learning loss for formally optimizing the trade-off between recall and semantic relevance, and 2) a multi-head I2I retrieval architecture for retrieving both highly co-engaged and semantically relevant items. We evaluate MTMH using proprietary data from a commercial platform serving billions of users and demonstrate that it can improve recall by up to 14.4% and semantic relevance by up to 56.6% compared with prior state-of-the-art models. We also conduct live experiments to verify that MTMH can enhance both short-term consumption metrics and long-term user-experience-related metrics. Our work provides a principled approach for jointly optimizing I2I recall and semantic relevance, which has significant implications for improving the overall performance of recommendation systems.
VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
May 25, 2025Reinforcement Learning Finetuning (RFT) has significantly advanced the reasoning capabilities of large language models (LLMs) by enabling long chains of thought, self-correction, and effective tool use. While recent works attempt to extend RFT to vision-language models (VLMs), these efforts largely produce text-only reasoning conditioned on static image inputs, falling short of true multimodal reasoning in the response. In contrast, test-time methods like Visual Sketchpad incorporate visual steps but lack training mechanisms. We introduce VTool-R1, the first framework that trains VLMs to generate multimodal chains of thought by interleaving text and intermediate visual reasoning steps. VTool-R1 integrates Python-based visual editing tools into the RFT process, enabling VLMs to learn when and how to generate visual reasoning steps that benefit final reasoning. Trained with outcome-based rewards tied to task accuracy, our approach elicits strategic visual tool use for reasoning without relying on process-based supervision. Experiments on structured visual question answering over charts and tables show that VTool-R1 enhances reasoning performance by teaching VLMs to "think with images" and generate multimodal chain of thoughts with tools.
Inference Compute-Optimal Video Vision Language Models
May 24, 2025This work investigates the optimal allocation of inference compute across three key scaling factors in video vision language models: language model size, frame count, and the number of visual tokens per frame. While prior works typically focuses on optimizing model efficiency or improving performance without considering resource constraints, we instead identify optimal model configuration under fixed inference compute budgets. We conduct large-scale training sweeps and careful parametric modeling of task performance to identify the inference compute-optimal frontier. Our experiments reveal how task performance depends on scaling factors and finetuning data size, as well as how changes in data size shift the compute-optimal frontier. These findings translate to practical tips for selecting these scaling factors.
Learning Critically: Selective Self Distillation in Federated Learning on Non-IID Data
Apr 20, 2025Federated learning (FL) enables multiple clients to collaboratively train a global model while keeping local data decentralized. Data heterogeneity (non-IID) across clients has imposed significant challenges to FL, which makes local models re-optimize towards their own local optima and forget the global knowledge, resulting in performance degradation and convergence slowdown. Many existing works have attempted to address the non-IID issue by adding an extra global-model-based regularizing item to the local training but without an adaption scheme, which is not efficient enough to achieve high performance with deep learning models. In this paper, we propose a Selective Self-Distillation method for Federated learning (FedSSD), which imposes adaptive constraints on the local updates by self-distilling the global model's knowledge and selectively weighting it by evaluating the credibility at both the class and sample level. The convergence guarantee of FedSSD is theoretically analyzed and extensive experiments are conducted on three public benchmark datasets, which demonstrates that FedSSD achieves better generalization and robustness in fewer communication rounds, compared with other state-of-the-art FL methods.
CAFe: Unifying Representation and Generation with Contrastive-Autoregressive Finetuning
Mar 25, 2025The rapid advancement of large vision-language models (LVLMs) has driven significant progress in multimodal tasks, enabling models to interpret, reason, and generate outputs across both visual and textual domains. While excelling in generative tasks, existing LVLMs often face limitations in tasks requiring high-fidelity representation learning, such as generating image or text embeddings for retrieval. Recent work has proposed finetuning LVLMs for representational learning, but the fine-tuned model often loses its generative capabilities due to the representational learning training paradigm. To address this trade-off, we introduce CAFe, a contrastive-autoregressive fine-tuning framework that enhances LVLMs for both representation and generative tasks. By integrating a contrastive objective with autoregressive language modeling, our approach unifies these traditionally separate tasks, achieving state-of-the-art results in both multimodal retrieval and multimodal generative benchmarks, including object hallucination (OH) mitigation. CAFe establishes a novel framework that synergizes embedding and generative functionalities in a single model, setting a foundation for future multimodal models that excel in both retrieval precision and coherent output generation.
Towards An Efficient LLM Training Paradigm for CTR Prediction
Mar 02, 2025Large Language Models (LLMs) have demonstrated tremendous potential as the next-generation ranking-based recommendation system. Many recent works have shown that LLMs can significantly outperform conventional click-through-rate (CTR) prediction approaches. Despite such promising results, the computational inefficiency inherent in the current training paradigm makes it particularly challenging to train LLMs for ranking-based recommendation tasks on large datasets. To train LLMs for CTR prediction, most existing studies adopt the prevalent ''sliding-window'' paradigm. Given a sequence of $m$ user interactions, a unique training prompt is constructed for each interaction by designating it as the prediction target along with its preceding $n$ interactions serving as context. In turn, the sliding-window paradigm results in an overall complexity of $O(mn^2)$ that scales linearly with the length of user interactions. Consequently, a direct adoption to train LLMs with such strategy can result in prohibitively high training costs as the length of interactions grows. To alleviate the computational inefficiency, we propose a novel training paradigm, namely Dynamic Target Isolation (DTI), that structurally parallelizes the training of $k$ (where $k >> 1$) target interactions. Furthermore, we identify two major bottlenecks - hidden-state leakage and positional bias overfitting - that limit DTI to only scale up to a small value of $k$ (e.g., 5) then propose a computationally light solution to effectively tackle each. Through extensive experiments on three widely adopted public CTR datasets, we empirically show that DTI reduces training time by an average of $\textbf{92%}$ (e.g., from $70.5$ hrs to $5.31$ hrs), without compromising CTR prediction performance.
BRIDLE: Generalized Self-supervised Learning with Quantization
Feb 04, 2025



Self-supervised learning has been a powerful approach for learning meaningful representations from unlabeled data across various domains, reducing the reliance on large labeled datasets. Inspired by BERT's success in capturing deep bidirectional contexts in natural language processing, similar frameworks have been adapted to other modalities such as audio, with models like BEATs extending the bidirectional training paradigm to audio signals using vector quantization (VQ). However, these frameworks face challenges, notably their dependence on a single codebook for quantization, which may not capture the complex, multifaceted nature of signals. In addition, inefficiencies in codebook utilization lead to underutilized code vectors. To address these limitations, we introduce BRIDLE (Bidirectional Residual Quantization Interleaved Discrete Learning Encoder), a self-supervised encoder pretraining framework that incorporates residual quantization (RQ) into the bidirectional training process, and is generalized for pretraining with audio, image, and video. Using multiple hierarchical codebooks, RQ enables fine-grained discretization in the latent space, enhancing representation quality. BRIDLE involves an interleaved training procedure between the encoder and tokenizer. We evaluate BRIDLE on audio understanding tasks using classification benchmarks, achieving state-of-the-art results, and demonstrate competitive performance on image classification and video classification tasks, showing consistent improvements over traditional VQ methods in downstream performance.