 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling non-log-concave densities via Hessian-free high-resolution dynamics
Jan 06, 2026We study the problem of sampling from a target distribution $π(q)\propto e^{-U(q)}$ on $\mathbb{R}^d$, where $U$ can be non-convex, via the Hessian-free high-resolution (HFHR) dynamics, which is a second-order Langevin-type process that has $e^{-U(q)-\frac12|p|^2}$ as its unique invariant distribution, and it reduces to kinetic Langevin dynamics (KLD) as the resolution parameter $α\to0$. The existing theory for HFHR dynamics in the literature is restricted to strongly-convex $U$, although numerical experiments are promising for non-convex settings as well. We focus on studying the convergence of HFHR dynamics when $U$ can be non-convex, which bridges a gap between theory and practice. Under a standard assumption of dissipativity and smoothness on $U$, we adopt the reflection/synchronous coupling method. This yields a Lyapunov-weighted Wasserstein distance in which the HFHR semigroup is exponentially contractive for all sufficiently small $α>0$ whenever KLD is. We further show that, under an additional assumption that asymptotically $\nabla U$ has linear growth at infinity, the contraction rate for HFHR dynamics is strictly better than that of KLD, with an explicit gain. As a case study, we verify the assumptions and the resulting acceleration for three examples: a multi-well potential, Bayesian linear regression with $L^p$ regularizer and Bayesian binary classification. We conduct numerical experiments based on these examples, as well as an additional example of Bayesian logistic regression with real data processed by the neural networks, which illustrates the efficiency of the algorithms based on HFHR dynamics and verifies the acceleration and superior performance compared to KLD.
Rényi Differential Privacy for Heavy-Tailed SDEs via Fractional Poincaré Inequalities
Nov 19, 2025Characterizing the differential privacy (DP) of learning algorithms has become a major challenge in recent years. In parallel, many studies suggested investigating the behavior of stochastic gradient descent (SGD) with heavy-tailed noise, both as a model for modern deep learning models and to improve their performance. However, most DP bounds focus on light-tailed noise, where satisfactory guarantees have been obtained but the proposed techniques do not directly extend to the heavy-tailed setting. Recently, the first DP guarantees for heavy-tailed SGD were obtained. These results provide $(0,δ)$-DP guarantees without requiring gradient clipping. Despite casting new light on the link between DP and heavy-tailed algorithms, these results have a strong dependence on the number of parameters and cannot be extended to other DP notions like the well-established Rényi differential privacy (RDP). In this work, we propose to address these limitations by deriving the first RDP guarantees for heavy-tailed SDEs, as well as their discretized counterparts. Our framework is based on new Rényi flow computations and the use of well-established fractional Poincaré inequalities. Under the assumption that such inequalities are satisfied, we obtain DP guarantees that have a much weaker dependence on the dimension compared to prior art.
DIGing--SGLD: Decentralized and Scalable Langevin Sampling over Time--Varying Networks
Nov 16, 2025Sampling from a target distribution induced by training data is central to Bayesian learning, with Stochastic Gradient Langevin Dynamics (SGLD) serving as a key tool for scalable posterior sampling and decentralized variants enabling learning when data are distributed across a network of agents. This paper introduces DIGing-SGLD, a decentralized SGLD algorithm designed for scalable Bayesian learning in multi-agent systems operating over time-varying networks. Existing decentralized SGLD methods are restricted to static network topologies, and many exhibit steady-state sampling bias caused by network effects, even when full batches are used. DIGing-SGLD overcomes these limitations by integrating Langevin-based sampling with the gradient-tracking mechanism of the DIGing algorithm, originally developed for decentralized optimization over time-varying networks, thereby enabling efficient and bias-free sampling without a central coordinator. To our knowledge, we provide the first finite-time non-asymptotic Wasserstein convergence guarantees for decentralized SGLD-based sampling over time-varying networks, with explicit constants. Under standard strong convexity and smoothness assumptions, DIGing-SGLD achieves geometric convergence to an $O(\sqrtη)$ neighborhood of the target distribution, where $η$ is the stepsize, with dependence on the target accuracy matching the best-known rates for centralized and static-network SGLD algorithms using constant stepsize. Numerical experiments on Bayesian linear and logistic regression validate the theoretical results and demonstrate the strong empirical performance of DIGing-SGLD under dynamically evolving network conditions.
High-Order Langevin Monte Carlo Algorithms
Aug 24, 2025Langevin algorithms are popular Markov chain Monte Carlo (MCMC) methods for large-scale sampling problems that often arise in data science. We propose Monte Carlo algorithms based on the discretizations of $P$-th order Langevin dynamics for any $P\geq 3$. Our design of $P$-th order Langevin Monte Carlo (LMC) algorithms is by combining splitting and accurate integration methods. We obtain Wasserstein convergence guarantees for sampling from distributions with log-concave and smooth densities. Specifically, the mixing time of the $P$-th order LMC algorithm scales as $O\left(d^{\frac{1}{R}}/\epsilon^{\frac{1}{2R}}\right)$ for $R=4\cdot 1_{\{ P=3\}}+ (2P-1)\cdot 1_{\{ P\geq 4\}}$, which has a better dependence on the dimension $d$ and the accuracy level $\epsilon$ as $P$ grows. Numerical experiments illustrate the efficiency of our proposed algorithms.
Accelerating Constrained Sampling: A Large Deviations Approach
Jun 09, 2025The problem of sampling a target probability distribution on a constrained domain arises in many applications including machine learning. For constrained sampling, various Langevin algorithms such as projected Langevin Monte Carlo (PLMC) based on the discretization of reflected Langevin dynamics (RLD) and more generally skew-reflected non-reversible Langevin Monte Carlo (SRNLMC) based on the discretization of skew-reflected non-reversible Langevin dynamics (SRNLD) have been proposed and studied in the literature. This work focuses on the long-time behavior of SRNLD, where a skew-symmetric matrix is added to RLD. Although the non-asymptotic convergence analysis for SRNLD (and SRNLMC) and the acceleration compared to RLD (and PMLC) have been studied in the literature, it is not clear how one should design the skew-symmetric matrix in the dynamics to achieve good performance in practice. We establish a large deviation principle (LDP) for the empirical measure of SRNLD when the skew-symmetric matrix is chosen such that its product with the inward unit normal vector field on the boundary is zero. By explicitly characterizing the rate functions, we show that SRNLD can accelerate the convergence to the target distribution compared to RLD with this choice of the skew-symmetric matrix. Numerical experiments for SRNLMC based on the proposed skew-symmetric matrix show superior performance which validate the theoretical findings from the large deviations theory.
Accelerating Langevin Monte Carlo Sampling: A Large Deviations Analysis
Mar 24, 2025



Langevin algorithms are popular Markov chain Monte Carlo methods that are often used to solve high-dimensional large-scale sampling problems in machine learning. The most classical Langevin Monte Carlo algorithm is based on the overdamped Langevin dynamics. There are many variants of Langevin dynamics that often show superior performance in practice. In this paper, we provide a unified approach to study the acceleration of the variants of the overdamped Langevin dynamics through the lens of large deviations theory. Numerical experiments using both synthetic and real data are provided to illustrate the efficiency of these variants.
BRIDLE: Generalized Self-supervised Learning with Quantization
Feb 04, 2025



Self-supervised learning has been a powerful approach for learning meaningful representations from unlabeled data across various domains, reducing the reliance on large labeled datasets. Inspired by BERT's success in capturing deep bidirectional contexts in natural language processing, similar frameworks have been adapted to other modalities such as audio, with models like BEATs extending the bidirectional training paradigm to audio signals using vector quantization (VQ). However, these frameworks face challenges, notably their dependence on a single codebook for quantization, which may not capture the complex, multifaceted nature of signals. In addition, inefficiencies in codebook utilization lead to underutilized code vectors. To address these limitations, we introduce BRIDLE (Bidirectional Residual Quantization Interleaved Discrete Learning Encoder), a self-supervised encoder pretraining framework that incorporates residual quantization (RQ) into the bidirectional training process, and is generalized for pretraining with audio, image, and video. Using multiple hierarchical codebooks, RQ enables fine-grained discretization in the latent space, enhancing representation quality. BRIDLE involves an interleaved training procedure between the encoder and tokenizer. We evaluate BRIDLE on audio understanding tasks using classification benchmarks, achieving state-of-the-art results, and demonstrate competitive performance on image classification and video classification tasks, showing consistent improvements over traditional VQ methods in downstream performance.
Algorithmic Stability of Stochastic Gradient Descent with Momentum under Heavy-Tailed Noise
Feb 02, 2025Understanding the generalization properties of optimization algorithms under heavy-tailed noise has gained growing attention. However, the existing theoretical results mainly focus on stochastic gradient descent (SGD) and the analysis of heavy-tailed optimizers beyond SGD is still missing. In this work, we establish generalization bounds for SGD with momentum (SGDm) under heavy-tailed gradient noise. We first consider the continuous-time limit of SGDm, i.e., a Levy-driven stochastic differential equation (SDE), and establish quantitative Wasserstein algorithmic stability bounds for a class of potentially non-convex loss functions. Our bounds reveal a remarkable observation: For quadratic loss functions, we show that SGDm admits a worse generalization bound in the presence of heavy-tailed noise, indicating that the interaction of momentum and heavy tails can be harmful for generalization. We then extend our analysis to discrete-time and develop a uniform-in-time discretization error bound, which, to our knowledge, is the first result of its kind for SDEs with degenerate noise. This result shows that, with appropriately chosen step-sizes, the discrete dynamics retain the generalization properties of the limiting SDE. We illustrate our theory on both synthetic quadratic problems and neural networks.
Non-Reversible Langevin Algorithms for Constrained Sampling
Jan 20, 2025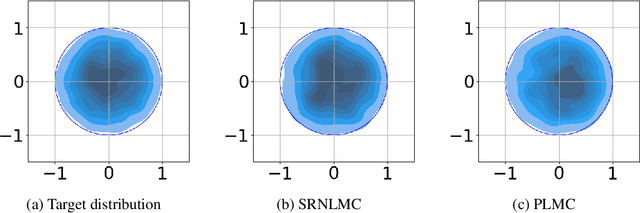
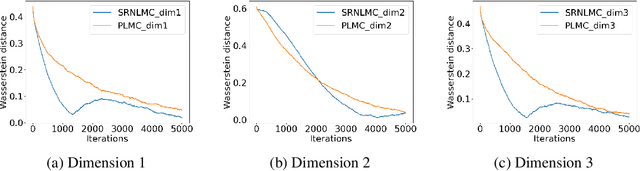
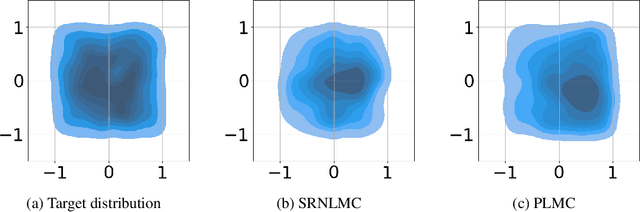
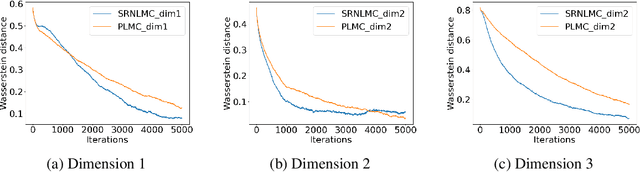
We consider the constrained sampling problem where the goal is to sample from a target distribution on a constrained domain. We propose skew-reflected non-reversible Langevin dynamics (SRNLD), a continuous-time stochastic differential equation with skew-reflected boundary. We obtain non-asymptotic convergence rate of SRNLD to the target distribution in both total variation and 1-Wasserstein distances. By breaking reversibility, we show that the convergence is faster than the special case of the reversible dynamics. Based on the discretization of SRNLD, we propose skew-reflected non-reversible Langevin Monte Carlo (SRNLMC), and obtain non-asymptotic discretization error from SRNLD, and convergence guarantees to the target distribution in 1-Wasserstein distance. We show better performance guarantees than the projected Langevin Monte Carlo in the literature that is based on the reversible dynamics. Numerical experiments are provided for both synthetic and real datasets to show efficiency of the proposed algorithms.
Generalized EXTRA stochastic gradient Langevin dynamics
Dec 02, 2024



Langevin algorithms are popular Markov Chain Monte Carlo methods for Bayesian learning, particularly when the aim is to sample from the posterior distribution of a parametric model, given the input data and the prior distribution over the model parameters. Their stochastic versions such as stochastic gradient Langevin dynamics (SGLD) allow iterative learning based on randomly sampled mini-batches of large datasets and are scalable to large datasets. However, when data is decentralized across a network of agents subject to communication and privacy constraints, standard SGLD algorithms cannot be applied. Instead, we employ decentralized SGLD (DE-SGLD) algorithms, where Bayesian learning is performed collaboratively by a network of agents without sharing individual data. Nonetheless, existing DE-SGLD algorithms induce a bias at every agent that can negatively impact performance; this bias persists even when using full batches and is attributable to network effects. Motivated by the EXTRA algorithm and its generalizations for decentralized optimization, we propose the generalized EXTRA stochastic gradient Langevin dynamics, which eliminates this bias in the full-batch setting. Moreover, we show that, in the mini-batch setting, our algorithm provides performance bounds that significantly improve upon those of standard DE-SGLD algorithms in the literature. Our numerical results also demonstrate the efficiency of the proposed approach.