 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining A Foundation Model to Represent Graphs as Vectors
Feb 04, 2026This paper aims to train a graph foundation model that is able to represent any graph as a vector preserving structural and semantic information useful for downstream graph-level tasks such as graph classification and graph clustering. To learn the features of graphs from diverse domains while maintaining strong generalization ability to new domains, we propose a multi-graph-based feature alignment method, which constructs weighted graphs using the attributes of all nodes in each dataset and then generates consistent node embeddings. To enhance the consistency of the features from different datasets, we propose a density maximization mean alignment algorithm with guaranteed convergence. The original graphs and generated node embeddings are fed into a graph neural network to achieve discriminative graph representations in contrastive learning. More importantly, to enhance the information preservation from node-level representations to the graph-level representation, we construct a multi-layer reference distribution module without using any pooling operation. We also provide a theoretical generalization bound to support the effectiveness of the proposed model. The experimental results of few-shot graph classification and graph clustering show that our model outperforms strong baselines.
Deep Neural Operator Learning for Probabilistic Models
Nov 10, 2025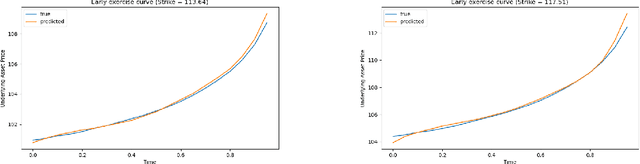
We propose a deep neural-operator framework for a general class of probability models. Under global Lipschitz conditions on the operator over the entire Euclidean space-and for a broad class of probabilistic models-we establish a universal approximation theorem with explicit network-size bounds for the proposed architecture. The underlying stochastic processes are required only to satisfy integrability and general tail-probability conditions. We verify these assumptions for both European and American option-pricing problems within the forward-backward SDE (FBSDE) framework, which in turn covers a broad class of operators arising from parabolic PDEs, with or without free boundaries. Finally, we present a numerical example for a basket of American options, demonstrating that the learned model produces optimal stopping boundaries for new strike prices without retraining.
GraphProp: Training the Graph Foundation Models using Graph Properties
Aug 06, 2025



This work focuses on training graph foundation models (GFMs) that have strong generalization ability in graph-level tasks such as graph classification. Effective GFM training requires capturing information consistent across different domains. We discover that graph structures provide more consistent cross-domain information compared to node features and graph labels. However, traditional GFMs primarily focus on transferring node features from various domains into a unified representation space but often lack structural cross-domain generalization. To address this, we introduce GraphProp, which emphasizes structural generalization. The training process of GraphProp consists of two main phases. First, we train a structural GFM by predicting graph invariants. Since graph invariants are properties of graphs that depend only on the abstract structure, not on particular labellings or drawings of the graph, this structural GFM has a strong ability to capture the abstract structural information and provide discriminative graph representations comparable across diverse domains. In the second phase, we use the representations given by the structural GFM as positional encodings to train a comprehensive GFM. This phase utilizes domain-specific node attributes and graph labels to further improve cross-domain node feature generalization. Our experiments demonstrate that GraphProp significantly outperforms the competitors in supervised learning and few-shot learning, especially in handling graphs without node attributes.
Continuous Policy and Value Iteration for Stochastic Control Problems and Its Convergence
Jun 09, 2025We introduce a continuous policy-value iteration algorithm where the approximations of the value function of a stochastic control problem and the optimal control are simultaneously updated through Langevin-type dynamics. This framework applies to both the entropy-regularized relaxed control problems and the classical control problems, with infinite horizon. We establish policy improvement and demonstrate convergence to the optimal control under the monotonicity condition of the Hamiltonian. By utilizing Langevin-type stochastic differential equations for continuous updates along the policy iteration direction, our approach enables the use of distribution sampling and non-convex learning techniques in machine learning to optimize the value function and identify the optimal control simultaneously.
Visuospatial Cognitive Assistant
May 18, 2025Video-based spatial cognition is vital for robotics and embodied AI but challenges current Vision-Language Models (VLMs). This paper makes two key contributions. First, we introduce ViCA (Visuospatial Cognitive Assistant)-322K, a diverse dataset of 322,003 QA pairs from real-world indoor videos (ARKitScenes, ScanNet, ScanNet++), offering supervision for 3D metadata-grounded queries and video-based complex reasoning. Second, we develop ViCA-7B, fine-tuned on ViCA-322K, which achieves new state-of-the-art on all eight VSI-Bench tasks, outperforming existing models, including larger ones (e.g., +26.1 on Absolute Distance). For interpretability, we present ViCA-Thinking-2.68K, a dataset with explicit reasoning chains, and fine-tune ViCA-7B to create ViCA-7B-Thinking, a model that articulates its spatial reasoning. Our work highlights the importance of targeted data and suggests paths for improved temporal-spatial modeling. We release all resources to foster research in robust visuospatial intelligence.
Towards Visuospatial Cognition via Hierarchical Fusion of Visual Experts
May 18, 2025While Multimodal Large Language Models (MLLMs) excel at general vision-language tasks, visuospatial cognition - reasoning about spatial layouts, relations, and dynamics - remains a significant challenge. Existing models often lack the necessary architectural components and specialized training data for fine-grained spatial understanding. We introduce ViCA2 (Visuospatial Cognitive Assistant 2), a novel MLLM designed to enhance spatial reasoning. ViCA2 features a dual vision encoder architecture integrating SigLIP for semantics and Hiera for spatial structure, coupled with a token ratio control mechanism for efficiency. We also developed ViCA-322K, a new large-scale dataset with over 322,000 spatially grounded question-answer pairs for targeted instruction tuning. On the challenging VSI-Bench benchmark, our ViCA2-7B model achieves a state-of-the-art average score of 56.8, significantly surpassing larger open-source models (e.g., LLaVA-NeXT-Video-72B, 40.9) and leading proprietary models (Gemini-1.5 Pro, 45.4). This demonstrates the effectiveness of our approach in achieving strong visuospatial intelligence with a compact model. We release ViCA2, its codebase, and the ViCA-322K dataset to facilitate further research.
Non-Reversible Langevin Algorithms for Constrained Sampling
Jan 20, 2025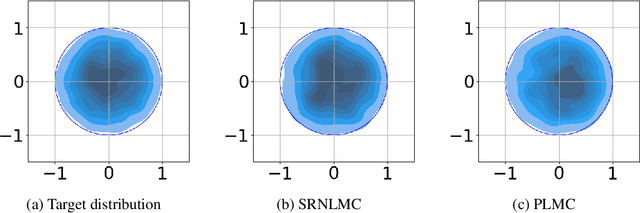
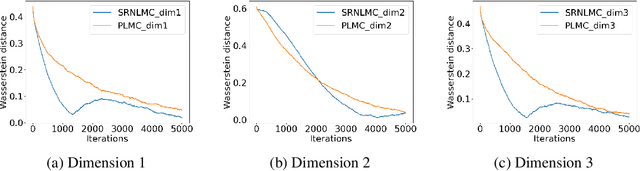
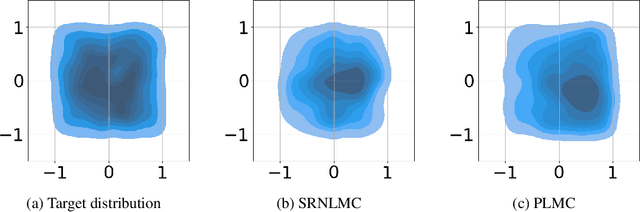
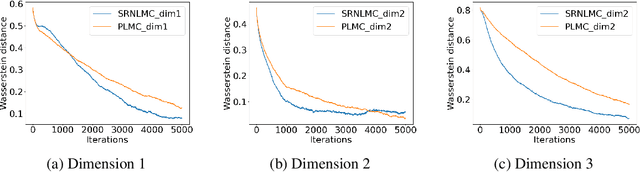
We consider the constrained sampling problem where the goal is to sample from a target distribution on a constrained domain. We propose skew-reflected non-reversible Langevin dynamics (SRNLD), a continuous-time stochastic differential equation with skew-reflected boundary. We obtain non-asymptotic convergence rate of SRNLD to the target distribution in both total variation and 1-Wasserstein distances. By breaking reversibility, we show that the convergence is faster than the special case of the reversible dynamics. Based on the discretization of SRNLD, we propose skew-reflected non-reversible Langevin Monte Carlo (SRNLMC), and obtain non-asymptotic discretization error from SRNLD, and convergence guarantees to the target distribution in 1-Wasserstein distance. We show better performance guarantees than the projected Langevin Monte Carlo in the literature that is based on the reversible dynamics. Numerical experiments are provided for both synthetic and real datasets to show efficiency of the proposed algorithms.
SyncViolinist: Music-Oriented Violin Motion Generation Based on Bowing and Fingering
Dec 11, 2024



Automatically generating realistic musical performance motion can greatly enhance digital media production, often involving collaboration between professionals and musicians. However, capturing the intricate body, hand, and finger movements required for accurate musical performances is challenging. Existing methods often fall short due to the complex mapping between audio and motion, typically requiring additional inputs like scores or MIDI data. In this work, we present SyncViolinist, a multi-stage end-to-end framework that generates synchronized violin performance motion solely from audio input. Our method overcomes the challenge of capturing both global and fine-grained performance features through two key modules: a bowing/fingering module and a motion generation module. The bowing/fingering module extracts detailed playing information from the audio, which the motion generation module uses to create precise, coordinated body motions reflecting the temporal granularity and nature of the violin performance. We demonstrate the effectiveness of SyncViolinist with significantly improved qualitative and quantitative results from unseen violin performance audio, outperforming state-of-the-art methods. Extensive subjective evaluations involving professional violinists further validate our approach. The code and dataset are available at https://github.com/Kakanat/SyncViolinist.
Constrained Exploration via Reflected Replica Exchange Stochastic Gradient Langevin Dynamics
May 13, 2024



Replica exchange stochastic gradient Langevin dynamics (reSGLD) is an effective sampler for non-convex learning in large-scale datasets. However, the simulation may encounter stagnation issues when the high-temperature chain delves too deeply into the distribution tails. To tackle this issue, we propose reflected reSGLD (r2SGLD): an algorithm tailored for constrained non-convex exploration by utilizing reflection steps within a bounded domain. Theoretically, we observe that reducing the diameter of the domain enhances mixing rates, exhibiting a \emph{quadratic} behavior. Empirically, we test its performance through extensive experiments, including identifying dynamical systems with physical constraints, simulations of constrained multi-modal distributions, and image classification tasks. The theoretical and empirical findings highlight the crucial role of constrained exploration in improving the simulation efficiency.
Fisher information dissipation for time inhomogeneous stochastic differential equations
Feb 01, 2024



We provide a Lyapunov convergence analysis for time-inhomogeneous variable coefficient stochastic differential equations (SDEs). Three typical examples include overdamped, irreversible drift, and underdamped Langevin dynamics. We first formula the probability transition equation of Langevin dynamics as a modified gradient flow of the Kullback-Leibler divergence in the probability space with respect to time-dependent optimal transport metrics. This formulation contains both gradient and non-gradient directions depending on a class of time-dependent target distribution. We then select a time-dependent relative Fisher information functional as a Lyapunov functional. We develop a time-dependent Hessian matrix condition, which guarantees the convergence of the probability density function of the SDE. We verify the proposed conditions for several time-inhomogeneous Langevin dynamics. For the overdamped Langevin dynamics, we prove the $O(t^{-1/2})$ convergence in $L^1$ distance for the simulated annealing dynamics with a strongly convex potential function. For the irreversible drift Langevin dynamics, we prove an improved convergence towards the target distribution in an asymptotic regime. We also verify the convergence condition for the underdamped Langevin dynamics. Numerical examples demonstrate the convergence results for the time-dependent Langevin dynamics.