 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Spectral Chromatic Coding of Interference Signatures in SAR Imagery: Signal Modeling and Physical-Visual Interpretation
Sep 10, 2025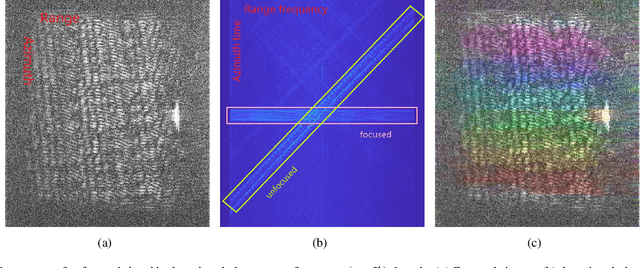
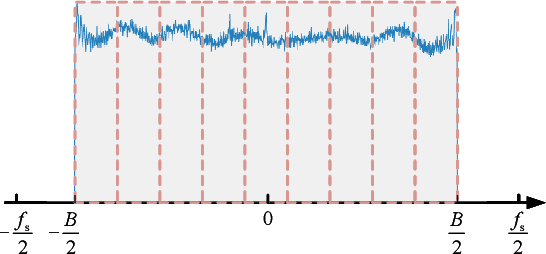
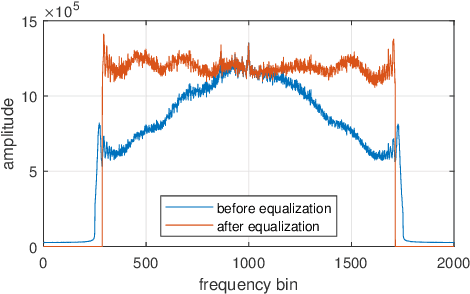
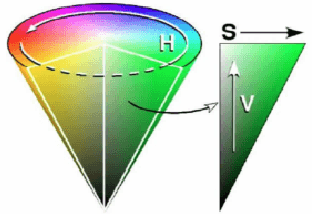
Synthetic Aperture Radar (SAR) images are conventionally visualized as grayscale amplitude representations, which often fail to explicitly reveal interference characteristics caused by external radio emitters and unfocused signals. This paper proposes a novel spatial-spectral chromatic coding method for visual analysis of interference patterns in single-look complex (SLC) SAR imagery. The method first generates a series of spatial-spectral images via spectral subband decomposition that preserve both spatial structures and spectral signatures. These images are subsequently chromatically coded into a color representation using RGB/HSV dual-space coding, using a set of specifically designed color palette. This method intrinsically encodes the spatial-spectral properties of interference into visually discernible patterns, enabling rapid visual interpretation without additional processing. To facilitate physical interpretation, mathematical models are established to theoretically analyze the physical mechanisms of responses to various interference types. Experiments using real datasets demonstrate that the method effectively highlights interference regions and unfocused echo or signal responses (e.g., blurring, ambiguities, and moving target effects), providing analysts with a practical tool for visual interpretation, quality assessment, and data diagnosis in SAR imagery.
E-BayesSAM: Efficient Bayesian Adaptation of SAM with Self-Optimizing KAN-Based Interpretation for Uncertainty-Aware Ultrasonic Segmentation
Aug 24, 2025Although the Segment Anything Model (SAM) has advanced medical image segmentation, its Bayesian adaptation for uncertainty-aware segmentation remains hindered by three key issues: (1) instability in Bayesian fine-tuning of large pre-trained SAMs; (2) high computation cost due to SAM's massive parameters; (3) SAM's black-box design limits interpretability. To overcome these, we propose E-BayesSAM, an efficient framework combining Token-wise Variational Bayesian Inference (T-VBI) for efficienty Bayesian adaptation and Self-Optimizing Kolmogorov-Arnold Network (SO-KAN) for improving interpretability. T-VBI innovatively reinterprets SAM's output tokens as dynamic probabilistic weights and reparameterizes them as latent variables without auxiliary training, enabling training-free VBI for uncertainty estimation. SO-KAN improves token prediction with learnable spline activations via self-supervised learning, providing insight to prune redundant tokens to boost efficiency and accuracy. Experiments on five ultrasound datasets demonstrated that E-BayesSAM achieves: (i) real-time inference (0.03s/image), (ii) superior segmentation accuracy (average DSC: Pruned E-BayesSAM's 89.0\% vs. E-BayesSAM's 88.0% vs. MedSAM's 88.3%), and (iii) identification of four critical tokens governing SAM's decisions. By unifying efficiency, reliability, and interpretability, E-BayesSAM bridges SAM's versatility with clinical needs, advancing deployment in safety-critical medical applications. The source code is available at https://github.com/mp31192/E-BayesSAM.
A Comprehensive Survey on Underwater Acoustic Target Positioning and Tracking: Progress, Challenges, and Perspectives
Jun 17, 2025Underwater target tracking technology plays a pivotal role in marine resource exploration, environmental monitoring, and national defense security. Given that acoustic waves represent an effective medium for long-distance transmission in aquatic environments, underwater acoustic target tracking has become a prominent research area of underwater communications and networking. Existing literature reviews often offer a narrow perspective or inadequately address the paradigm shifts driven by emerging technologies like deep learning and reinforcement learning. To address these gaps, this work presents a systematic survey of this field and introduces an innovative multidimensional taxonomy framework based on target scale, sensor perception modes, and sensor collaboration patterns. Within this framework, we comprehensively survey the literature (more than 180 publications) over the period 2016-2025, spanning from the theoretical foundations to diverse algorithmic approaches in underwater acoustic target tracking. Particularly, we emphasize the transformative potential and recent advancements of machine learning techniques, including deep learning and reinforcement learning, in enhancing the performance and adaptability of underwater tracking systems. Finally, this survey concludes by identifying key challenges in the field and proposing future avenues based on emerging technologies such as federated learning, blockchain, embodied intelligence, and large models.
Zero-Shot Event Causality Identification via Multi-source Evidence Fuzzy Aggregation with Large Language Models
Jun 06, 2025



Event Causality Identification (ECI) aims to detect causal relationships between events in textual contexts. Existing ECI models predominantly rely on supervised methodologies, suffering from dependence on large-scale annotated data. Although Large Language Models (LLMs) enable zero-shot ECI, they are prone to causal hallucination-erroneously establishing spurious causal links. To address these challenges, we propose MEFA, a novel zero-shot framework based on Multi-source Evidence Fuzzy Aggregation. First, we decompose causality reasoning into three main tasks (temporality determination, necessity analysis, and sufficiency verification) complemented by three auxiliary tasks. Second, leveraging meticulously designed prompts, we guide LLMs to generate uncertain responses and deterministic outputs. Finally, we quantify LLM's responses of sub-tasks and employ fuzzy aggregation to integrate these evidence for causality scoring and causality determination. Extensive experiments on three benchmarks demonstrate that MEFA outperforms second-best unsupervised baselines by 6.2% in F1-score and 9.3% in precision, while significantly reducing hallucination-induced errors. In-depth analysis verify the effectiveness of task decomposition and the superiority of fuzzy aggregation.
Principal Component Maximization: A Novel Method for SAR Image Formation from Raw Data without System Parameters
Mar 18, 2025Synthetic aperture radar (SAR) imaging traditionally requires precise knowledge of system parameters to implement focusing algorithms that transform raw data into high-resolution images. These algorithms require knowledge of SAR system parameters, such as wavelength, center slant range, fast time sampling rate, pulse repetition interval (PRI), waveform parameters (e.g., frequency modulation rate), and platform speed. This paper presents a novel framework for recovering SAR images from raw data without the requirement of any SAR system parameters. Firstly, we introduce an approximate matched filtering model that leverages the inherent shift-invariance properties of SAR echoes, enabling image formation through an adaptive reference echo estimation. To estimate this unknown reference echo, we develop a principal component maximization (PCM) technique that exploits the low-dimensional structure of the SAR signal. The PCM method employs a three-stage procedure: 1) data block segmentation, 2) energy normalization, and 3) principal component energy maximization across blocks, effectively handling non-stationary clutter environments. Secondly, we present a range-varying azimuth reference signal estimation method that compensates for the quadratic phase errors. For cases where PRI is unknown, we propose a two-step PRI estimation scheme that enables robust reconstruction of 2-D images from 1-D data streams. Experimental results on various SAR datasets demonstrate that our method can effectively recover SAR images from raw data without any prior system parameters.
Graph-attention-based Casual Discovery with Trust Region-navigated Clipping Policy Optimization
Dec 27, 2024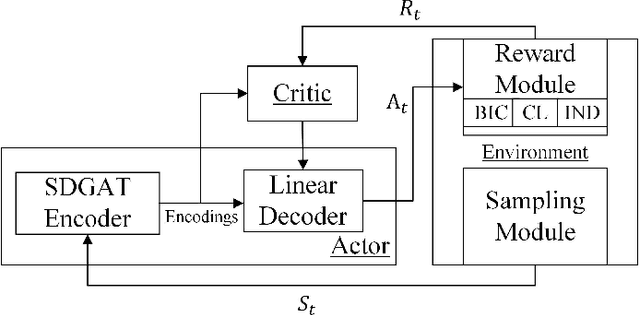
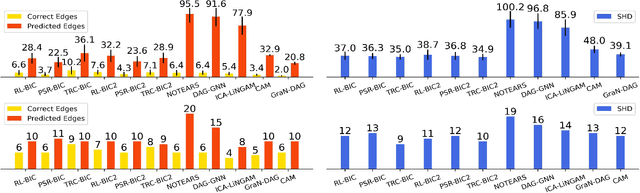
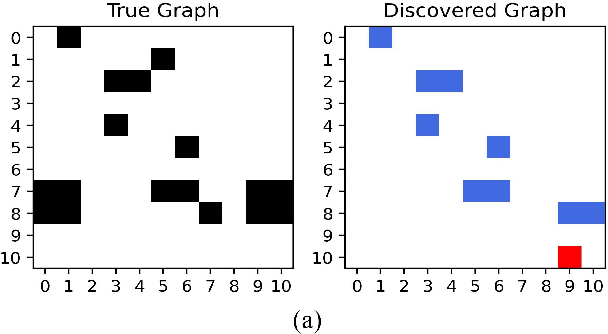
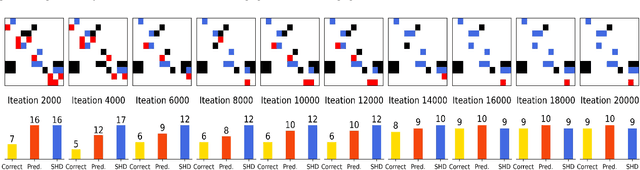
In many domains of empirical sciences, discovering the causal structure within variables remains an indispensable task. Recently, to tackle with unoriented edges or latent assumptions violation suffered by conventional methods, researchers formulated a reinforcement learning (RL) procedure for causal discovery, and equipped REINFORCE algorithm to search for the best-rewarded directed acyclic graph. The two keys to the overall performance of the procedure are the robustness of RL methods and the efficient encoding of variables. However, on the one hand, REINFORCE is prone to local convergence and unstable performance during training. Neither trust region policy optimization, being computationally-expensive, nor proximal policy optimization (PPO), suffering from aggregate constraint deviation, is decent alternative for combinatory optimization problems with considerable individual subactions. We propose a trust region-navigated clipping policy optimization method for causal discovery that guarantees both better search efficiency and steadiness in policy optimization, in comparison with REINFORCE, PPO and our prioritized sampling-guided REINFORCE implementation. On the other hand, to boost the efficient encoding of variables, we propose a refined graph attention encoder called SDGAT that can grasp more feature information without priori neighbourhood information. With these improvements, the proposed method outperforms former RL method in both synthetic and benchmark datasets in terms of output results and optimization robustness.
A Survey of Event Causality Identification: Principles, Taxonomy, Challenges, and Assessment
Nov 15, 2024
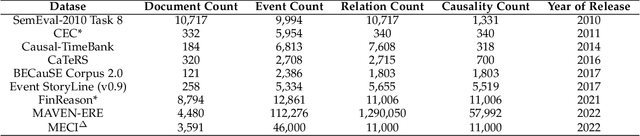
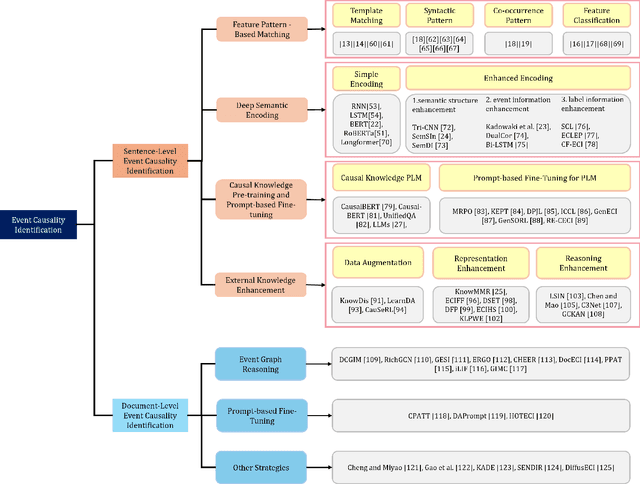

Event Causality Identification (ECI) has become a crucial task in Natural Language Processing (NLP), aimed at automatically extracting causalities from textual data. In this survey, we systematically address the foundational principles, technical frameworks, and challenges of ECI, offering a comprehensive taxonomy to categorize and clarify current research methodologies, as well as a quantitative assessment of existing models. We first establish a conceptual framework for ECI, outlining key definitions, problem formulations, and evaluation standards. Our taxonomy classifies ECI methods according to the two primary tasks of sentence-level (SECI) and document-level (DECI) event causality identification. For SECI, we examine feature pattern-based matching, deep semantic encoding, causal knowledge pre-training and prompt-based fine-tuning, and external knowledge enhancement methods. For DECI, we highlight approaches focused on event graph reasoning and prompt-based techniques to address the complexity of cross-sentence causal inference. Additionally, we analyze the strengths, limitations, and open challenges of each approach. We further conduct an extensive quantitative evaluation of various ECI methods on two benchmark datasets. Finally, we explore future research directions, highlighting promising pathways to overcome current limitations and broaden ECI applications.
Transmit Beampattern Synthesis for Active RIS-Aided MIMO Radar via Waveform and Beamforming Optimization
Oct 07, 2024



In conventional colocated multiple-input multiple-output (MIMO) radars, practical waveform constraints including peak-to-average power ratio, constant or bounded modulus lead to a significant performance reduction of transmit beampattern, especially when the element number is limited. This paper adopts an active reconfigurable intelligent surface (ARIS) to assist the transmit array and discusses the corresponding beampattern synthesis. We aim to minimize the integrated sidelobe-to-mainlobe ratio (ISMR) of beampattern by the codesign of waveform and ARIS reflection coefficients. The resultant problem is nonconvex constrained fractional programming whose objective function and plenty of constraints are variable-coupled. We first convert the fractional objective function into an integral form via Dinkelbach transform, and then alternately optimize the waveform and ARIS reflection coefficients. Three types of waveforms are unifiedly optimized by a consensus alternating direction method of multipliers (CADMM)-based algorithm wherein the global optimal solutions of all subproblems are obtained, while the ARIS reflection coefficients are updated by a concave-convex procedure (CCCP)-based algorithm. The convergence is also analyzed based on the properties of CADMM and CCCP. Numerical results show that ARIS-aided MIMO radars have superior performance than conventional ones due to significant reduction of sidelobe energy.
Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
Apr 06, 2024Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
Conversational Crowdsensing: A Parallel Intelligence Powered Novel Sensing Approach
Feb 04, 2024The transition from CPS-based Industry 4.0 to CPSS-based Industry 5.0 brings new requirements and opportunities to current sensing approaches, especially in light of recent progress in Chatbots and Large Language Models (LLMs). Therefore, the advancement of parallel intelligence-powered Crowdsensing Intelligence (CSI) is witnessed, which is currently advancing towards linguistic intelligence. In this paper, we propose a novel sensing paradigm, namely conversational crowdsensing, for Industry 5.0. It can alleviate workload and professional requirements of individuals and promote the organization and operation of diverse workforce, thereby facilitating faster response and wider popularization of crowdsensing systems. Specifically, we design the architecture of conversational crowdsensing to effectively organize three types of participants (biological, robotic, and digital) from diverse communities. Through three levels of effective conversation (i.e., inter-human, human-AI, and inter-AI), complex interactions and service functionalities of different workers can be achieved to accomplish various tasks across three sensing phases (i.e., requesting, scheduling, and executing). Moreover, we explore the foundational technologies for realizing conversational crowdsensing, encompassing LLM-based multi-agent systems, scenarios engineering and conversational human-AI cooperation. Finally, we present potential industrial applications of conversational crowdsensing and discuss its implications. We envision that conversations in natural language will become the primary communication channel during crowdsensing process, enabling richer information exchange and cooperative problem-solving among humans, robots, and AI.