 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestioning the Coverage-Length Metric in Conformal Prediction: When Shorter Intervals Are Not Better
Jan 29, 2026Conformal prediction (CP) has become a cornerstone of distribution-free uncertainty quantification, conventionally evaluated by its coverage and interval length. This work critically examines the sufficiency of these standard metrics. We demonstrate that the interval length might be deceptively improved through a counter-intuitive approach termed Prejudicial Trick (PT), while the coverage remains valid. Specifically, for any given test sample, PT probabilistically returns an interval, which is either null or constructed using an adjusted confidence level, thereby preserving marginal coverage. While PT potentially yields a deceptively lower interval length, it introduces practical vulnerabilities: the same input can yield completely different prediction intervals across repeated runs of the algorithm. We formally derive the conditions under which PT achieves these misleading improvements and provides extensive empirical evidence across various regression and classification tasks. Furthermore, we introduce a new metric interval stability which helps detect whether a new CP method implicitly improves the length based on such PT-like techniques.
Smoothing-Based Conformal Prediction for Balancing Efficiency and Interpretability
Sep 26, 2025



Conformal Prediction (CP) is a distribution-free framework for constructing statistically rigorous prediction sets. While popular variants such as CD-split improve CP's efficiency, they often yield prediction sets composed of multiple disconnected subintervals, which are difficult to interpret. In this paper, we propose SCD-split, which incorporates smoothing operations into the CP framework. Such smoothing operations potentially help merge the subintervals, thus leading to interpretable prediction sets. Experimental results on both synthetic and real-world datasets demonstrate that SCD-split balances the interval length and the number of disconnected subintervals. Theoretically, under specific conditions, SCD-split provably reduces the number of disconnected subintervals while maintaining comparable coverage guarantees and interval length compared with CD-split.
DrugAgent: Automating AI-aided Drug Discovery Programming through LLM Multi-Agent Collaboration
Nov 24, 2024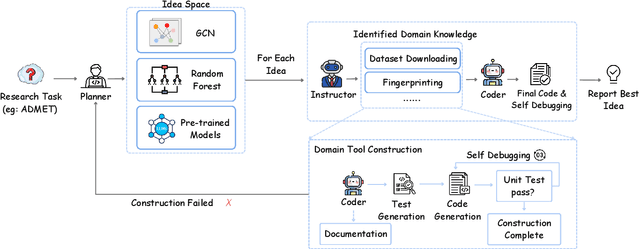
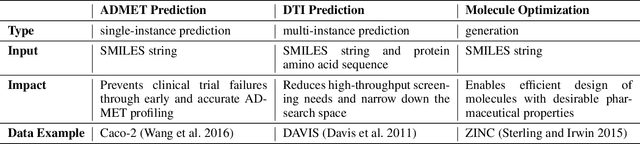

Recent advancements in Large Language Models (LLMs) have opened new avenues for accelerating drug discovery processes. Despite their potential, several critical challenges remain unsolved, particularly in translating theoretical ideas into practical applications within the highly specialized field of pharmaceutical research, limiting practitioners from leveraging the latest AI development in drug discovery. To this end, we introduce DrugAgent, a multi-agent framework aimed at automating machine learning (ML) programming in drug discovery. DrugAgent incorporates domain expertise by identifying specific requirements and building domain-specific tools, while systematically exploring different ideas to find effective solutions. A preliminary case study demonstrates DrugAgent's potential to overcome key limitations LLMs face in drug discovery, moving toward AI-driven innovation. For example, DrugAgent is able to complete the ML programming pipeline end-to-end, from data acquisition to performance evaluation for the ADMET prediction task, and finally select the best model, where the random forest model achieves an F1 score of 0.92 when predicting absorption using the PAMPA dataset.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
Apr 06, 2024Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
Sparsity aware coding for single photon sensitive vision using Selective Sensing
Aug 09, 2023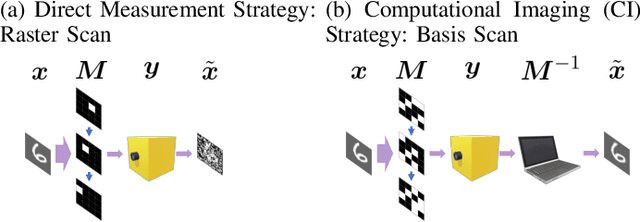
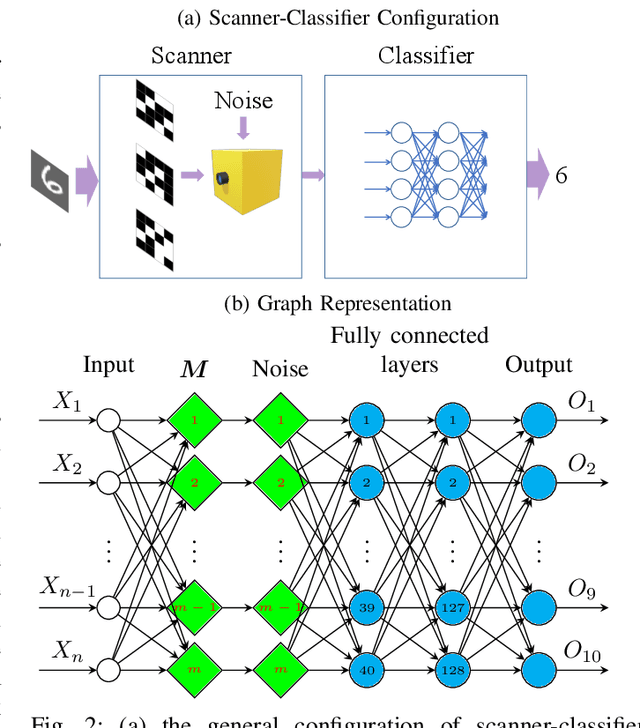
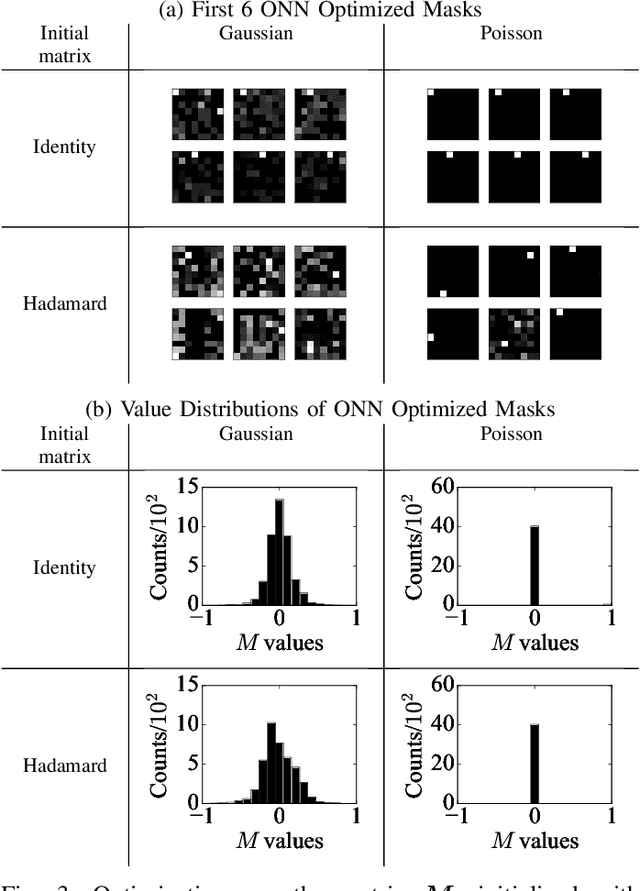
Optical coding has been widely adopted to improve the imaging techniques. Traditional coding strategies developed under additive Gaussian noise fail to perform optimally in the presence of Poisson noise. It has been observed in previous studies that coding performance varies significantly between these two noise models. In this work, we introduce a novel approach called selective sensing, which leverages training data to learn priors and optimizes the coding strategies for downstream classification tasks. By adapting to the specific characteristics of photon-counting sensors, the proposed method aims to improve coding performance under Poisson noise and enhance overall classification accuracy. Experimental and simulated results demonstrate the effectiveness of selective sensing in comparison to traditional coding strategies, highlighting its potential for practical applications in photon counting scenarios where Poisson noise are prevalent.
Layer-wise Fast Adaptation for End-to-End Multi-Accent Speech Recognition
Apr 21, 2022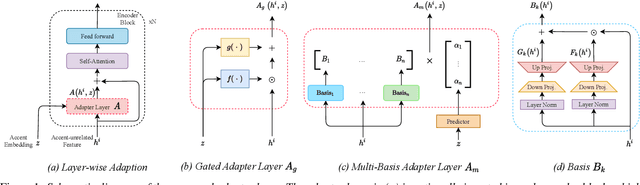
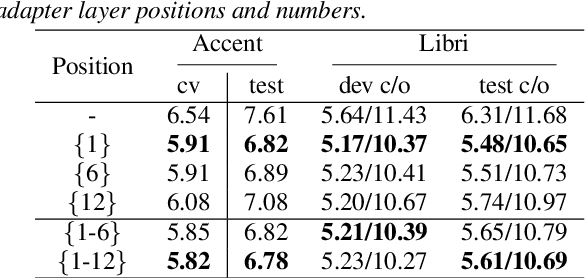
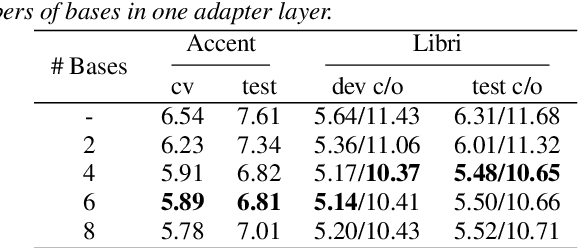
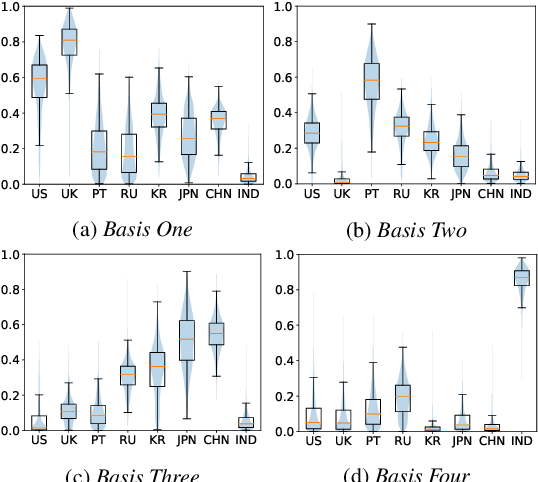
Accent variability has posed a huge challenge to automatic speech recognition~(ASR) modeling. Although one-hot accent vector based adaptation systems are commonly used, they require prior knowledge about the target accent and cannot handle unseen accents. Furthermore, simply concatenating accent embeddings does not make good use of accent knowledge, which has limited improvements. In this work, we aim to tackle these problems with a novel layer-wise adaptation structure injected into the E2E ASR model encoder. The adapter layer encodes an arbitrary accent in the accent space and assists the ASR model in recognizing accented speech. Given an utterance, the adaptation structure extracts the corresponding accent information and transforms the input acoustic feature into an accent-related feature through the linear combination of all accent bases. We further explore the injection position of the adaptation layer, the number of accent bases, and different types of accent bases to achieve better accent adaptation. Experimental results show that the proposed adaptation structure brings 12\% and 10\% relative word error rate~(WER) reduction on the AESRC2020 accent dataset and the Librispeech dataset, respectively, compared to the baseline.
* Accepted by Interspeech2021
Language Adaptive Cross-lingual Speech Representation Learning with Sparse Sharing Sub-networks
Mar 09, 2022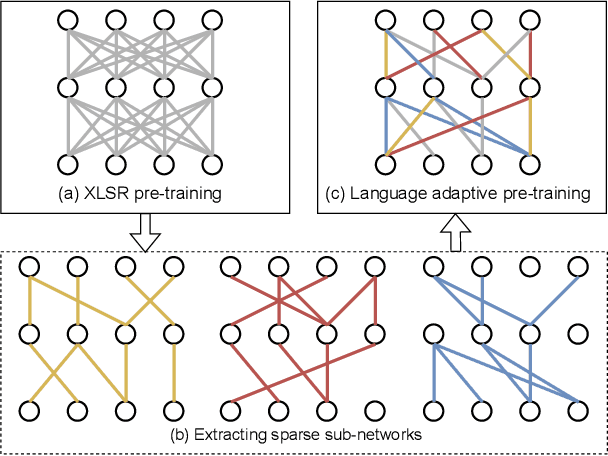
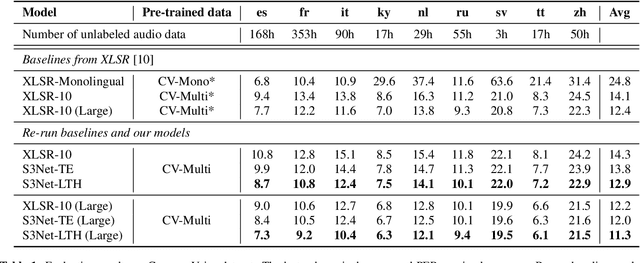
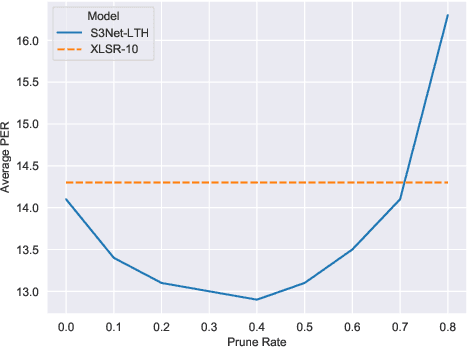
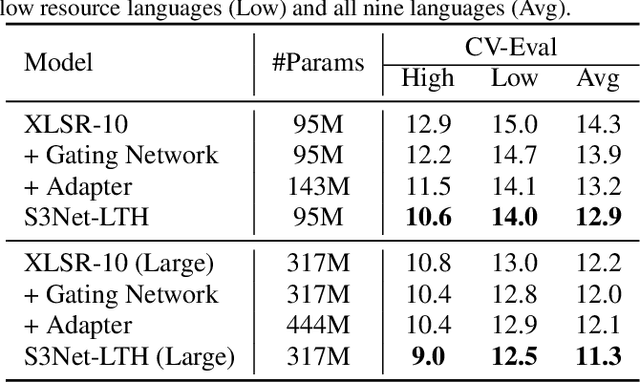
Unsupervised cross-lingual speech representation learning (XLSR) has recently shown promising results in speech recognition by leveraging vast amounts of unlabeled data across multiple languages. However, standard XLSR model suffers from language interference problem due to the lack of language specific modeling ability. In this work, we investigate language adaptive training on XLSR models. More importantly, we propose a novel language adaptive pre-training approach based on sparse sharing sub-networks. It makes room for language specific modeling by pruning out unimportant parameters for each language, without requiring any manually designed language specific component. After pruning, each language only maintains a sparse sub-network, while the sub-networks are partially shared with each other. Experimental results on a downstream multilingual speech recognition task show that our proposed method significantly outperforms baseline XLSR models on both high resource and low resource languages. Besides, our proposed method consistently outperforms other adaptation methods and requires fewer parameters.
The Accented English Speech Recognition Challenge 2020: Open Datasets, Tracks, Baselines, Results and Methods
Feb 20, 2021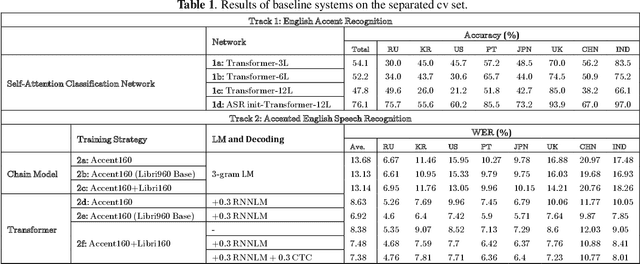
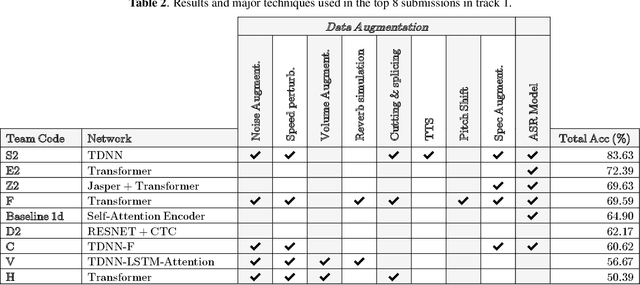
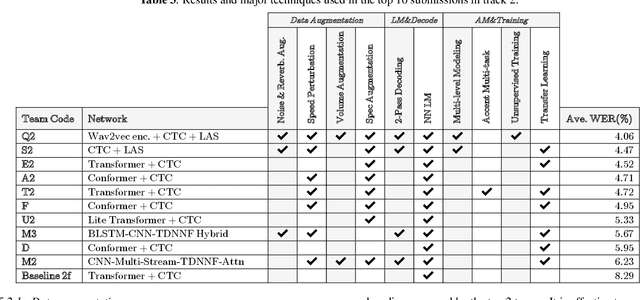
The variety of accents has posed a big challenge to speech recognition. The Accented English Speech Recognition Challenge (AESRC2020) is designed for providing a common testbed and promoting accent-related research. Two tracks are set in the challenge -- English accent recognition (track 1) and accented English speech recognition (track 2). A set of 160 hours of accented English speech collected from 8 countries is released with labels as the training set. Another 20 hours of speech without labels is later released as the test set, including two unseen accents from another two countries used to test the model generalization ability in track 2. We also provide baseline systems for the participants. This paper first reviews the released dataset, track setups, baselines and then summarizes the challenge results and major techniques used in the submissions.
Data Augmentation for End-to-end Code-switching Speech Recognition
Nov 04, 2020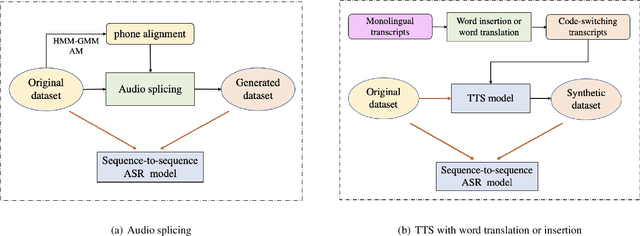
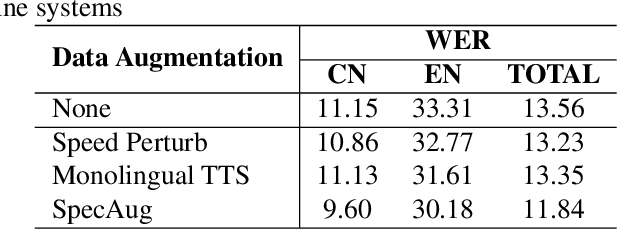
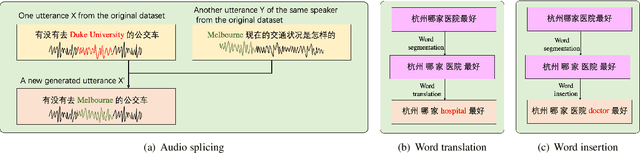
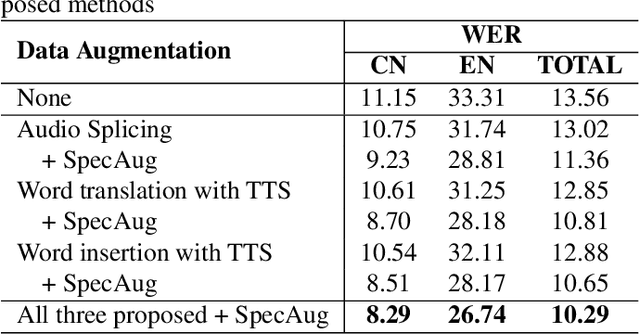
Training a code-switching end-to-end automatic speech recognition (ASR) model normally requires a large amount of data, while code-switching data is often limited. In this paper, three novel approaches are proposed for code-switching data augmentation. Specifically, they are audio splicing with the existing code-switching data, and TTS with new code-switching texts generated by word translation or word insertion. Our experiments on 200 hours Mandarin-English code-switching dataset show that all the three proposed approaches yield significant improvements on code-switching ASR individually. Moreover, all the proposed approaches can be combined with recent popular SpecAugment, and an addition gain can be obtained. WER is significantly reduced by relative 24.0% compared to the system without any data augmentation, and still relative 13.0% gain compared to the system with only SpecAugment