 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Nov 11, 2025Speech-to-Speech (S2S) models have shown promising dialogue capabilities, but their ability to handle paralinguistic cues--such as emotion, tone, and speaker attributes--and to respond appropriately in both content and style remains underexplored. Progress is further hindered by the scarcity of high-quality and expressive demonstrations. To address this, we introduce a novel reinforcement learning (RL) framework for paralinguistic-aware S2S, ParaS2S, which evaluates and optimizes both content and speaking style directly at the waveform level. We first construct ParaS2SBench, a benchmark comprehensively evaluates S2S models' output for content and style appropriateness from diverse and challenging input queries. It scores the fitness of input-output pairs and aligns well with human judgments, serving as an automatic judge for model outputs. With this scalable scoring feedback, we enable the model to explore and learn from diverse unlabeled speech via Group Relative Policy Optimization (GRPO). Experiments show that existing S2S models fail to respond appropriately to paralinguistic attributes, performing no better than pipeline-based baselines. Our RL approach achieves a 11% relative improvement in response content and style's appropriateness on ParaS2SBench over supervised fine-tuning (SFT), surpassing all prior models while requiring substantially fewer warm-up annotations than pure SFT.
Diagnostic-Guided Dynamic Profile Optimization for LLM-based User Simulators in Sequential Recommendation
Aug 18, 2025Recent advances in large language models (LLMs) have enabled realistic user simulators for developing and evaluating recommender systems (RSs). However, existing LLM-based simulators for RSs face two major limitations: (1) static and single-step prompt-based inference that leads to inaccurate and incomplete user profile construction; (2) unrealistic and single-round recommendation-feedback interaction pattern that fails to capture real-world scenarios. To address these limitations, we propose DGDPO (Diagnostic-Guided Dynamic Profile Optimization), a novel framework that constructs user profile through a dynamic and iterative optimization process to enhance the simulation fidelity. Specifically, DGDPO incorporates two core modules within each optimization loop: firstly, a specialized LLM-based diagnostic module, calibrated through our novel training strategy, accurately identifies specific defects in the user profile. Subsequently, a generalized LLM-based treatment module analyzes the diagnosed defect and generates targeted suggestions to refine the profile. Furthermore, unlike existing LLM-based user simulators that are limited to single-round interactions, we are the first to integrate DGDPO with sequential recommenders, enabling a bidirectional evolution where user profiles and recommendation strategies adapt to each other over multi-round interactions. Extensive experiments conducted on three real-world datasets demonstrate the effectiveness of our proposed framework.
Does Knowledge Distillation Matter for Large Language Model based Bundle Generation?
Apr 24, 2025LLMs are increasingly explored for bundle generation, thanks to their reasoning capabilities and knowledge. However, deploying large-scale LLMs introduces significant efficiency challenges, primarily high computational costs during fine-tuning and inference due to their massive parameterization. Knowledge distillation (KD) offers a promising solution, transferring expertise from large teacher models to compact student models. This study systematically investigates knowledge distillation approaches for bundle generation, aiming to minimize computational demands while preserving performance. We explore three critical research questions: (1) how does the format of KD impact bundle generation performance? (2) to what extent does the quantity of distilled knowledge influence performance? and (3) how do different ways of utilizing the distilled knowledge affect performance? We propose a comprehensive KD framework that (i) progressively extracts knowledge (patterns, rules, deep thoughts); (ii) captures varying quantities of distilled knowledge through different strategies; and (iii) exploits complementary LLM adaptation techniques (in-context learning, supervised fine-tuning, combination) to leverage distilled knowledge in small student models for domain-specific adaptation and enhanced efficiency. Extensive experiments provide valuable insights into how knowledge format, quantity, and utilization methodologies collectively shape LLM-based bundle generation performance, exhibiting KD's significant potential for more efficient yet effective LLM-based bundle generation.
Enhancing Adversarial Robustness via Uncertainty-Aware Distributional Adversarial Training
Nov 05, 2024

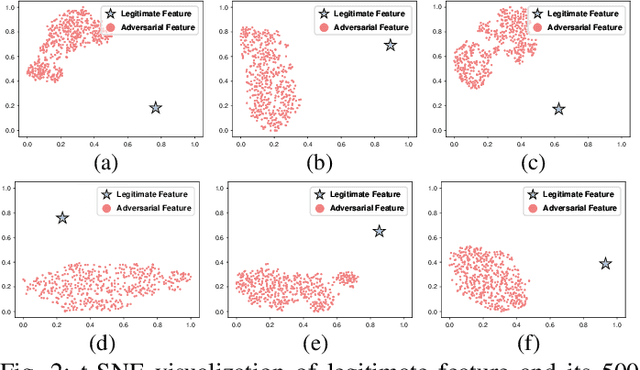
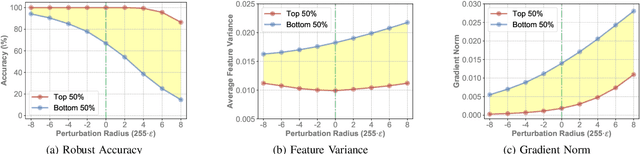
Despite remarkable achievements in deep learning across various domains, its inherent vulnerability to adversarial examples still remains a critical concern for practical deployment. Adversarial training has emerged as one of the most effective defensive techniques for improving model robustness against such malicious inputs. However, existing adversarial training schemes often lead to limited generalization ability against underlying adversaries with diversity due to their overreliance on a point-by-point augmentation strategy by mapping each clean example to its adversarial counterpart during training. In addition, adversarial examples can induce significant disruptions in the statistical information w.r.t. the target model, thereby introducing substantial uncertainty and challenges to modeling the distribution of adversarial examples. To circumvent these issues, in this paper, we propose a novel uncertainty-aware distributional adversarial training method, which enforces adversary modeling by leveraging both the statistical information of adversarial examples and its corresponding uncertainty estimation, with the goal of augmenting the diversity of adversaries. Considering the potentially negative impact induced by aligning adversaries to misclassified clean examples, we also refine the alignment reference based on the statistical proximity to clean examples during adversarial training, thereby reframing adversarial training within a distribution-to-distribution matching framework interacted between the clean and adversarial domains. Furthermore, we design an introspective gradient alignment approach via matching input gradients between these domains without introducing external models. Extensive experiments across four benchmark datasets and various network architectures demonstrate that our approach achieves state-of-the-art adversarial robustness and maintains natural performance.
Dynamic In-Context Learning from Nearest Neighbors for Bundle Generation
Dec 26, 2023Product bundling has evolved into a crucial marketing strategy in e-commerce. However, current studies are limited to generating (1) fixed-size or single bundles, and most importantly, (2) bundles that do not reflect consistent user intents, thus being less intelligible or useful to users. This paper explores two interrelated tasks, i.e., personalized bundle generation and the underlying intent inference based on users' interactions in a session, leveraging the logical reasoning capability of large language models. We introduce a dynamic in-context learning paradigm, which enables ChatGPT to seek tailored and dynamic lessons from closely related sessions as demonstrations while performing tasks in the target session. Specifically, it first harnesses retrieval augmented generation to identify nearest neighbor sessions for each target session. Then, proper prompts are designed to guide ChatGPT to perform the two tasks on neighbor sessions. To enhance reliability and mitigate the hallucination issue, we develop (1) a self-correction strategy to foster mutual improvement in both tasks without supervision signals; and (2) an auto-feedback mechanism to recurrently offer dynamic supervision based on the distinct mistakes made by ChatGPT on various neighbor sessions. Thus, the target session can receive customized and dynamic lessons for improved performance by observing the demonstrations of its neighbor sessions. Finally, experimental results on three real-world datasets verify the effectiveness of our methods on both tasks. Additionally, the inferred intents can prove beneficial for other intriguing downstream tasks, such as crafting appealing bundle names.
Large Language Models for Intent-Driven Session Recommendations
Dec 07, 2023Intent-aware session recommendation (ISR) is pivotal in discerning user intents within sessions for precise predictions. Traditional approaches, however, face limitations due to their presumption of a uniform number of intents across all sessions. This assumption overlooks the dynamic nature of user sessions, where the number and type of intentions can significantly vary. In addition, these methods typically operate in latent spaces, thus hinder the model's transparency.Addressing these challenges, we introduce a novel ISR approach, utilizing the advanced reasoning capabilities of large language models (LLMs). First, this approach begins by generating an initial prompt that guides LLMs to predict the next item in a session, based on the varied intents manifested in user sessions. Then, to refine this process, we introduce an innovative prompt optimization mechanism that iteratively self-reflects and adjusts prompts. Furthermore, our prompt selection module, built upon the LLMs' broad adaptability, swiftly selects the most optimized prompts across diverse domains. This new paradigm empowers LLMs to discern diverse user intents at a semantic level, leading to more accurate and interpretable session recommendations. Our extensive experiments on three real-world datasets demonstrate the effectiveness of our method, marking a significant advancement in ISR systems.
Large Language Models as Evolutionary Optimizers
Nov 01, 2023



Evolutionary algorithms (EAs) have achieved remarkable success in tackling complex combinatorial optimization problems. However, EAs often demand carefully-designed operators with the aid of domain expertise to achieve satisfactory performance. In this work, we present the first study on large language models (LLMs) as evolutionary combinatorial optimizers. The main advantage is that it requires minimal domain knowledge and human efforts, as well as no additional training of the model. This approach is referred to as LLM-driven EA (LMEA). Specifically, in each generation of the evolutionary search, LMEA instructs the LLM to select parent solutions from current population, and perform crossover and mutation to generate offspring solutions. Then, LMEA evaluates these new solutions and include them into the population for the next generation. LMEA is equipped with a self-adaptation mechanism that controls the temperature of the LLM. This enables it to balance between exploration and exploitation and prevents the search from getting stuck in local optima. We investigate the power of LMEA on the classical traveling salesman problems (TSPs) widely used in combinatorial optimization research. Notably, the results show that LMEA performs competitively to traditional heuristics in finding high-quality solutions on TSP instances with up to 20 nodes. Additionally, we also study the effectiveness of LLM-driven crossover/mutation and the self-adaptation mechanism in evolutionary search. In summary, our results reveal the great potentials of LLMs as evolutionary optimizers for solving combinatorial problems. We hope our research shall inspire future explorations on LLM-driven EAs for complex optimization challenges.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.
Policy Resilience to Environment Poisoning Attacks on Reinforcement Learning
Apr 24, 2023



This paper investigates policy resilience to training-environment poisoning attacks on reinforcement learning (RL) policies, with the goal of recovering the deployment performance of a poisoned RL policy. Due to the fact that the policy resilience is an add-on concern to RL algorithms, it should be resource-efficient, time-conserving, and widely applicable without compromising the performance of RL algorithms. This paper proposes such a policy-resilience mechanism based on an idea of knowledge sharing. We summarize the policy resilience as three stages: preparation, diagnosis, recovery. Specifically, we design the mechanism as a federated architecture coupled with a meta-learning manner, pursuing an efficient extraction and sharing of the environment knowledge. With the shared knowledge, a poisoned agent can quickly identify the deployment condition and accordingly recover its policy performance. We empirically evaluate the resilience mechanism for both model-based and model-free RL algorithms, showing its effectiveness and efficiency in restoring the deployment performance of a poisoned policy.
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022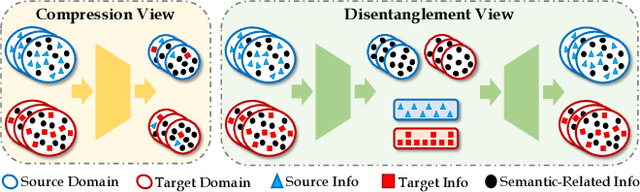
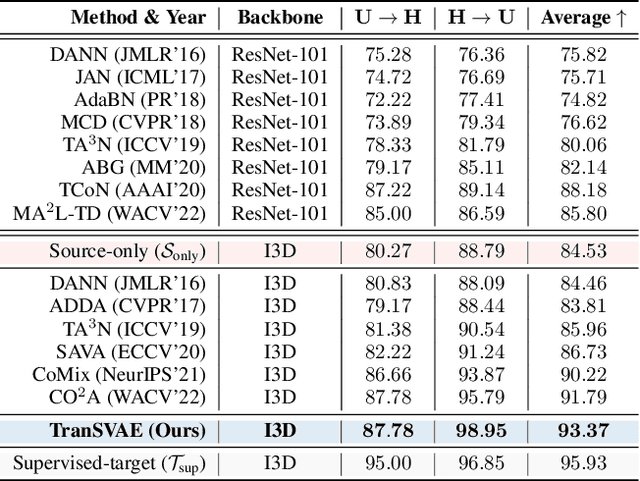
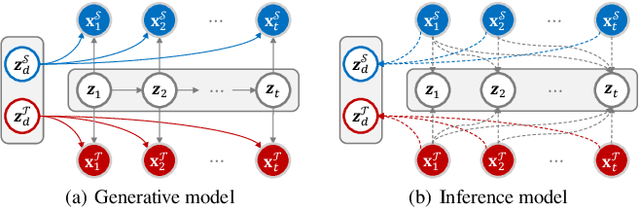
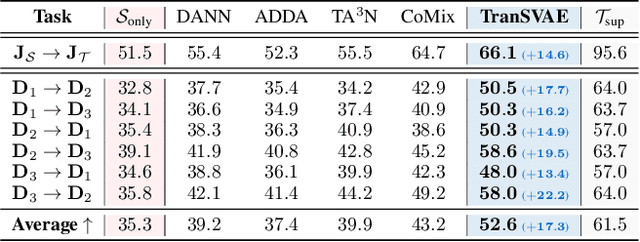
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.