 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulReaD: Knowledge-Graph-guided Software Vulnerability Reasoning and Detection
Feb 11, 2026Software vulnerability detection (SVD) is a critical challenge in modern systems. Large language models (LLMs) offer natural-language explanations alongside predictions, but most work focuses on binary evaluation, and explanations often lack semantic consistency with Common Weakness Enumeration (CWE) categories. We propose VulReaD, a knowledge-graph-guided approach for vulnerability reasoning and detection that moves beyond binary classification toward CWE-level reasoning. VulReaD leverages a security knowledge graph (KG) as a semantic backbone and uses a strong teacher LLM to generate CWE-consistent contrastive reasoning supervision, enabling student model training without manual annotations. Students are fine-tuned with Odds Ratio Preference Optimization (ORPO) to encourage taxonomy-aligned reasoning while suppressing unsupported explanations. Across three real-world datasets, VulReaD improves binary F1 by 8-10% and multi-class classification by 30% Macro-F1 and 18% Micro-F1 compared to state-of-the-art baselines. Results show that LLMs outperform deep learning baselines in binary detection and that KG-guided reasoning enhances CWE coverage and interpretability.
Quality Diversity Genetic Programming for Learning Scheduling Heuristics
Jul 03, 2025Real-world optimization often demands diverse, high-quality solutions. Quality-Diversity (QD) optimization is a multifaceted approach in evolutionary algorithms that aims to generate a set of solutions that are both high-performing and diverse. QD algorithms have been successfully applied across various domains, providing robust solutions by exploring diverse behavioral niches. However, their application has primarily focused on static problems, with limited exploration in the context of dynamic combinatorial optimization problems. Furthermore, the theoretical understanding of QD algorithms remains underdeveloped, particularly when applied to learning heuristics instead of directly learning solutions in complex and dynamic combinatorial optimization domains, which introduces additional challenges. This paper introduces a novel QD framework for dynamic scheduling problems. We propose a map-building strategy that visualizes the solution space by linking heuristic genotypes to their behaviors, enabling their representation on a QD map. This map facilitates the discovery and maintenance of diverse scheduling heuristics. Additionally, we conduct experiments on both fixed and dynamically changing training instances to demonstrate how the map evolves and how the distribution of solutions unfolds over time. We also discuss potential future research directions that could enhance the learning process and broaden the applicability of QD algorithms to dynamic combinatorial optimization challenges.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
MRP-LLM: Multitask Reflective Large Language Models for Privacy-Preserving Next POI Recommendation
Dec 03, 2024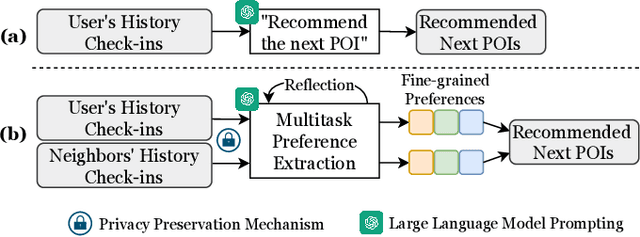
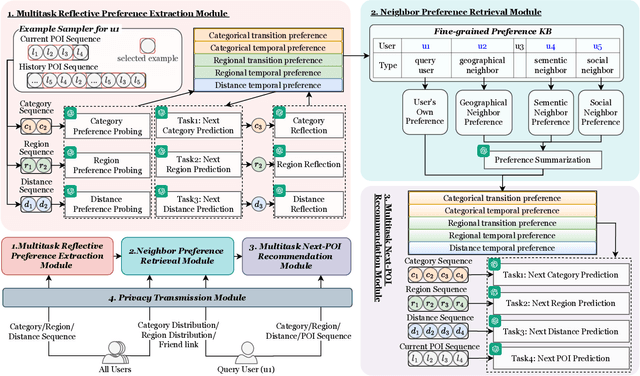
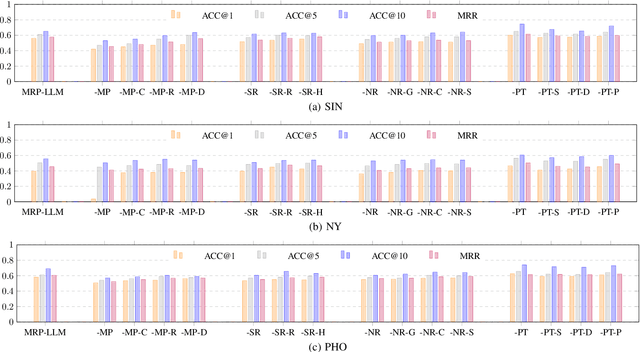
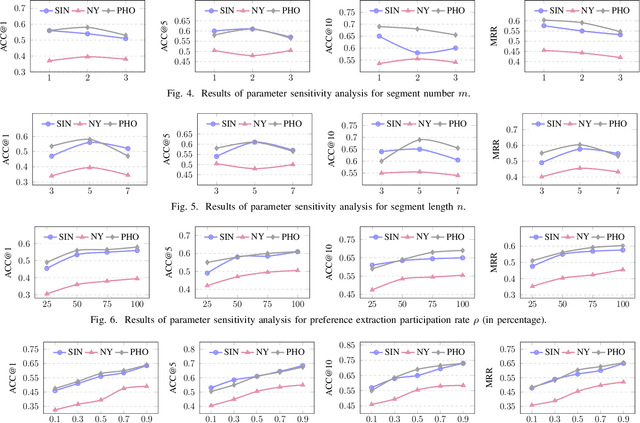
Large language models (LLMs) have shown promising potential for next Point-of-Interest (POI) recommendation. However, existing methods only perform direct zero-shot prompting, leading to ineffective extraction of user preferences, insufficient injection of collaborative signals, and a lack of user privacy protection. As such, we propose a novel Multitask Reflective Large Language Model for Privacy-preserving Next POI Recommendation (MRP-LLM), aiming to exploit LLMs for better next POI recommendation while preserving user privacy. Specifically, the Multitask Reflective Preference Extraction Module first utilizes LLMs to distill each user's fine-grained (i.e., categorical, temporal, and spatial) preferences into a knowledge base (KB). The Neighbor Preference Retrieval Module retrieves and summarizes the preferences of similar users from the KB to obtain collaborative signals. Subsequently, aggregating the user's preferences with those of similar users, the Multitask Next POI Recommendation Module generates the next POI recommendations via multitask prompting. Meanwhile, during data collection, a Privacy Transmission Module is specifically devised to preserve sensitive POI data. Extensive experiments on three real-world datasets demonstrate the efficacy of our proposed MRP-LLM in providing more accurate next POI recommendations with user privacy preserved.
Dockformer: A transformer-based molecular docking paradigm for large-scale virtual screening
Nov 15, 2024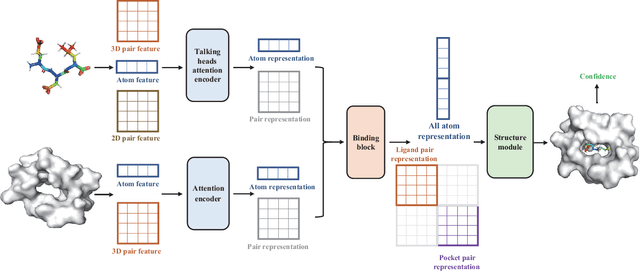
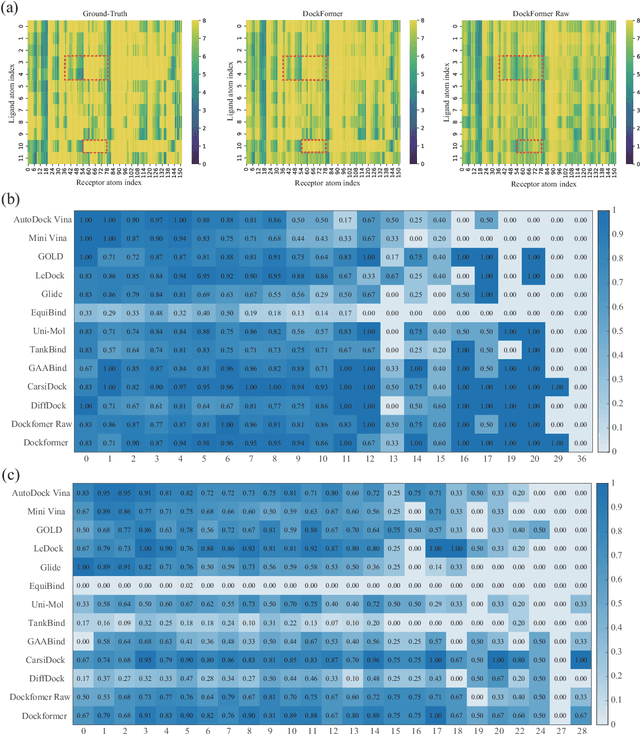
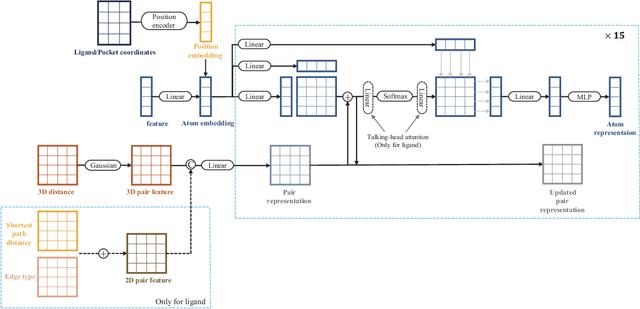
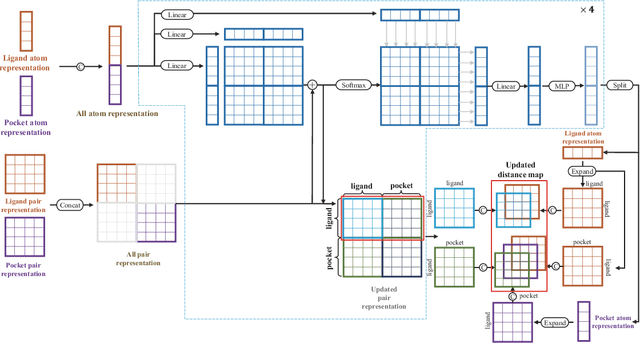
Molecular docking enables virtual screening of compound libraries to identify potential ligands that target proteins of interest, a crucial step in drug development; however, as the size of the compound library increases, the computational complexity of traditional docking models increases. Deep learning algorithms can provide data-driven research and development models to increase the speed of the docking process. Unfortunately, few models can achieve superior screening performance compared to that of traditional models. Therefore, a novel deep learning-based docking approach named Dockformer is introduced in this study. Dockformer leverages multimodal information to capture the geometric topology and structural knowledge of molecules and can directly generate binding conformations with the corresponding confidence measures in an end-to-end manner. The experimental results show that Dockformer achieves success rates of 90.53\% and 82.71\% on the PDBbind core set and PoseBusters benchmarks, respectively, and more than a 100-fold increase in the inference process speed, outperforming almost all state-of-the-art docking methods. In addition, the ability of Dockformer to identify the main protease inhibitors of coronaviruses is demonstrated in a real-world virtual screening scenario. Considering its high docking accuracy and screening efficiency, Dockformer can be regarded as a powerful and robust tool in the field of drug design.
LLM2FEA: Discover Novel Designs with Generative Evolutionary Multitasking
Jun 21, 2024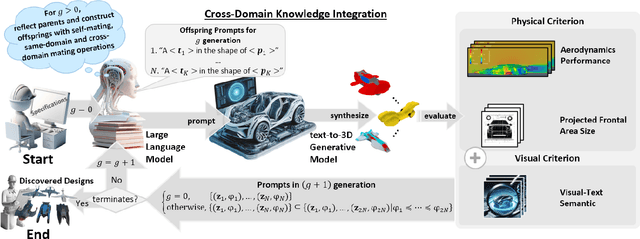
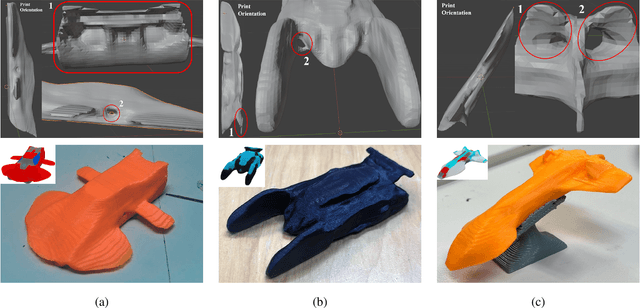
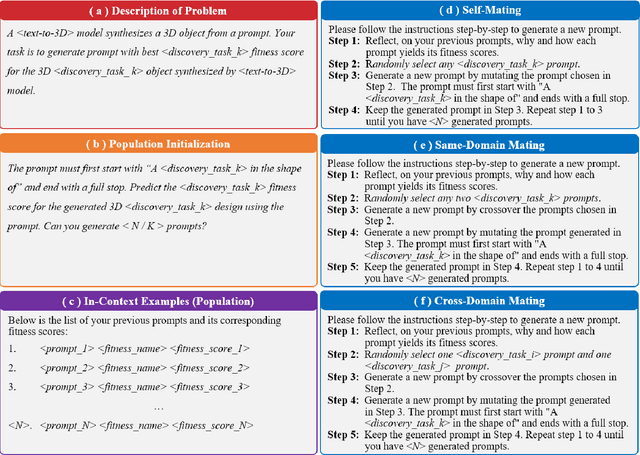

The rapid research and development of generative artificial intelligence has enabled the generation of high-quality images, text, and 3D models from text prompts. This advancement impels an inquiry into whether these models can be leveraged to create digital artifacts for both creative and engineering applications. Drawing on innovative designs from other domains may be one answer to this question, much like the historical practice of ``bionics", where humans have sought inspiration from nature's exemplary designs. This raises the intriguing possibility of using generative models to simultaneously tackle design tasks across multiple domains, facilitating cross-domain learning and resulting in a series of innovative design solutions. In this paper, we propose LLM2FEA as the first attempt to discover novel designs in generative models by transferring knowledge across multiple domains. By utilizing a multi-factorial evolutionary algorithm (MFEA) to drive a large language model, LLM2FEA integrates knowledge from various fields to generate prompts that guide the generative model in discovering novel and practical objects. Experimental results in the context of 3D aerodynamic design verify the discovery capabilities of the proposed LLM2FEA. The designs generated by LLM2FEA not only satisfy practicality requirements to a certain degree but also feature novel and aesthetically pleasing shapes, demonstrating the potential applications of LLM2FEA in discovery tasks.
Generative AI-based Prompt Evolution Engineering Design Optimization With Vision-Language Model
Jun 14, 2024
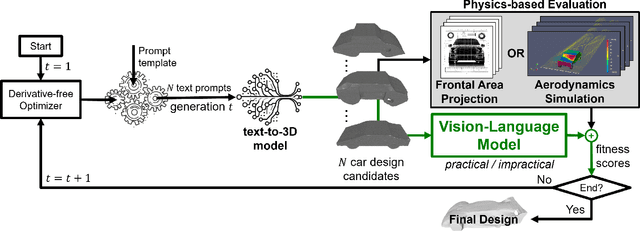
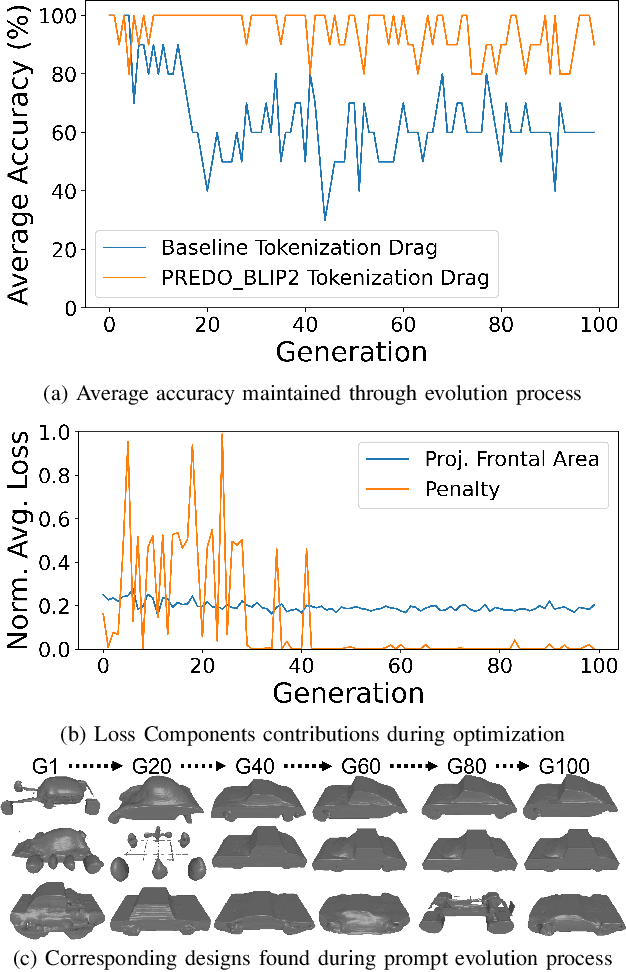

Engineering design optimization requires an efficient combination of a 3D shape representation, an optimization algorithm, and a design performance evaluation method, which is often computationally expensive. We present a prompt evolution design optimization (PEDO) framework contextualized in a vehicle design scenario that leverages a vision-language model for penalizing impractical car designs synthesized by a generative model. The backbone of our framework is an evolutionary strategy coupled with an optimization objective function that comprises a physics-based solver and a vision-language model for practical or functional guidance in the generated car designs. In the prompt evolutionary search, the optimizer iteratively generates a population of text prompts, which embed user specifications on the aerodynamic performance and visual preferences of the 3D car designs. Then, in addition to the computational fluid dynamics simulations, the pre-trained vision-language model is used to penalize impractical designs and, thus, foster the evolutionary algorithm to seek more viable designs. Our investigations on a car design optimization problem show a wide spread of potential car designs generated at the early phase of the search, which indicates a good diversity of designs in the initial populations, and an increase of over 20\% in the probability of generating practical designs compared to a baseline framework without using a vision-language model. Visual inspection of the designs against the performance results demonstrates prompt evolution as a very promising paradigm for finding novel designs with good optimization performance while providing ease of use in specifying design specifications and preferences via a natural language interface.
Covariance-Adaptive Sequential Black-box Optimization for Diffusion Targeted Generation
Jun 02, 2024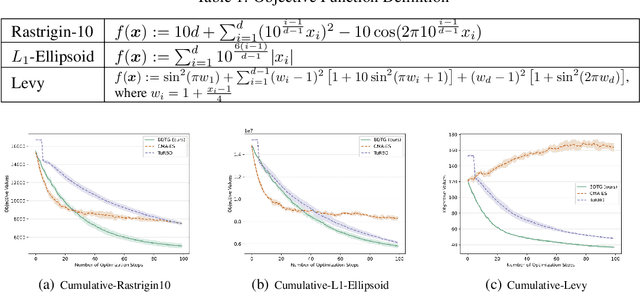
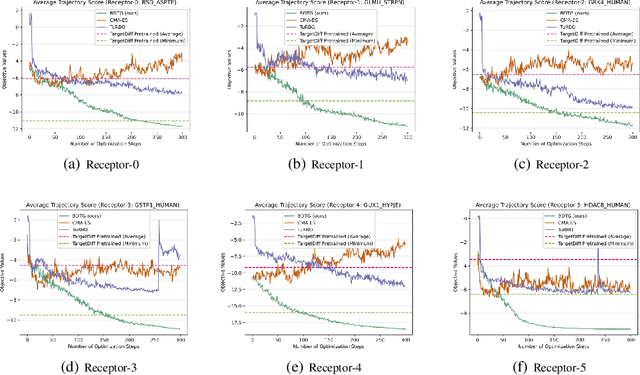
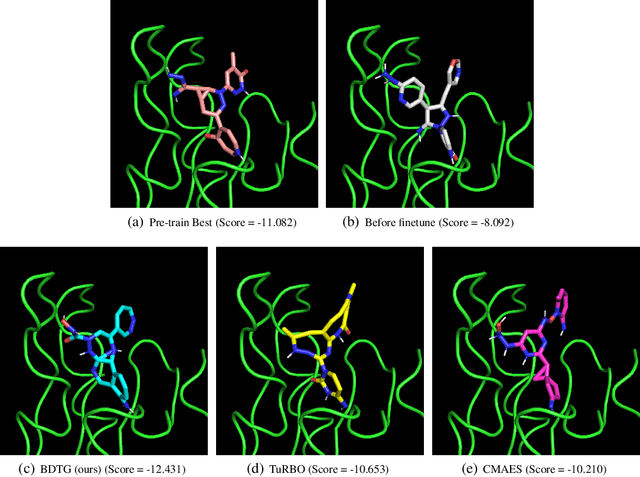
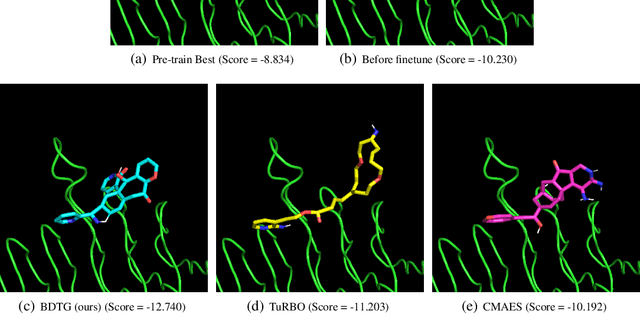
Diffusion models have demonstrated great potential in generating high-quality content for images, natural language, protein domains, etc. However, how to perform user-preferred targeted generation via diffusion models with only black-box target scores of users remains challenging. To address this issue, we first formulate the fine-tuning of the targeted reserve-time stochastic differential equation (SDE) associated with a pre-trained diffusion model as a sequential black-box optimization problem. Furthermore, we propose a novel covariance-adaptive sequential optimization algorithm to optimize cumulative black-box scores under unknown transition dynamics. Theoretically, we prove a $O(\frac{d^2}{\sqrt{T}})$ convergence rate for cumulative convex functions without smooth and strongly convex assumptions. Empirically, experiments on both numerical test problems and target-guided 3D-molecule generation tasks show the superior performance of our method in achieving better target scores.
Human-Generative AI Collaborative Problem Solving Who Leads and How Students Perceive the Interactions
May 19, 2024This research investigates distinct human-generative AI collaboration types and students' interaction experiences when collaborating with generative AI (i.e., ChatGPT) for problem-solving tasks and how these factors relate to students' sense of agency and perceived collaborative problem solving. By analyzing the surveys and reflections of 79 undergraduate students, we identified three human-generative AI collaboration types: even contribution, human leads, and AI leads. Notably, our study shows that 77.21% of students perceived they led or had even contributed to collaborative problem-solving when collaborating with ChatGPT. On the other hand, 15.19% of the human participants indicated that the collaborations were led by ChatGPT, indicating a potential tendency for students to rely on ChatGPT. Furthermore, 67.09% of students perceived their interaction experiences with ChatGPT to be positive or mixed. We also found a positive correlation between positive interaction experience and a sense of positive agency. The results of this study contribute to our understanding of the collaboration between students and generative AI and highlight the need to study further why some students let ChatGPT lead collaborative problem-solving and how to enhance their interaction experience through curriculum and technology design.
LIST: Learning to Index Spatio-Textual Data for Embedding based Spatial Keyword Queries
Mar 18, 2024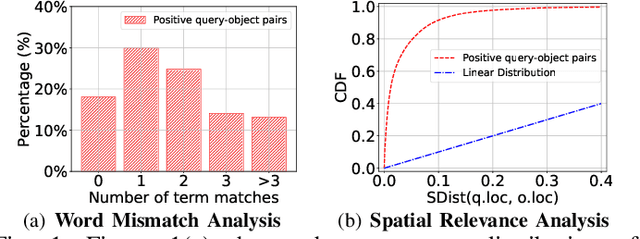
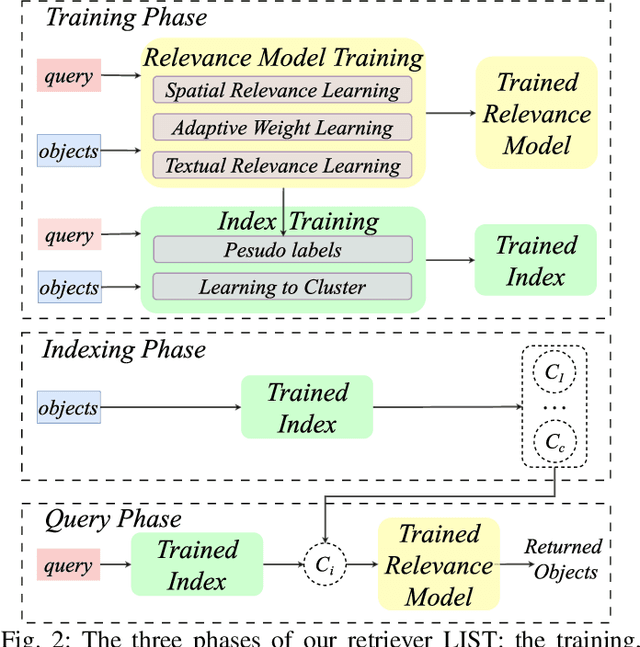
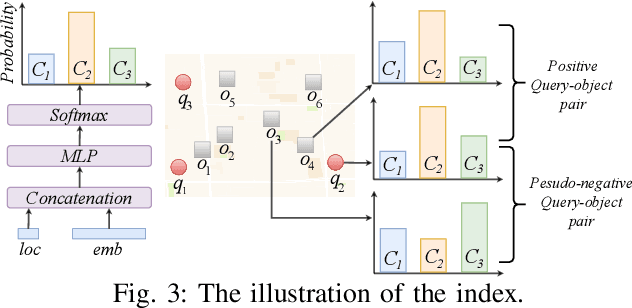
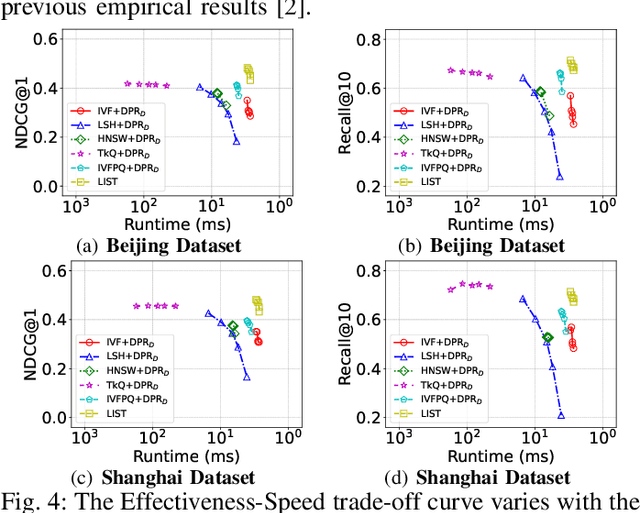
With the proliferation of spatio-textual data, Top-k KNN spatial keyword queries (TkQs), which return a list of objects based on a ranking function that evaluates both spatial and textual relevance, have found many real-life applications. Existing geo-textual indexes for TkQs use traditional retrieval models like BM25 to compute text relevance and usually exploit a simple linear function to compute spatial relevance, but its effectiveness is limited. To improve effectiveness, several deep learning models have recently been proposed, but they suffer severe efficiency issues. To the best of our knowledge, there are no efficient indexes specifically designed to accelerate the top-k search process for these deep learning models. To tackle these issues, we propose a novel technique, which Learns to Index the Spatio-Textual data for answering embedding based spatial keyword queries (called LIST). LIST is featured with two novel components. Firstly, we propose a lightweight and effective relevance model that is capable of learning both textual and spatial relevance. Secondly, we introduce a novel machine learning based Approximate Nearest Neighbor Search (ANNS) index, which utilizes a new learning-to-cluster technique to group relevant queries and objects together while separating irrelevant queries and objects. Two key challenges in building an effective and efficient index are the absence of high-quality labels and unbalanced clustering results. We develop a novel pseudo-label generation technique to address the two challenges. Experimental results show that LIST significantly outperforms state-of-the-art methods on effectiveness, with improvements up to 19.21% and 12.79% in terms of NDCG@1 and Recall@10, and is three orders of magnitude faster than the most effective baseline.