 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Adapt: Multimodal Coreference Resolution at First Sight with a Pretrained Alignment Model
Jun 16, 2026Visual information helps resolve ambiguity in coreference resolution, leading to notable performance gains. However, existing Multi-modal Coreference Resolution (MCR) methods require training with (partially) annotated data from the target dataset before they can be applied, preventing their direct usability and raising concerns about generalization. While Vision-Language Large Models (VLLMs) with billions of parameters offer promising zero-shot capabilities, they remain largely inaccessible. Their massive size limits deployability, and many are only accessible through paid APIs. In this paper, we propose a plug-and-adapt method that strategically adapts a carefully pre-trained \emph{alignment model} for immediate use in MCR tasks, designed to eliminate the need for training on scarce benchmark datasets or relying on resource-intensive VLLMs. Specifically, we first pre-train a fine-grained alignment model between textual and visual contextual information using vision-language alignment datasets. We then repurpose the alignment model to MCR through similarity aggregation by fusing visual and categorical cues with evidence theory, thereby enhancing effectiveness. Experiments on the Coreference Image Narratives (CIN) benchmark dataset demonstrate the effectiveness of our method, achieving a 5.31\% and 2.12\% improvement in CoNLL F1 over SOTA dedicated methods and popular VLLMs, respectively. We further evaluate our method on a masked CIN dataset for robustness testing and on a specially constructed VCR-MCR dataset for generalization assessment, with results confirming both capabilities.
SkillDAG: Self-Evolving Typed Skill Graphs for LLM Skill Selection at Scale
Jun 02, 2026As LLM agents adopt large skill libraries, selecting the right subset becomes a structural problem rather than a similarity-matching one: skills depend on, conflict with, specialize, or duplicate one another, a structure invisible to both full enumeration and embedding similarity. We present SkillDAG, which models inter-skill relationships as a typed directed graph and exposes it to an LLM agent as an inference-time, agent-callable structural retrieval interface, queried and evolved during execution rather than baked into a fixed retrieval pipeline: each search returns vector matches, typed-edge neighbors, and conflict signals, and a propose-then-commit protocol lets the agent register execution-backed edges so the graph accumulates structure across episodes. On ALFWorld and SkillsBench with MiniMax-M2.7, SkillDAG reaches 67.1% success and 27.3% reward, exceeding the strongest reported Graph-of-Skills baseline by +12.8 and +8.6 points; the advantage ports to gpt-5.2-codex, and intrinsic SkillsBench Ret@K rises from 65.5 to 78.2 under matched queries. These gains trace to isolable mechanisms: candidate ranking that stays robust as the pool grows 10x where a fixed seeding-diffusion pipeline degrades, and set-monotone online edits that enlarge ground-truth recall without evicting prior hits.
Adversarial Dual On-Policy Distillation from Expressive Flow-based Teacher
May 26, 2026Learning from demonstrations in embodied control is often cast as behavioral cloning, and recent diffusion or flow-matching policies improve this paradigm by modeling multi-modal expert actions. Yet these methods remain offline supervised learners: the policy is trained only on expert states and receives no corrective signal on the states it actually visits. On-policy distillation (OPD) offers a natural remedy, but standard OPD assumes a strong fixed teacher, which is unavailable in demonstration-only control. We propose \textbf{FA-OPD}, an \emph{adversarial dual on-policy distillation} method in which a Flow Matching (FM) teacher is learned from demonstrations and co-trained with a lightweight MLP student. The teacher provides two complementary signals on student rollouts. The reward channel learns an expert-likeness objective over state-action pairs and drives online exploration through long-horizon policy optimization. The action channel supplies dense local targets at student-visited states, stabilizing exploitation. FA-OPD couples them so that reward distillation enables generalization beyond point-wise demonstrations, while action distillation keeps exploration anchored near expert-like behavior. Across six robot navigation, manipulation, and locomotion benchmarks, FA-OPD beats strong baselines and shows much stronger robustness under noisy or limited demonstrations.
IKNO: Infinite-order Kernel Neural Operators
May 21, 2026Neural operators have achieved significant success in modern scientific computing due to their flexibility and strong generalization capabilities. Existing models, however, primarily rely on first-order kernel integral approximations, which severely limit their expressivity. To address this, we propose the Infinite-order Kernel Neural Operator (IKNO), which constructs neural operators via infinite-order kernel integrals and admits an elegant closed-form finite approximation. We develop two complementary infinite-order neural operator constructions: IKNO-Vanilla, which applies the full-kernel resolvent on the product grid via Kronecker eigendecomposition, and IKNO-TP, an alternative tensor-product operator that composes per-axis resolvents. Furthermore, we develop fast computation schemes for both variants of IKNO, which achieve outstanding global information aggregation while maintaining high computational efficiency. Empirically, we evaluate our IKNO on both time-dependent and time-independent benchmarks with arbitrary input shapes, including large-scale industrial datasets. Extensive experiments demonstrate that the IKNO method consistently achieves the SOTA accuracy with significant improvements on nearly all benchmark datasets while maintaining scalability to very large point clouds.
Dataset Color Quantization: A Training-Oriented Framework for Dataset-Level Compression
Feb 24, 2026Large-scale image datasets are fundamental to deep learning, but their high storage demands pose challenges for deployment in resource-constrained environments. While existing approaches reduce dataset size by discarding samples, they often ignore the significant redundancy within each image -- particularly in the color space. To address this, we propose Dataset Color Quantization (DCQ), a unified framework that compresses visual datasets by reducing color-space redundancy while preserving information crucial for model training. DCQ achieves this by enforcing consistent palette representations across similar images, selectively retaining semantically important colors guided by model perception, and maintaining structural details necessary for effective feature learning. Extensive experiments across CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that DCQ significantly improves training performance under aggressive compression, offering a scalable and robust solution for dataset-level storage reduction. Code is available at \href{https://github.com/he-y/Dataset-Color-Quantization}{https://github.com/he-y/Dataset-Color-Quantization}.
Olaf-World: Orienting Latent Actions for Video World Modeling
Feb 10, 2026Scaling action-controllable world models is limited by the scarcity of action labels. While latent action learning promises to extract control interfaces from unlabeled video, learned latents often fail to transfer across contexts: they entangle scene-specific cues and lack a shared coordinate system. This occurs because standard objectives operate only within each clip, providing no mechanism to align action semantics across contexts. Our key insight is that although actions are unobserved, their semantic effects are observable and can serve as a shared reference. We introduce Seq$Δ$-REPA, a sequence-level control-effect alignment objective that anchors integrated latent action to temporal feature differences from a frozen, self-supervised video encoder. Building on this, we present Olaf-World, a pipeline that pretrains action-conditioned video world models from large-scale passive video. Extensive experiments demonstrate that our method learns a more structured latent action space, leading to stronger zero-shot action transfer and more data-efficient adaptation to new control interfaces than state-of-the-art baselines.
Collaborative Group-Aware Hashing for Fast Recommender Systems
Dec 23, 2025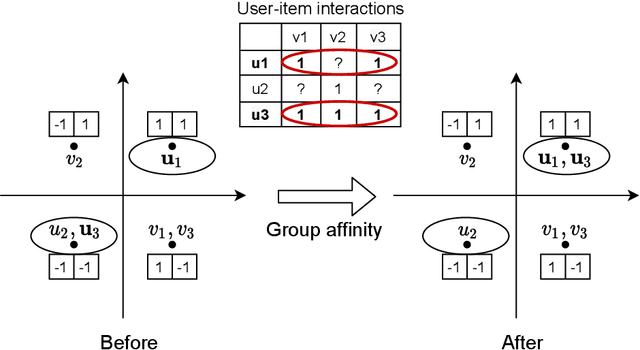

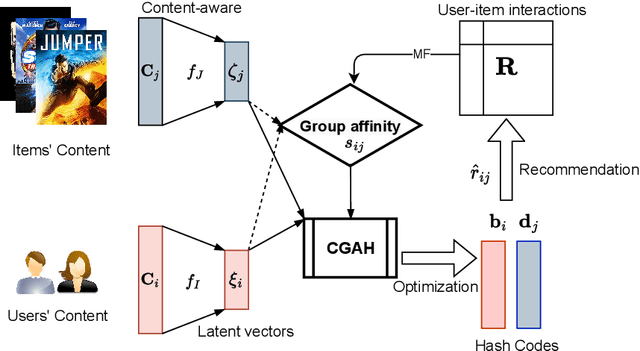
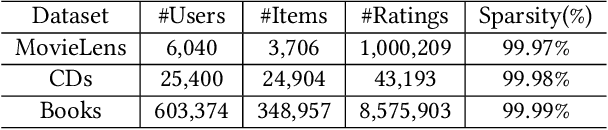
The fast online recommendation is critical for applications with large-scale databases; meanwhile, it is challenging to provide accurate recommendations in sparse scenarios. Hash technique has shown its superiority for speeding up the online recommendation by bit operations on Hamming distance computations. However, existing hashing-based recommendations suffer from low accuracy, especially with sparse settings, due to the limited representation capability of each bit and neglected inherent relations among users and items. To this end, this paper lodges a Collaborative Group-Aware Hashing (CGAH) method for both collaborative filtering (namely CGAH-CF) and content-aware recommendations (namely CGAH) by integrating the inherent group information to alleviate the sparse issue. Firstly, we extract inherent group affinities of users and items by classifying their latent vectors into different groups. Then, the preference is formulated as the inner product of the group affinity and the similarity of hash codes. By learning hash codes with the inherent group information, CGAH obtains more effective hash codes than other discrete methods with sparse interactive data. Extensive experiments on three public datasets show the superior performance of our proposed CGAH and CGAH-CF over the state-of-the-art discrete collaborative filtering methods and discrete content-aware recommendations under different sparse settings.
Uncover and Unlearn Nuisances: Agnostic Fully Test-Time Adaptation
Nov 16, 2025Fully Test-Time Adaptation (FTTA) addresses domain shifts without access to source data and training protocols of the pre-trained models. Traditional strategies that align source and target feature distributions are infeasible in FTTA due to the absence of training data and unpredictable target domains. In this work, we exploit a dual perspective on FTTA, and propose Agnostic FTTA (AFTTA) as a novel formulation that enables the usage of off-the-shelf domain transformations during test-time to enable direct generalization to unforeseeable target data. To address this, we develop an uncover-and-unlearn approach. First, we uncover potential unwanted shifts between source and target domains by simulating them through predefined mappings and consider them as nuisances. Then, during test-time prediction, the model is enforced to unlearn these nuisances by regularizing the consequent shifts in latent representations and label predictions. Specifically, a mutual information-based criterion is devised and applied to guide nuisances unlearning in the feature space and encourage confident and consistent prediction in label space. Our proposed approach explicitly addresses agnostic domain shifts, enabling superior model generalization under FTTA constraints. Extensive experiments on various tasks, involving corruption and style shifts, demonstrate that our method consistently outperforms existing approaches.
* 26 pages, 4 figures
FOCUS: Frequency-Optimized Conditioning of DiffUSion Models for mitigating catastrophic forgetting during Test-Time Adaptation
Aug 20, 2025Test-time adaptation enables models to adapt to evolving domains. However, balancing the tradeoff between preserving knowledge and adapting to domain shifts remains challenging for model adaptation methods, since adapting to domain shifts can induce forgetting of task-relevant knowledge. To address this problem, we propose FOCUS, a novel frequency-based conditioning approach within a diffusion-driven input-adaptation framework. Utilising learned, spatially adaptive frequency priors, our approach conditions the reverse steps during diffusion-driven denoising to preserve task-relevant semantic information for dense prediction. FOCUS leverages a trained, lightweight, Y-shaped Frequency Prediction Network (Y-FPN) that disentangles high and low frequency information from noisy images. This minimizes the computational costs involved in implementing our approach in a diffusion-driven framework. We train Y-FPN with FrequencyMix, a novel data augmentation method that perturbs the images across diverse frequency bands, which improves the robustness of our approach to diverse corruptions. We demonstrate the effectiveness of FOCUS for semantic segmentation and monocular depth estimation across 15 corruption types and three datasets, achieving state-of-the-art averaged performance. In addition to improving standalone performance, FOCUS complements existing model adaptation methods since we can derive pseudo labels from FOCUS-denoised images for additional supervision. Even under limited, intermittent supervision with the pseudo labels derived from the FOCUS denoised images, we show that FOCUS mitigates catastrophic forgetting for recent model adaptation methods.
Decentralized Optimization on Compact Submanifolds by Quantized Riemannian Gradient Tracking
Jun 09, 2025This paper considers the problem of decentralized optimization on compact submanifolds, where a finite sum of smooth (possibly non-convex) local functions is minimized by $n$ agents forming an undirected and connected graph. However, the efficiency of distributed optimization is often hindered by communication bottlenecks. To mitigate this, we propose the Quantized Riemannian Gradient Tracking (Q-RGT) algorithm, where agents update their local variables using quantized gradients. The introduction of quantization noise allows our algorithm to bypass the constraints of the accurate Riemannian projection operator (such as retraction), further improving iterative efficiency. To the best of our knowledge, this is the first algorithm to achieve an $\mathcal{O}(1/K)$ convergence rate in the presence of quantization, matching the convergence rate of methods without quantization. Additionally, we explicitly derive lower bounds on decentralized consensus associated with a function of quantization levels. Numerical experiments demonstrate that Q-RGT performs comparably to non-quantized methods while reducing communication bottlenecks and computational overhead.