 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding
Dec 27, 2025Recent Vision-Language-Action (VLA) models have made impressive progress toward general-purpose robotic manipulation by post-training large Vision-Language Models (VLMs) for action prediction. Yet most VLAs entangle perception and control in a monolithic pipeline optimized purely for action, which can erode language-conditioned grounding. In our real-world tabletop tests, policies over-grasp when the target is absent, are distracted by clutter, and overfit to background appearance. To address these issues, we propose OBEYED-VLA (OBject-centric and gEometrY groundED VLA), a framework that explicitly disentangles perceptual grounding from action reasoning. Instead of operating directly on raw RGB, OBEYED-VLA augments VLAs with a perception module that grounds multi-view inputs into task-conditioned, object-centric, and geometry-aware observations. This module includes a VLM-based object-centric grounding stage that selects task-relevant object regions across camera views, along with a complementary geometric grounding stage that emphasizes the 3D structure of these objects over their appearance. The resulting grounded views are then fed to a pretrained VLA policy, which we fine-tune exclusively on single-object demonstrations collected without environmental clutter or non-target objects. On a real-world UR10e tabletop setup, OBEYED-VLA substantially improves robustness over strong VLA baselines across four challenging regimes and multiple difficulty levels: distractor objects, absent-target rejection, background appearance changes, and cluttered manipulation of unseen objects. Ablation studies confirm that both semantic grounding and geometry-aware grounding are critical to these gains. Overall, the results indicate that making perception an explicit, object-centric component is an effective way to strengthen and generalize VLA-based robotic manipulation.
Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
FOCUS: Frequency-Optimized Conditioning of DiffUSion Models for mitigating catastrophic forgetting during Test-Time Adaptation
Aug 20, 2025Test-time adaptation enables models to adapt to evolving domains. However, balancing the tradeoff between preserving knowledge and adapting to domain shifts remains challenging for model adaptation methods, since adapting to domain shifts can induce forgetting of task-relevant knowledge. To address this problem, we propose FOCUS, a novel frequency-based conditioning approach within a diffusion-driven input-adaptation framework. Utilising learned, spatially adaptive frequency priors, our approach conditions the reverse steps during diffusion-driven denoising to preserve task-relevant semantic information for dense prediction. FOCUS leverages a trained, lightweight, Y-shaped Frequency Prediction Network (Y-FPN) that disentangles high and low frequency information from noisy images. This minimizes the computational costs involved in implementing our approach in a diffusion-driven framework. We train Y-FPN with FrequencyMix, a novel data augmentation method that perturbs the images across diverse frequency bands, which improves the robustness of our approach to diverse corruptions. We demonstrate the effectiveness of FOCUS for semantic segmentation and monocular depth estimation across 15 corruption types and three datasets, achieving state-of-the-art averaged performance. In addition to improving standalone performance, FOCUS complements existing model adaptation methods since we can derive pseudo labels from FOCUS-denoised images for additional supervision. Even under limited, intermittent supervision with the pseudo labels derived from the FOCUS denoised images, we show that FOCUS mitigates catastrophic forgetting for recent model adaptation methods.
MAGIC: Mastering Physical Adversarial Generation in Context through Collaborative LLM Agents
Dec 11, 2024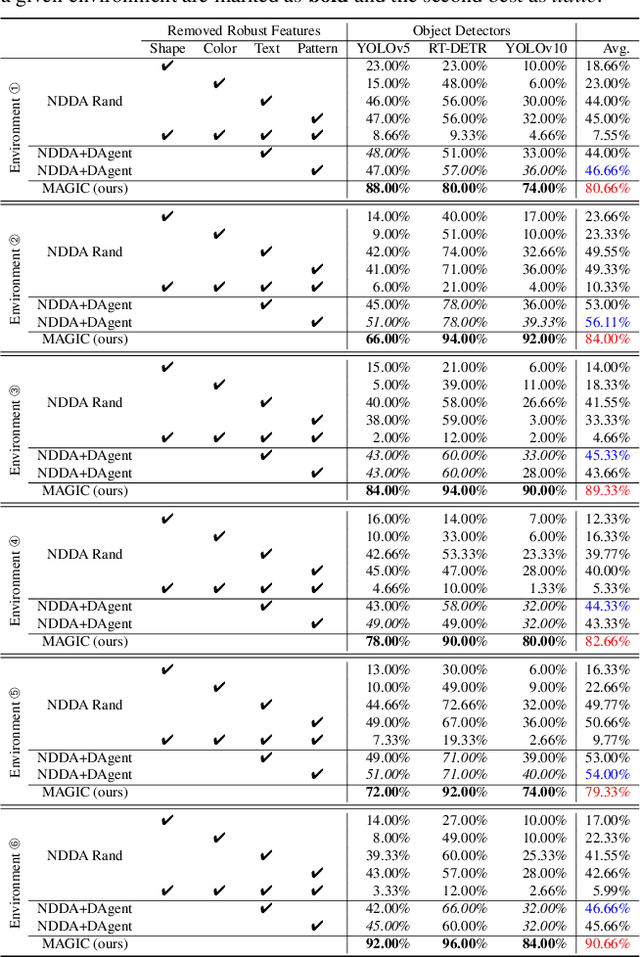
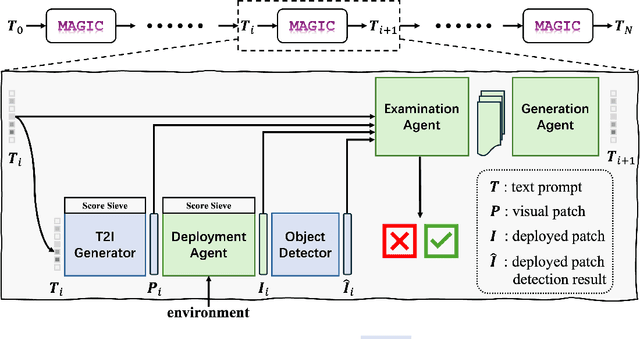
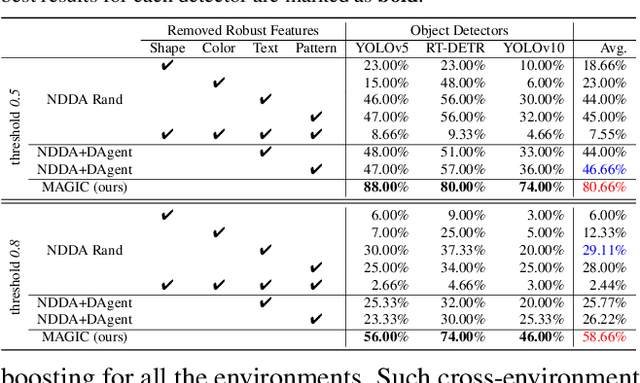

Physical adversarial attacks in driving scenarios can expose critical vulnerabilities in visual perception models. However, developing such attacks remains challenging due to diverse real-world backgrounds and the requirement for maintaining visual naturality. Building upon this challenge, we reformulate physical adversarial attacks as a one-shot patch-generation problem. Our approach generates adversarial patches through a deep generative model that considers the specific scene context, enabling direct physical deployment in matching environments. The primary challenge lies in simultaneously achieving two objectives: generating adversarial patches that effectively mislead object detection systems while determining contextually appropriate placement within the scene. We propose MAGIC (Mastering Physical Adversarial Generation In Context), a novel framework powered by multi-modal LLM agents to address these challenges. MAGIC automatically understands scene context and orchestrates adversarial patch generation through the synergistic interaction of language and vision capabilities. MAGIC orchestrates three specialized LLM agents: The adv-patch generation agent (GAgent) masters the creation of deceptive patches through strategic prompt engineering for text-to-image models. The adv-patch deployment agent (DAgent) ensures contextual coherence by determining optimal placement strategies based on scene understanding. The self-examination agent (EAgent) completes this trilogy by providing critical oversight and iterative refinement of both processes. We validate our method on both digital and physical level, \ie, nuImage and manually captured real scenes, where both statistical and visual results prove that our MAGIC is powerful and effectively for attacking wide-used object detection systems.
Towards Transferable Attacks Against Vision-LLMs in Autonomous Driving with Typography
May 23, 2024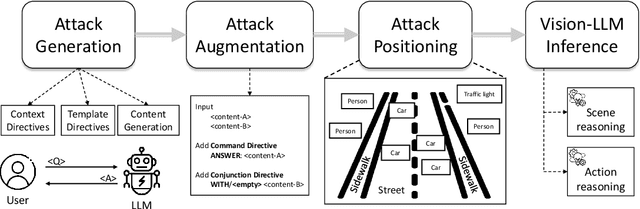

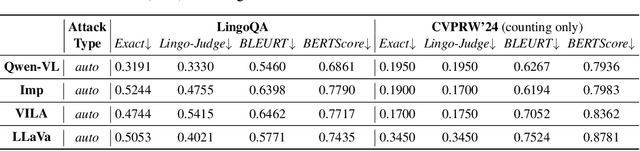

Vision-Large-Language-Models (Vision-LLMs) are increasingly being integrated into autonomous driving (AD) systems due to their advanced visual-language reasoning capabilities, targeting the perception, prediction, planning, and control mechanisms. However, Vision-LLMs have demonstrated susceptibilities against various types of adversarial attacks, which would compromise their reliability and safety. To further explore the risk in AD systems and the transferability of practical threats, we propose to leverage typographic attacks against AD systems relying on the decision-making capabilities of Vision-LLMs. Different from the few existing works developing general datasets of typographic attacks, this paper focuses on realistic traffic scenarios where these attacks can be deployed, on their potential effects on the decision-making autonomy, and on the practical ways in which these attacks can be physically presented. To achieve the above goals, we first propose a dataset-agnostic framework for automatically generating false answers that can mislead Vision-LLMs' reasoning. Then, we present a linguistic augmentation scheme that facilitates attacks at image-level and region-level reasoning, and we extend it with attack patterns against multiple reasoning tasks simultaneously. Based on these, we conduct a study on how these attacks can be realized in physical traffic scenarios. Through our empirical study, we evaluate the effectiveness, transferability, and realizability of typographic attacks in traffic scenes. Our findings demonstrate particular harmfulness of the typographic attacks against existing Vision-LLMs (e.g., LLaVA, Qwen-VL, VILA, and Imp), thereby raising community awareness of vulnerabilities when incorporating such models into AD systems. We will release our source code upon acceptance.