 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpper Entropy for 2-Monotone Lower Probabilities
Mar 23, 2026Uncertainty quantification is a key aspect in many tasks such as model selection/regularization, or quantifying prediction uncertainties to perform active learning or OOD detection. Within credal approaches that consider modeling uncertainty as probability sets, upper entropy plays a central role as an uncertainty measure. This paper is devoted to the computational aspect of upper entropies, providing an exhaustive algorithmic and complexity analysis of the problem. In particular, we show that the problem has a strongly polynomial solution, and propose many significant improvements over past algorithms proposed for 2-monotone lower probabilities and their specific cases.
Your Vision-Language-Action Model Already Has Attention Heads For Path Deviation Detection
Mar 14, 2026Vision-Language-Action (VLA) models have demonstrated strong potential for predicting semantic actions in navigation tasks, demonstrating the ability to reason over complex linguistic instructions and visual contexts. However, they are fundamentally hindered by visual-reasoning hallucinations that lead to trajectory deviations. Addressing this issue has conventionally required training external critic modules or relying on complex uncertainty heuristics. In this work, we discover that monitoring a few attention heads within a frozen VLA model can accurately detect path deviations without incurring additional computational overhead. We refer to these heads, which inherently capture the spatiotemporal causality between historical visual sequences and linguistic instructions, as Navigation Heads. Using these heads, we propose an intuitive, training-free anomaly-detection framework that monitors their signals to detect hallucinations in real time. Surprisingly, among over a thousand attention heads, a combination of just three is sufficient to achieve a 44.6 % deviation detection rate with a low false-positive rate of 11.7 %. Furthermore, upon detecting a deviation, we bypass the heavy VLA model and trigger a lightweight Reinforcement Learning (RL) policy to safely execute a shortest-path rollback. By integrating this entire detection-to-recovery pipeline onto a physical robot, we demonstrate its practical robustness. All source code will be publicly available.
DePT3R: Joint Dense Point Tracking and 3D Reconstruction of Dynamic Scenes in a Single Forward Pass
Dec 15, 2025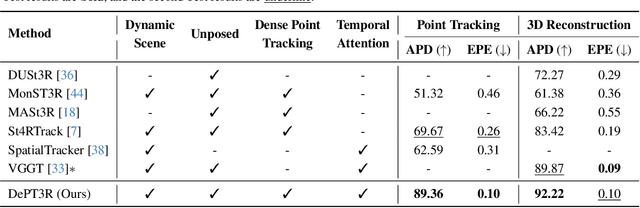
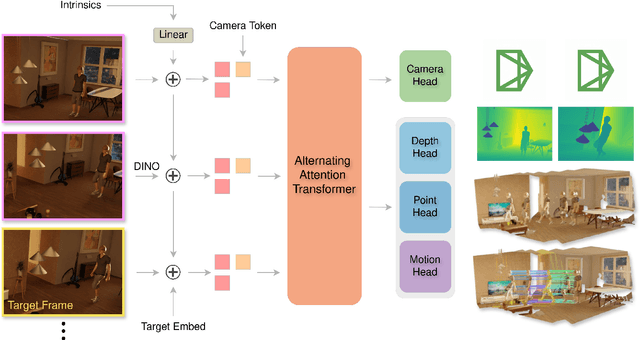
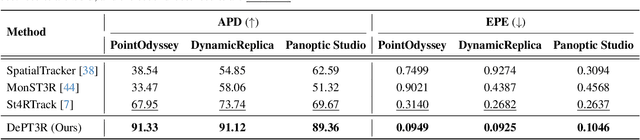
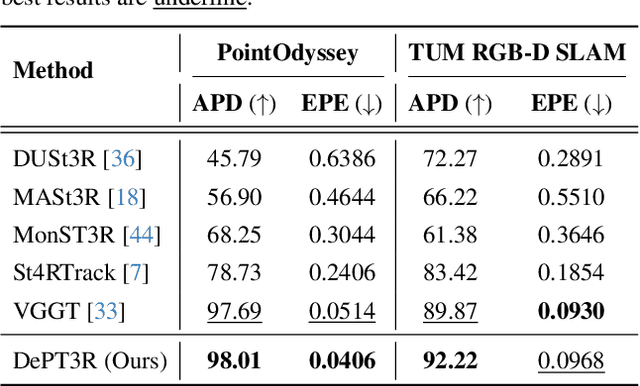
Current methods for dense 3D point tracking in dynamic scenes typically rely on pairwise processing, require known camera poses, or assume a temporal ordering to input frames, constraining their flexibility and applicability. Additionally, recent advances have successfully enabled efficient 3D reconstruction from large-scale, unposed image collections, underscoring opportunities for unified approaches to dynamic scene understanding. Motivated by this, we propose DePT3R, a novel framework that simultaneously performs dense point tracking and 3D reconstruction of dynamic scenes from multiple images in a single forward pass. This multi-task learning is achieved by extracting deep spatio-temporal features with a powerful backbone and regressing pixel-wise maps with dense prediction heads. Crucially, DePT3R operates without requiring camera poses, substantially enhancing its adaptability and efficiency-especially important in dynamic environments with rapid changes. We validate DePT3R on several challenging benchmarks involving dynamic scenes, demonstrating strong performance and significant improvements in memory efficiency over existing state-of-the-art methods. Data and codes are available via the open repository: https://github.com/StructuresComp/DePT3R
HiddenObject: Modality-Agnostic Fusion for Multimodal Hidden Object Detection
Aug 28, 2025

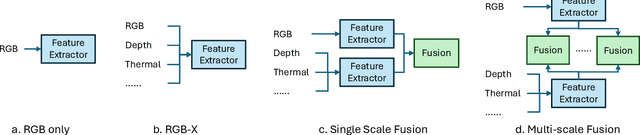
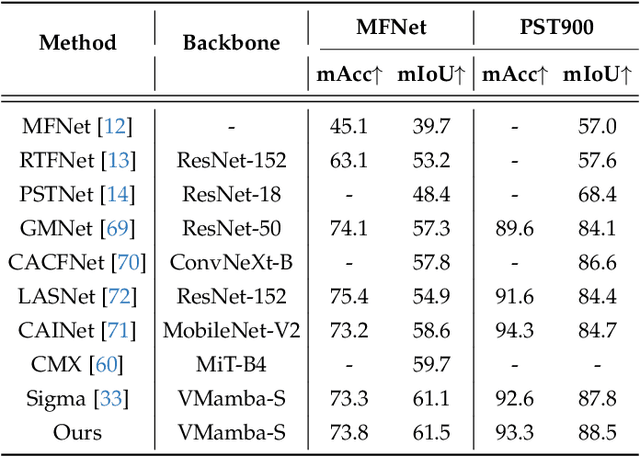
Detecting hidden or partially concealed objects remains a fundamental challenge in multimodal environments, where factors like occlusion, camouflage, and lighting variations significantly hinder performance. Traditional RGB-based detection methods often fail under such adverse conditions, motivating the need for more robust, modality-agnostic approaches. In this work, we present HiddenObject, a fusion framework that integrates RGB, thermal, and depth data using a Mamba-based fusion mechanism. Our method captures complementary signals across modalities, enabling enhanced detection of obscured or camouflaged targets. Specifically, the proposed approach identifies modality-specific features and fuses them in a unified representation that generalizes well across challenging scenarios. We validate HiddenObject across multiple benchmark datasets, demonstrating state-of-the-art or competitive performance compared to existing methods. These results highlight the efficacy of our fusion design and expose key limitations in current unimodal and na\"ive fusion strategies. More broadly, our findings suggest that Mamba-based fusion architectures can significantly advance the field of multimodal object detection, especially under visually degraded or complex conditions.
AgriChrono: A Multi-modal Dataset Capturing Crop Growth and Lighting Variability with a Field Robot
Aug 26, 2025Existing datasets for precision agriculture have primarily been collected in static or controlled environments such as indoor labs or greenhouses, often with limited sensor diversity and restricted temporal span. These conditions fail to reflect the dynamic nature of real farmland, including illumination changes, crop growth variation, and natural disturbances. As a result, models trained on such data often lack robustness and generalization when applied to real-world field scenarios. In this paper, we present AgriChrono, a novel robotic data collection platform and multi-modal dataset designed to capture the dynamic conditions of real-world agricultural environments. Our platform integrates multiple sensors and enables remote, time-synchronized acquisition of RGB, Depth, LiDAR, and IMU data, supporting efficient and repeatable long-term data collection across varying illumination and crop growth stages. We benchmark a range of state-of-the-art 3D reconstruction models on the AgriChrono dataset, highlighting the difficulty of reconstruction in real-world field environments and demonstrating its value as a research asset for advancing model generalization under dynamic conditions. The code and dataset are publicly available at: https://github.com/StructuresComp/agri-chrono
Reconstruction Using the Invisible: Intuition from NIR and Metadata for Enhanced 3D Gaussian Splatting
Aug 20, 2025
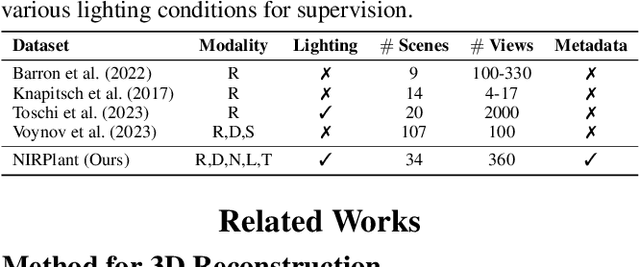


While 3D Gaussian Splatting (3DGS) has rapidly advanced, its application in agriculture remains underexplored. Agricultural scenes present unique challenges for 3D reconstruction methods, particularly due to uneven illumination, occlusions, and a limited field of view. To address these limitations, we introduce \textbf{NIRPlant}, a novel multimodal dataset encompassing Near-Infrared (NIR) imagery, RGB imagery, textual metadata, Depth, and LiDAR data collected under varied indoor and outdoor lighting conditions. By integrating NIR data, our approach enhances robustness and provides crucial botanical insights that extend beyond the visible spectrum. Additionally, we leverage text-based metadata derived from vegetation indices, such as NDVI, NDWI, and the chlorophyll index, which significantly enriches the contextual understanding of complex agricultural environments. To fully exploit these modalities, we propose \textbf{NIRSplat}, an effective multimodal Gaussian splatting architecture employing a cross-attention mechanism combined with 3D point-based positional encoding, providing robust geometric priors. Comprehensive experiments demonstrate that \textbf{NIRSplat} outperforms existing landmark methods, including 3DGS, CoR-GS, and InstantSplat, highlighting its effectiveness in challenging agricultural scenarios. The code and dataset are publicly available at: https://github.com/StructuresComp/3D-Reconstruction-NIR
Towards Transferable Attacks Against Vision-LLMs in Autonomous Driving with Typography
May 23, 2024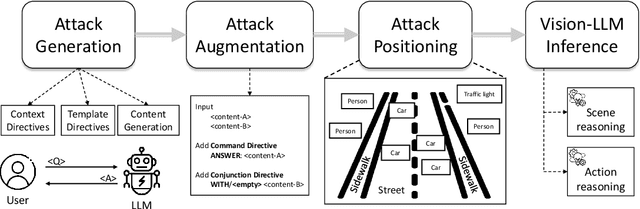

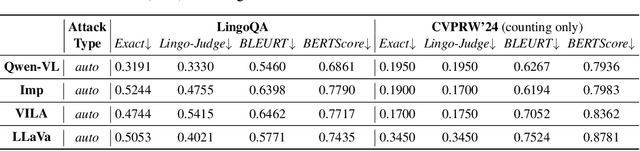

Vision-Large-Language-Models (Vision-LLMs) are increasingly being integrated into autonomous driving (AD) systems due to their advanced visual-language reasoning capabilities, targeting the perception, prediction, planning, and control mechanisms. However, Vision-LLMs have demonstrated susceptibilities against various types of adversarial attacks, which would compromise their reliability and safety. To further explore the risk in AD systems and the transferability of practical threats, we propose to leverage typographic attacks against AD systems relying on the decision-making capabilities of Vision-LLMs. Different from the few existing works developing general datasets of typographic attacks, this paper focuses on realistic traffic scenarios where these attacks can be deployed, on their potential effects on the decision-making autonomy, and on the practical ways in which these attacks can be physically presented. To achieve the above goals, we first propose a dataset-agnostic framework for automatically generating false answers that can mislead Vision-LLMs' reasoning. Then, we present a linguistic augmentation scheme that facilitates attacks at image-level and region-level reasoning, and we extend it with attack patterns against multiple reasoning tasks simultaneously. Based on these, we conduct a study on how these attacks can be realized in physical traffic scenarios. Through our empirical study, we evaluate the effectiveness, transferability, and realizability of typographic attacks in traffic scenes. Our findings demonstrate particular harmfulness of the typographic attacks against existing Vision-LLMs (e.g., LLaVA, Qwen-VL, VILA, and Imp), thereby raising community awareness of vulnerabilities when incorporating such models into AD systems. We will release our source code upon acceptance.
StyleCity: Large-Scale 3D Urban Scenes Stylization with Vision-and-Text Reference via Progressive Optimization
Apr 16, 2024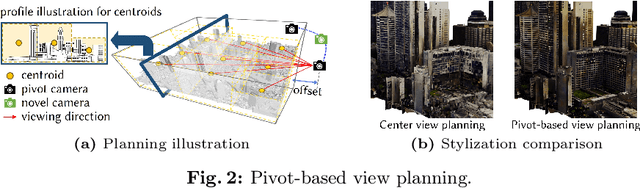



Creating large-scale virtual urban scenes with variant styles is inherently challenging. To facilitate prototypes of virtual production and bypass the need for complex materials and lighting setups, we introduce the first vision-and-text-driven texture stylization system for large-scale urban scenes, StyleCity. Taking an image and text as references, StyleCity stylizes a 3D textured mesh of a large-scale urban scene in a semantics-aware fashion and generates a harmonic omnidirectional sky background. To achieve that, we propose to stylize a neural texture field by transferring 2D vision-and-text priors to 3D globally and locally. During 3D stylization, we progressively scale the planned training views of the input 3D scene at different levels in order to preserve high-quality scene content. We then optimize the scene style globally by adapting the scale of the style image with the scale of the training views. Moreover, we enhance local semantics consistency by the semantics-aware style loss which is crucial for photo-realistic stylization. Besides texture stylization, we further adopt a generative diffusion model to synthesize a style-consistent omnidirectional sky image, which offers a more immersive atmosphere and assists the semantic stylization process. The stylized neural texture field can be baked into an arbitrary-resolution texture, enabling seamless integration into conventional rendering pipelines and significantly easing the virtual production prototyping process. Extensive experiments demonstrate our stylized scenes' superiority in qualitative and quantitative performance and user preferences.
Improving Referring Image Segmentation using Vision-Aware Text Features
Apr 12, 2024


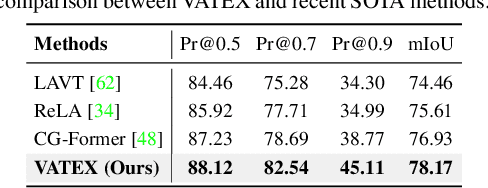
Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. This over-reliance on visual features can lead to suboptimal results, especially in complex scenarios where text prompts are ambiguous or context-dependent. To overcome these challenges, we present a novel framework VATEX to improve referring image segmentation by enhancing object and context understanding with Vision-Aware Text Feature. Our method involves using CLIP to derive a CLIP Prior that integrates an object-centric visual heatmap with text description, which can be used as the initial query in DETR-based architecture for the segmentation task. Furthermore, by observing that there are multiple ways to describe an instance in an image, we enforce feature similarity between text variations referring to the same visual input by two components: a novel Contextual Multimodal Decoder that turns text embeddings into vision-aware text features, and a Meaning Consistency Constraint to ensure further the coherent and consistent interpretation of language expressions with the context understanding obtained from the image. Our method achieves a significant performance improvement on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref. Code is available at: https://nero1342.github.io/VATEX\_RIS.
Exploring Boundary of GPT-4V on Marine Analysis: A Preliminary Case Study
Jan 04, 2024Large language models (LLMs) have demonstrated a powerful ability to answer various queries as a general-purpose assistant. The continuous multi-modal large language models (MLLM) empower LLMs with the ability to perceive visual signals. The launch of GPT-4 (Generative Pre-trained Transformers) has generated significant interest in the research communities. GPT-4V(ison) has demonstrated significant power in both academia and industry fields, as a focal point in a new artificial intelligence generation. Though significant success was achieved by GPT-4V, exploring MLLMs in domain-specific analysis (e.g., marine analysis) that required domain-specific knowledge and expertise has gained less attention. In this study, we carry out the preliminary and comprehensive case study of utilizing GPT-4V for marine analysis. This report conducts a systematic evaluation of existing GPT-4V, assessing the performance of GPT-4V on marine research and also setting a new standard for future developments in MLLMs. The experimental results of GPT-4V show that the responses generated by GPT-4V are still far away from satisfying the domain-specific requirements of the marine professions. All images and prompts used in this study will be available at https://github.com/hkust-vgd/Marine_GPT-4V_Eval