 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Cache Enhancement for Test-Time Adaptation of Vision-Language Models
Aug 11, 2025Vision-language models (VLMs) exhibit remarkable zero-shot generalization but suffer performance degradation under distribution shifts in downstream tasks, particularly in the absence of labeled data. Test-Time Adaptation (TTA) addresses this challenge by enabling online optimization of VLMs during inference, eliminating the need for annotated data. Cache-based TTA methods exploit historical knowledge by maintaining a dynamic memory cache of low-entropy or high-confidence samples, promoting efficient adaptation to out-of-distribution data. Nevertheless, these methods face two critical challenges: (1) unreliable confidence metrics under significant distribution shifts, resulting in error accumulation within the cache and degraded adaptation performance; and (2) rigid decision boundaries that fail to accommodate substantial distributional variations, leading to suboptimal predictions. To overcome these limitations, we introduce the Adaptive Cache Enhancement (ACE) framework, which constructs a robust cache by selectively storing high-confidence or low-entropy image embeddings per class, guided by dynamic, class-specific thresholds initialized from zero-shot statistics and iteratively refined using an exponential moving average and exploration-augmented updates. This approach enables adaptive, class-wise decision boundaries, ensuring robust and accurate predictions across diverse visual distributions. Extensive experiments on 15 diverse benchmark datasets demonstrate that ACE achieves state-of-the-art performance, delivering superior robustness and generalization compared to existing TTA methods in challenging out-of-distribution scenarios.
MSC: A Marine Wildlife Video Dataset with Grounded Segmentation and Clip-Level Captioning
Aug 06, 2025Marine videos present significant challenges for video understanding due to the dynamics of marine objects and the surrounding environment, camera motion, and the complexity of underwater scenes. Existing video captioning datasets, typically focused on generic or human-centric domains, often fail to generalize to the complexities of the marine environment and gain insights about marine life. To address these limitations, we propose a two-stage marine object-oriented video captioning pipeline. We introduce a comprehensive video understanding benchmark that leverages the triplets of video, text, and segmentation masks to facilitate visual grounding and captioning, leading to improved marine video understanding and analysis, and marine video generation. Additionally, we highlight the effectiveness of video splitting in order to detect salient object transitions in scene changes, which significantly enrich the semantics of captioning content. Our dataset and code have been released at https://msc.hkustvgd.com.
A model-agnostic active learning approach for animal detection from camera traps
Jul 09, 2025Smart data selection is becoming increasingly important in data-driven machine learning. Active learning offers a promising solution by allowing machine learning models to be effectively trained with optimal data including the most informative samples from large datasets. Wildlife data captured by camera traps are excessive in volume, requiring tremendous effort in data labelling and animal detection models training. Therefore, applying active learning to optimise the amount of labelled data would be a great aid in enabling automated wildlife monitoring and conservation. However, existing active learning techniques require that a machine learning model (i.e., an object detector) be fully accessible, limiting the applicability of the techniques. In this paper, we propose a model-agnostic active learning approach for detection of animals captured by camera traps. Our approach integrates uncertainty and diversity quantities of samples at both the object-based and image-based levels into the active learning sample selection process. We validate our approach in a benchmark animal dataset. Experimental results demonstrate that, using only 30% of the training data selected by our approach, a state-of-the-art animal detector can achieve a performance of equal or greater than that with the use of the complete training dataset.
AUTV: Creating Underwater Video Datasets with Pixel-wise Annotations
Mar 17, 2025Underwater video analysis, hampered by the dynamic marine environment and camera motion, remains a challenging task in computer vision. Existing training-free video generation techniques, learning motion dynamics on the frame-by-frame basis, often produce poor results with noticeable motion interruptions and misaligments. To address these issues, we propose AUTV, a framework for synthesizing marine video data with pixel-wise annotations. We demonstrate the effectiveness of this framework by constructing two video datasets, namely UTV, a real-world dataset comprising 2,000 video-text pairs, and SUTV, a synthetic video dataset including 10,000 videos with segmentation masks for marine objects. UTV provides diverse underwater videos with comprehensive annotations including appearance, texture, camera intrinsics, lighting, and animal behavior. SUTV can be used to improve underwater downstream tasks, which are demonstrated in video inpainting and video object segmentation.
Color Alignment in Diffusion
Mar 09, 2025Diffusion models have shown great promise in synthesizing visually appealing images. However, it remains challenging to condition the synthesis at a fine-grained level, for instance, synthesizing image pixels following some generic color pattern. Existing image synthesis methods often produce contents that fall outside the desired pixel conditions. To address this, we introduce a novel color alignment algorithm that confines the generative process in diffusion models within a given color pattern. Specifically, we project diffusion terms, either imagery samples or latent representations, into a conditional color space to align with the input color distribution. This strategy simplifies the prediction in diffusion models within a color manifold while still allowing plausible structures in generated contents, thus enabling the generation of diverse contents that comply with the target color pattern. Experimental results demonstrate our state-of-the-art performance in conditioning and controlling of color pixels, while maintaining on-par generation quality and diversity in comparison with regular diffusion models.
Self-supervised Video Object Segmentation with Distillation Learning of Deformable Attention
Jan 25, 2024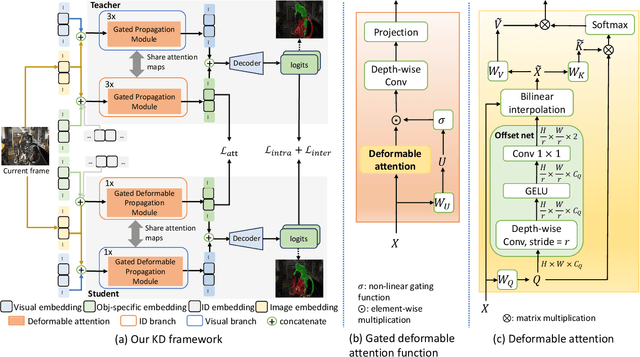



Video object segmentation is a fundamental research problem in computer vision. Recent techniques have often applied attention mechanism to object representation learning from video sequences. However, due to temporal changes in the video data, attention maps may not well align with the objects of interest across video frames, causing accumulated errors in long-term video processing. In addition, existing techniques have utilised complex architectures, requiring highly computational complexity and hence limiting the ability to integrate video object segmentation into low-powered devices. To address these issues, we propose a new method for self-supervised video object segmentation based on distillation learning of deformable attention. Specifically, we devise a lightweight architecture for video object segmentation that is effectively adapted to temporal changes. This is enabled by deformable attention mechanism, where the keys and values capturing the memory of a video sequence in the attention module have flexible locations updated across frames. The learnt object representations are thus adaptive to both the spatial and temporal dimensions. We train the proposed architecture in a self-supervised fashion through a new knowledge distillation paradigm where deformable attention maps are integrated into the distillation loss. We qualitatively and quantitatively evaluate our method and compare it with existing methods on benchmark datasets including DAVIS 2016/2017 and YouTube-VOS 2018/2019. Experimental results verify the superiority of our method via its achieved state-of-the-art performance and optimal memory usage.
Leveraging Open-Vocabulary Diffusion to Camouflaged Instance Segmentation
Dec 29, 2023Text-to-image diffusion techniques have shown exceptional capability of producing high-quality images from text descriptions. This indicates that there exists a strong correlation between the visual and textual domains. In addition, text-image discriminative models such as CLIP excel in image labelling from text prompts, thanks to the rich and diverse information available from open concepts. In this paper, we leverage these technical advances to solve a challenging problem in computer vision: camouflaged instance segmentation. Specifically, we propose a method built upon a state-of-the-art diffusion model, empowered by open-vocabulary to learn multi-scale textual-visual features for camouflaged object representations. Such cross-domain representations are desirable in segmenting camouflaged objects where visual cues are subtle to distinguish the objects from the background, especially in segmenting novel objects which are not seen in training. We also develop technically supportive components to effectively fuse cross-domain features and engage relevant features towards respective foreground objects. We validate our method and compare it with existing ones on several benchmark datasets of camouflaged instance segmentation and generic open-vocabulary instance segmentation. Experimental results confirm the advances of our method over existing ones. We will publish our code and pre-trained models to support future research.
An empirical study of automatic wildlife detection using drone thermal imaging and object detection
Oct 17, 2023Artificial intelligence has the potential to make valuable contributions to wildlife management through cost-effective methods for the collection and interpretation of wildlife data. Recent advances in remotely piloted aircraft systems (RPAS or ``drones'') and thermal imaging technology have created new approaches to collect wildlife data. These emerging technologies could provide promising alternatives to standard labourious field techniques as well as cover much larger areas. In this study, we conduct a comprehensive review and empirical study of drone-based wildlife detection. Specifically, we collect a realistic dataset of drone-derived wildlife thermal detections. Wildlife detections, including arboreal (for instance, koalas, phascolarctos cinereus) and ground dwelling species in our collected data are annotated via bounding boxes by experts. We then benchmark state-of-the-art object detection algorithms on our collected dataset. We use these experimental results to identify issues and discuss future directions in automatic animal monitoring using drones.
MVC: A Multi-Task Vision Transformer Network for COVID-19 Diagnosis from Chest X-ray Images
Sep 30, 2023Medical image analysis using computer-based algorithms has attracted considerable attention from the research community and achieved tremendous progress in the last decade. With recent advances in computing resources and availability of large-scale medical image datasets, many deep learning models have been developed for disease diagnosis from medical images. However, existing techniques focus on sub-tasks, e.g., disease classification and identification, individually, while there is a lack of a unified framework enabling multi-task diagnosis. Inspired by the capability of Vision Transformers in both local and global representation learning, we propose in this paper a new method, namely Multi-task Vision Transformer (MVC) for simultaneously classifying chest X-ray images and identifying affected regions from the input data. Our method is built upon the Vision Transformer but extends its learning capability in a multi-task setting. We evaluated our proposed method and compared it with existing baselines on a benchmark dataset of COVID-19 chest X-ray images. Experimental results verified the superiority of the proposed method over the baselines on both the image classification and affected region identification tasks.
Language-driven Object Fusion into Neural Radiance Fields with Pose-Conditioned Dataset Updates
Sep 25, 2023



Neural radiance field is an emerging rendering method that generates high-quality multi-view consistent images from a neural scene representation and volume rendering. Although neural radiance field-based techniques are robust for scene reconstruction, their ability to add or remove objects remains limited. This paper proposes a new language-driven approach for object manipulation with neural radiance fields through dataset updates. Specifically, to insert a new foreground object represented by a set of multi-view images into a background radiance field, we use a text-to-image diffusion model to learn and generate combined images that fuse the object of interest into the given background across views. These combined images are then used for refining the background radiance field so that we can render view-consistent images containing both the object and the background. To ensure view consistency, we propose a dataset updates strategy that prioritizes radiance field training with camera views close to the already-trained views prior to propagating the training to remaining views. We show that under the same dataset updates strategy, we can easily adapt our method for object insertion using data from text-to-3D models as well as object removal. Experimental results show that our method generates photorealistic images of the edited scenes, and outperforms state-of-the-art methods in 3D reconstruction and neural radiance field blending.