 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Manifolds: Do the manifolds learned by Generative Adversarial Networks converge to the real data manifold
Mar 08, 2024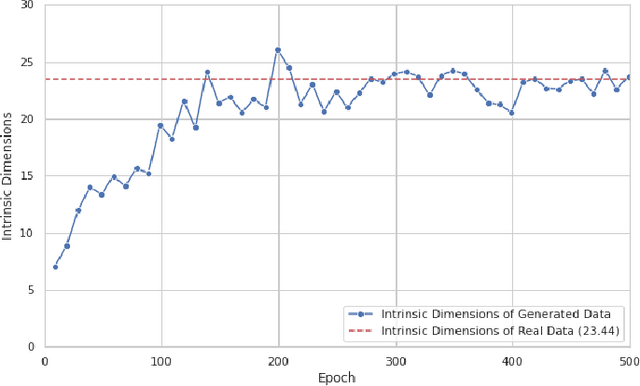
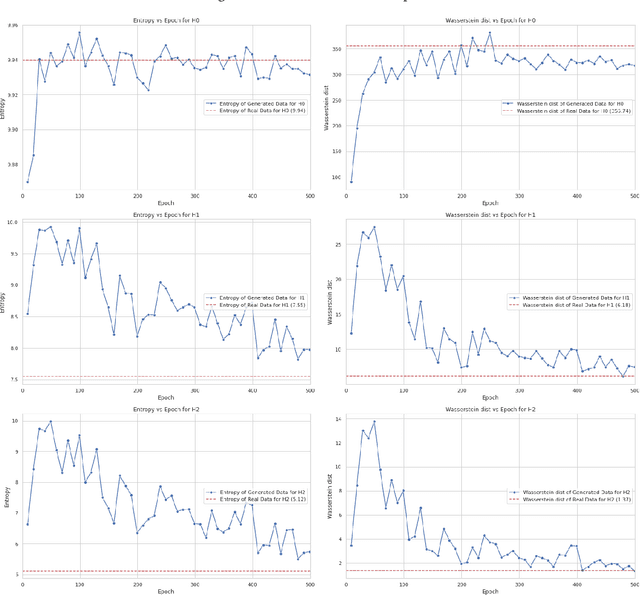
This paper presents our experiments to quantify the manifolds learned by ML models (in our experiment, we use a GAN model) as they train. We compare the manifolds learned at each epoch to the real manifolds representing the real data. To quantify a manifold, we study the intrinsic dimensions and topological features of the manifold learned by the ML model, how these metrics change as we continue to train the model, and whether these metrics convergence over the course of training to the metrics of the real data manifold.
LLMs for Test Input Generation for Semantic Caches
Jan 16, 2024Large language models (LLMs) enable state-of-the-art semantic capabilities to be added to software systems such as semantic search of unstructured documents and text generation. However, these models are computationally expensive. At scale, the cost of serving thousands of users increases massively affecting also user experience. To address this problem, semantic caches are used to check for answers to similar queries (that may have been phrased differently) without hitting the LLM service. Due to the nature of these semantic cache techniques that rely on query embeddings, there is a high chance of errors impacting user confidence in the system. Adopting semantic cache techniques usually requires testing the effectiveness of a semantic cache (accurate cache hits and misses) which requires a labelled test set of similar queries and responses which is often unavailable. In this paper, we present VaryGen, an approach for using LLMs for test input generation that produces similar questions from unstructured text documents. Our novel approach uses the reasoning capabilities of LLMs to 1) adapt queries to the domain, 2) synthesise subtle variations to queries, and 3) evaluate the synthesised test dataset. We evaluated our approach in the domain of a student question and answer system by qualitatively analysing 100 generated queries and result pairs, and conducting an empirical case study with an open source semantic cache. Our results show that query pairs satisfy human expectations of similarity and our generated data demonstrates failure cases of a semantic cache. Additionally, we also evaluate our approach on Qasper dataset. This work is an important first step into test input generation for semantic applications and presents considerations for practitioners when calibrating a semantic cache.
ML-On-Rails: Safeguarding Machine Learning Models in Software Systems A Case Study
Jan 12, 2024



Machine learning (ML), especially with the emergence of large language models (LLMs), has significantly transformed various industries. However, the transition from ML model prototyping to production use within software systems presents several challenges. These challenges primarily revolve around ensuring safety, security, and transparency, subsequently influencing the overall robustness and trustworthiness of ML models. In this paper, we introduce ML-On-Rails, a protocol designed to safeguard ML models, establish a well-defined endpoint interface for different ML tasks, and clear communication between ML providers and ML consumers (software engineers). ML-On-Rails enhances the robustness of ML models via incorporating detection capabilities to identify unique challenges specific to production ML. We evaluated the ML-On-Rails protocol through a real-world case study of the MoveReminder application. Through this evaluation, we emphasize the importance of safeguarding ML models in production.
An empirical study of automatic wildlife detection using drone thermal imaging and object detection
Oct 17, 2023Artificial intelligence has the potential to make valuable contributions to wildlife management through cost-effective methods for the collection and interpretation of wildlife data. Recent advances in remotely piloted aircraft systems (RPAS or ``drones'') and thermal imaging technology have created new approaches to collect wildlife data. These emerging technologies could provide promising alternatives to standard labourious field techniques as well as cover much larger areas. In this study, we conduct a comprehensive review and empirical study of drone-based wildlife detection. Specifically, we collect a realistic dataset of drone-derived wildlife thermal detections. Wildlife detections, including arboreal (for instance, koalas, phascolarctos cinereus) and ground dwelling species in our collected data are annotated via bounding boxes by experts. We then benchmark state-of-the-art object detection algorithms on our collected dataset. We use these experimental results to identify issues and discuss future directions in automatic animal monitoring using drones.
Requirements Framework for Engineering Human-centered Artificial Intelligence-Based Software Systems
Mar 06, 2023



[Context] Artificial intelligence (AI) components used in building software solutions have substantially increased in recent years. However, many of these solutions end up focusing on technical aspects and ignore critical human-centered aspects. [Objective] Including human-centered aspects during requirements engineering (RE) when building AI-based software can help achieve more responsible, unbiased, and inclusive AI-based software solutions. [Method] In this paper, we present a new framework developed based on human-centered AI guidelines and a user survey to aid in collecting requirements for human-centered AI-based software. We provide a catalog to elicit these requirements and a conceptual model to present them visually. [Results] The framework is applied to a case study to elicit and model requirements for enhancing the quality of 360 degree~videos intended for virtual reality (VR) users. [Conclusion] We found that our proposed approach helped the project team fully understand the needs of the project to deliver. Furthermore, the framework helped to understand what requirements need to be captured at the initial stages against later stages in the engineering process of AI-based software.
Deep Learning Methods for Credit Card Fraud Detection
Dec 07, 2020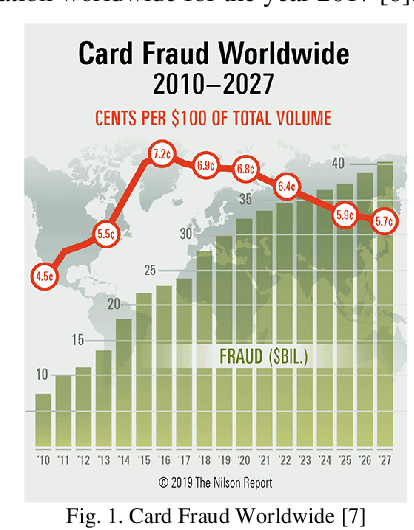
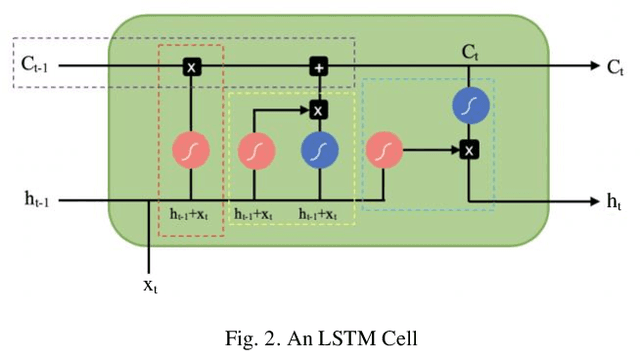
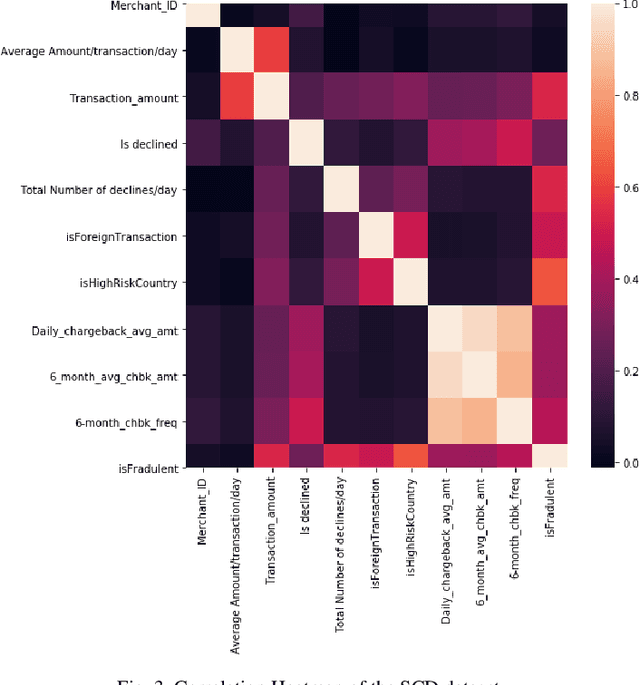
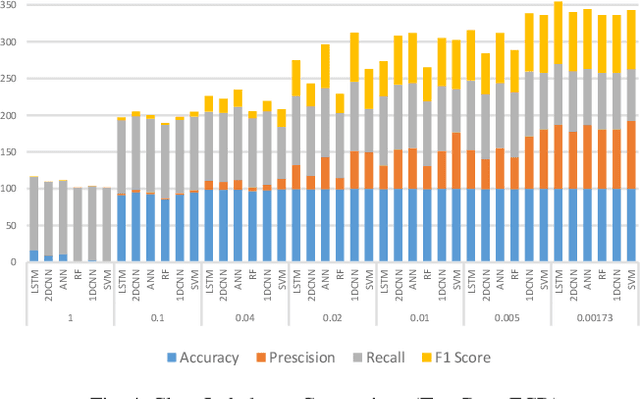
Credit card frauds are at an ever-increasing rate and have become a major problem in the financial sector. Because of these frauds, card users are hesitant in making purchases and both the merchants and financial institutions bear heavy losses. Some major challenges in credit card frauds involve the availability of public data, high class imbalance in data, changing nature of frauds and the high number of false alarms. Machine learning techniques have been used to detect credit card frauds but no fraud detection systems have been able to offer great efficiency to date. Recent development of deep learning has been applied to solve complex problems in various areas. This paper presents a thorough study of deep learning methods for the credit card fraud detection problem and compare their performance with various machine learning algorithms on three different financial datasets. Experimental results show great performance of the proposed deep learning methods against traditional machine learning models and imply that the proposed approaches can be implemented effectively for real-world credit card fraud detection systems.
Beware the evolving 'intelligent' web service! An integration architecture tactic to guard AI-first components
May 27, 2020

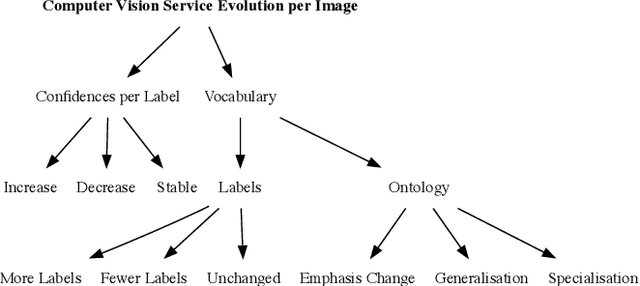
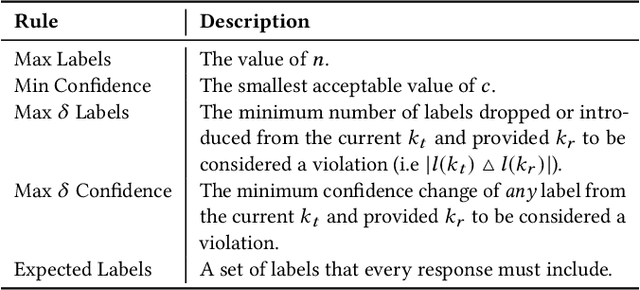
Intelligent services provide the power of AI to developers via simple RESTful API endpoints, abstracting away many complexities of machine learning. However, most of these intelligent services-such as computer vision-continually learn with time. When the internals within the abstracted 'black box' become hidden and evolve, pitfalls emerge in the robustness of applications that depend on these evolving services. Without adapting the way developers plan and construct projects reliant on intelligent services, significant gaps and risks result in both project planning and development. Therefore, how can software engineers best mitigate software evolution risk moving forward, thereby ensuring that their own applications maintain quality? Our proposal is an architectural tactic designed to improve intelligent service-dependent software robustness. The tactic involves creating an application-specific benchmark dataset baselined against an intelligent service, enabling evolutionary behaviour changes to be mitigated. A technical evaluation of our implementation of this architecture demonstrates how the tactic can identify 1,054 cases of substantial confidence evolution and 2,461 cases of substantial changes to response label sets using a dataset consisting of 331 images that evolve when sent to a service.
Interpreting Cloud Computer Vision Pain-Points: A Mining Study of Stack Overflow
Jan 28, 2020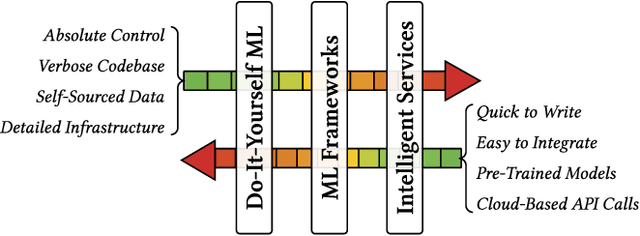
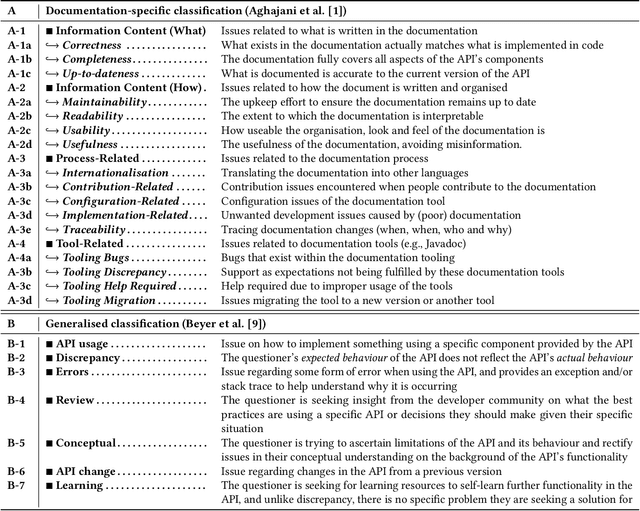
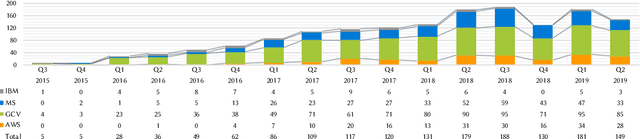

Intelligent services are becoming increasingly more pervasive; application developers want to leverage the latest advances in areas such as computer vision to provide new services and products to users, and large technology firms enable this via RESTful APIs. While such APIs promise an easy-to-integrate on-demand machine intelligence, their current design, documentation and developer interface hides much of the underlying machine learning techniques that power them. Such APIs look and feel like conventional APIs but abstract away data-driven probabilistic behaviour - the implications of a developer treating these APIs in the same way as other, traditional cloud services, such as cloud storage, is of concern. The objective of this study is to determine the various pain-points developers face when implementing systems that rely on the most mature of these intelligent services, specifically those that provide computer vision. We use Stack Overflow to mine indications of the frustrations that developers appear to face when using computer vision services, classifying their questions against two recent classification taxonomies (documentation-related and general questions). We find that, unlike mature fields like mobile development, there is a contrast in the types of questions asked by developers. These indicate a shallow understanding of the underlying technology that empower such systems. We discuss several implications of these findings via the lens of learning taxonomies to suggest how the software engineering community can improve these services and comment on the nature by which developers use them.
Losing Confidence in Quality: Unspoken Evolution of Computer Vision Services
Jul 30, 2019


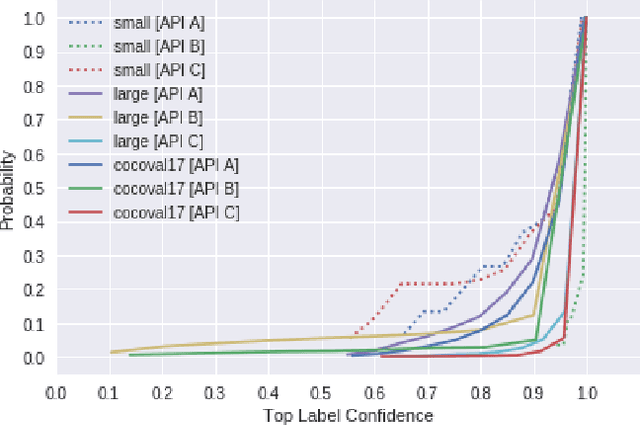
Recent advances in artificial intelligence (AI) and machine learning (ML), such as computer vision, are now available as intelligent services and their accessibility and simplicity is compelling. Multiple vendors now offer this technology as cloud services and developers want to leverage these advances to provide value to end-users. However, there is no firm investigation into the maintenance and evolution risks arising from use of these intelligent services; in particular, their behavioural consistency and transparency of their functionality. We evaluated the responses of three different intelligent services (specifically computer vision) over 11 months using 3 different data sets, verifying responses against the respective documentation and assessing evolution risk. We found that there are: (1) inconsistencies in how these services behave; (2) evolution risk in the responses; and (3) a lack of clear communication that documents these risks and inconsistencies. We propose a set of recommendations to both developers and intelligent service providers to inform risk and assist maintainability.