 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Delirium Risk in Mild Cognitive Impairment Using Time-Series data, Machine Learning and Comorbidity Patterns -- A Retrospective Study
May 05, 2025Delirium represents a significant clinical concern characterized by high morbidity and mortality rates, particularly in patients with mild cognitive impairment (MCI). This study investigates the associated risk factors for delirium by analyzing the comorbidity patterns relevant to MCI and developing a longitudinal predictive model leveraging machine learning methodologies. A retrospective analysis utilizing the MIMIC-IV v2.2 database was performed to evaluate comorbid conditions, survival probabilities, and predictive modeling outcomes. The examination of comorbidity patterns identified distinct risk profiles for the MCI population. Kaplan-Meier survival analysis demonstrated that individuals with MCI exhibit markedly reduced survival probabilities when developing delirium compared to their non-MCI counterparts, underscoring the heightened vulnerability within this cohort. For predictive modeling, a Long Short-Term Memory (LSTM) ML network was implemented utilizing time-series data, demographic variables, Charlson Comorbidity Index (CCI) scores, and an array of comorbid conditions. The model demonstrated robust predictive capabilities with an AUROC of 0.93 and an AUPRC of 0.92. This study underscores the critical role of comorbidities in evaluating delirium risk and highlights the efficacy of time-series predictive modeling in pinpointing patients at elevated risk for delirium development.
MaCmS: Magahi Code-mixed Dataset for Sentiment Analysis
Mar 07, 2024The present paper introduces new sentiment data, MaCMS, for Magahi-Hindi-English (MHE) code-mixed language, where Magahi is a less-resourced minority language. This dataset is the first Magahi-Hindi-English code-mixed dataset for sentiment analysis tasks. Further, we also provide a linguistics analysis of the dataset to understand the structure of code-mixing and a statistical study to understand the language preferences of speakers with different polarities. With these analyses, we also train baseline models to evaluate the dataset's quality.
ML-On-Rails: Safeguarding Machine Learning Models in Software Systems A Case Study
Jan 12, 2024



Machine learning (ML), especially with the emergence of large language models (LLMs), has significantly transformed various industries. However, the transition from ML model prototyping to production use within software systems presents several challenges. These challenges primarily revolve around ensuring safety, security, and transparency, subsequently influencing the overall robustness and trustworthiness of ML models. In this paper, we introduce ML-On-Rails, a protocol designed to safeguard ML models, establish a well-defined endpoint interface for different ML tasks, and clear communication between ML providers and ML consumers (software engineers). ML-On-Rails enhances the robustness of ML models via incorporating detection capabilities to identify unique challenges specific to production ML. We evaluated the ML-On-Rails protocol through a real-world case study of the MoveReminder application. Through this evaluation, we emphasize the importance of safeguarding ML models in production.
Smart Home Goal Feature Model -- A guide to support Smart Homes for Ageing in Place
Nov 14, 2023



Smart technologies are significant in supporting ageing in place for elderly. Leveraging Artificial Intelligence (AI) and Machine Learning (ML), it provides peace of mind, enabling the elderly to continue living independently. Elderly use smart technologies for entertainment and social interactions, this can be extended to provide safety and monitor health and environmental conditions, detect emergencies and notify informal and formal caregivers when care is needed. This paper provides an overview of the smart home technologies commercially available to support ageing in place, the advantages and challenges of smart home technologies, and their usability from elderlys perspective. Synthesizing prior knowledge, we created a structured Smart Home Goal Feature Model (SHGFM) to resolve heuristic approaches used by the Subject Matter Experts (SMEs) at aged care facilities and healthcare researchers in adapting smart homes. The SHGFM provides SMEs the ability to (i) establish goals and (ii) identify features to set up strategies to design, develop and deploy smart homes for the elderly based on personalised needs. Our model provides guidance to healthcare researchers and aged care industries to set up smart homes based on the needs of elderly, by defining a set of goals at different levels mapped to a different set of features.
Weakly-supervised Deep Cognate Detection Framework for Low-Resourced Languages Using Morphological Knowledge of Closely-Related Languages
Nov 09, 2023Exploiting cognates for transfer learning in under-resourced languages is an exciting opportunity for language understanding tasks, including unsupervised machine translation, named entity recognition and information retrieval. Previous approaches mainly focused on supervised cognate detection tasks based on orthographic, phonetic or state-of-the-art contextual language models, which under-perform for most under-resourced languages. This paper proposes a novel language-agnostic weakly-supervised deep cognate detection framework for under-resourced languages using morphological knowledge from closely related languages. We train an encoder to gain morphological knowledge of a language and transfer the knowledge to perform unsupervised and weakly-supervised cognate detection tasks with and without the pivot language for the closely-related languages. While unsupervised, it overcomes the need for hand-crafted annotation of cognates. We performed experiments on different published cognate detection datasets across language families and observed not only significant improvement over the state-of-the-art but also our method outperformed the state-of-the-art supervised and unsupervised methods. Our model can be extended to a wide range of languages from any language family as it overcomes the requirement of the annotation of the cognate pairs for training. The code and dataset building scripts can be found at https://github.com/koustavagoswami/Weakly_supervised-Cognate_Detection
A Survey of Orthographic Information in Machine Translation
Aug 04, 2020Machine translation is one of the applications of natural language processing which has been explored in different languages. Recently researchers started paying attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine translation systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthography's influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic information can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under-resourced languages. We discuss different types of machine translation and demonstrate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cognates information at different levels of machine translation and the lessons that can be drawn from this. Additionally, multilingual neural machine translation of closely related languages is given a particular focus in this survey. This article ends with a discussion of the way forward in machine translation with orthographic information, focusing on multilingual settings and bilingual lexicon induction.
ULD@NUIG at SemEval-2020 Task 9: Generative Morphemes with an Attention Model for Sentiment Analysis in Code-Mixed Text
Jul 27, 2020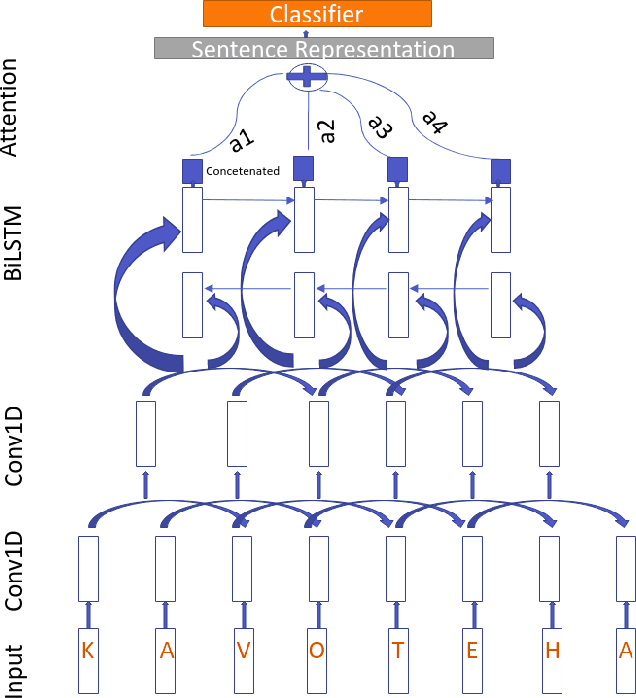
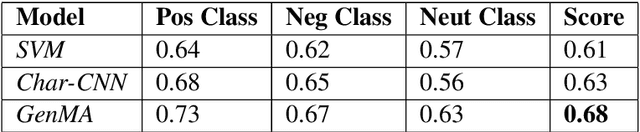
Code mixing is a common phenomena in multilingual societies where people switch from one language to another for various reasons. Recent advances in public communication over different social media sites have led to an increase in the frequency of code-mixed usage in written language. In this paper, we present the Generative Morphemes with Attention (GenMA) Model sentiment analysis system contributed to SemEval 2020 Task 9 SentiMix. The system aims to predict the sentiments of the given English-Hindi code-mixed tweets without using word-level language tags instead inferring this automatically using a morphological model. The system is based on a novel deep neural network (DNN) architecture, which has outperformed the baseline F1-score on the test data-set as well as the validation data-set. Our results can be found under the user name "koustava" on the "Sentimix Hindi English" page
Automatic Language Identification System for Hindi and Magahi
Apr 13, 2018
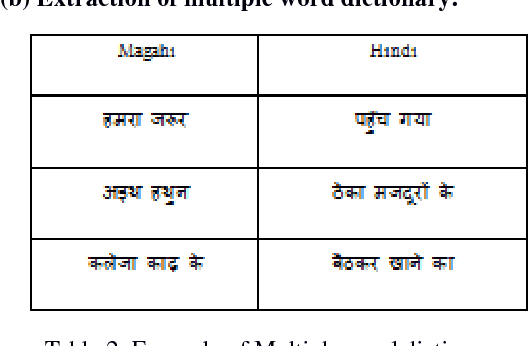
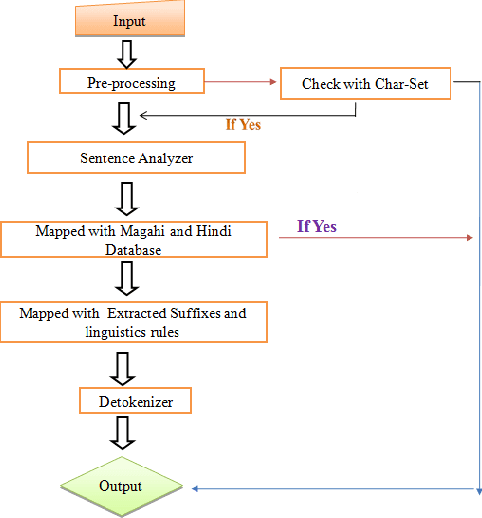
Language identification has become a prerequisite for all kinds of automated text processing systems. In this paper, we present a rule-based language identifier tool for two closely related Indo-Aryan languages: Hindi and Magahi. This system has currently achieved an accuracy of approx 86.34%. We hope to improve this in the future. Automatic identification of languages will be significant in the accuracy of output of Web Crawlers.