 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaCmS: Magahi Code-mixed Dataset for Sentiment Analysis
Mar 07, 2024The present paper introduces new sentiment data, MaCMS, for Magahi-Hindi-English (MHE) code-mixed language, where Magahi is a less-resourced minority language. This dataset is the first Magahi-Hindi-English code-mixed dataset for sentiment analysis tasks. Further, we also provide a linguistics analysis of the dataset to understand the structure of code-mixing and a statistical study to understand the language preferences of speakers with different polarities. With these analyses, we also train baseline models to evaluate the dataset's quality.
Weakly-supervised Deep Cognate Detection Framework for Low-Resourced Languages Using Morphological Knowledge of Closely-Related Languages
Nov 09, 2023Exploiting cognates for transfer learning in under-resourced languages is an exciting opportunity for language understanding tasks, including unsupervised machine translation, named entity recognition and information retrieval. Previous approaches mainly focused on supervised cognate detection tasks based on orthographic, phonetic or state-of-the-art contextual language models, which under-perform for most under-resourced languages. This paper proposes a novel language-agnostic weakly-supervised deep cognate detection framework for under-resourced languages using morphological knowledge from closely related languages. We train an encoder to gain morphological knowledge of a language and transfer the knowledge to perform unsupervised and weakly-supervised cognate detection tasks with and without the pivot language for the closely-related languages. While unsupervised, it overcomes the need for hand-crafted annotation of cognates. We performed experiments on different published cognate detection datasets across language families and observed not only significant improvement over the state-of-the-art but also our method outperformed the state-of-the-art supervised and unsupervised methods. Our model can be extended to a wide range of languages from any language family as it overcomes the requirement of the annotation of the cognate pairs for training. The code and dataset building scripts can be found at https://github.com/koustavagoswami/Weakly_supervised-Cognate_Detection
Findings of the LoResMT 2021 Shared Task on COVID and Sign Language for Low-resource Languages
Aug 18, 2021

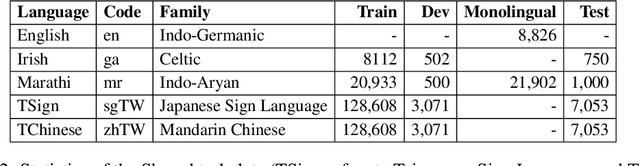
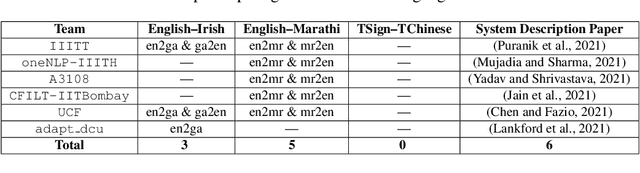
We present the findings of the LoResMT 2021 shared task which focuses on machine translation (MT) of COVID-19 data for both low-resource spoken and sign languages. The organization of this task was conducted as part of the fourth workshop on technologies for machine translation of low resource languages (LoResMT). Parallel corpora is presented and publicly available which includes the following directions: English$\leftrightarrow$Irish, English$\leftrightarrow$Marathi, and Taiwanese Sign language$\leftrightarrow$Traditional Chinese. Training data consists of 8112, 20933 and 128608 segments, respectively. There are additional monolingual data sets for Marathi and English that consist of 21901 segments. The results presented here are based on entries from a total of eight teams. Three teams submitted systems for English$\leftrightarrow$Irish while five teams submitted systems for English$\leftrightarrow$Marathi. Unfortunately, there were no systems submissions for the Taiwanese Sign language$\leftrightarrow$Traditional Chinese task. Maximum system performance was computed using BLEU and follow as 36.0 for English--Irish, 34.6 for Irish--English, 24.2 for English--Marathi, and 31.3 for Marathi--English.
ULD@NUIG at SemEval-2020 Task 9: Generative Morphemes with an Attention Model for Sentiment Analysis in Code-Mixed Text
Jul 27, 2020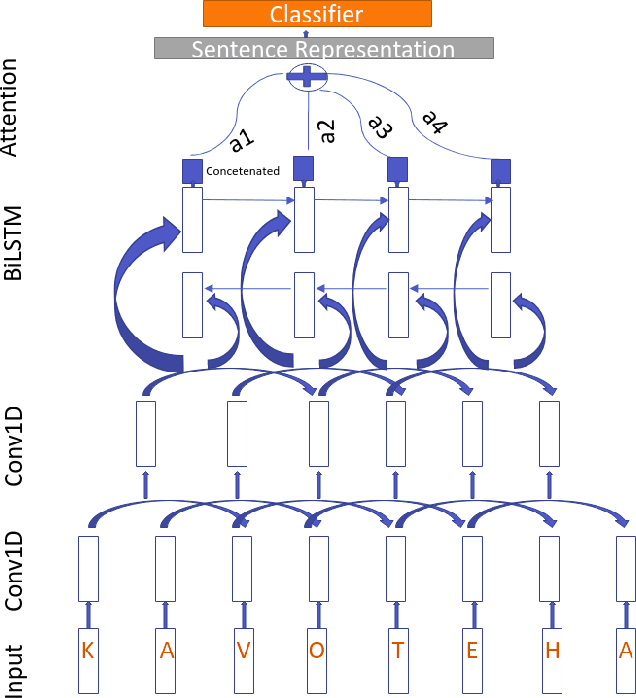
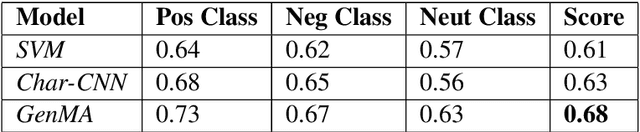
Code mixing is a common phenomena in multilingual societies where people switch from one language to another for various reasons. Recent advances in public communication over different social media sites have led to an increase in the frequency of code-mixed usage in written language. In this paper, we present the Generative Morphemes with Attention (GenMA) Model sentiment analysis system contributed to SemEval 2020 Task 9 SentiMix. The system aims to predict the sentiments of the given English-Hindi code-mixed tweets without using word-level language tags instead inferring this automatically using a morphological model. The system is based on a novel deep neural network (DNN) architecture, which has outperformed the baseline F1-score on the test data-set as well as the validation data-set. Our results can be found under the user name "koustava" on the "Sentimix Hindi English" page