 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
Findings of the LoResMT 2021 Shared Task on COVID and Sign Language for Low-resource Languages
Aug 18, 2021

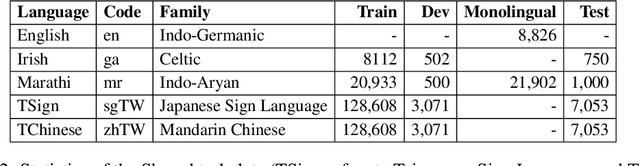
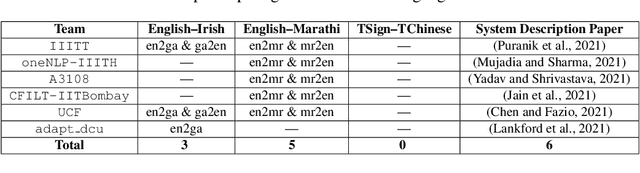
We present the findings of the LoResMT 2021 shared task which focuses on machine translation (MT) of COVID-19 data for both low-resource spoken and sign languages. The organization of this task was conducted as part of the fourth workshop on technologies for machine translation of low resource languages (LoResMT). Parallel corpora is presented and publicly available which includes the following directions: English$\leftrightarrow$Irish, English$\leftrightarrow$Marathi, and Taiwanese Sign language$\leftrightarrow$Traditional Chinese. Training data consists of 8112, 20933 and 128608 segments, respectively. There are additional monolingual data sets for Marathi and English that consist of 21901 segments. The results presented here are based on entries from a total of eight teams. Three teams submitted systems for English$\leftrightarrow$Irish while five teams submitted systems for English$\leftrightarrow$Marathi. Unfortunately, there were no systems submissions for the Taiwanese Sign language$\leftrightarrow$Traditional Chinese task. Maximum system performance was computed using BLEU and follow as 36.0 for English--Irish, 34.6 for Irish--English, 24.2 for English--Marathi, and 31.3 for Marathi--English.
Multiple Segmentations of Thai Sentences for Neural Machine Translation
Apr 23, 2020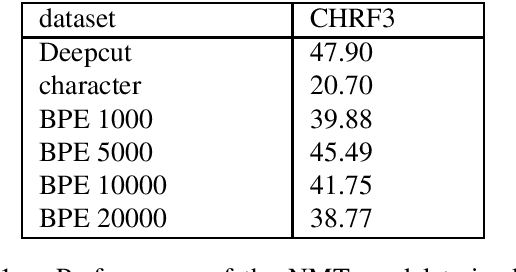
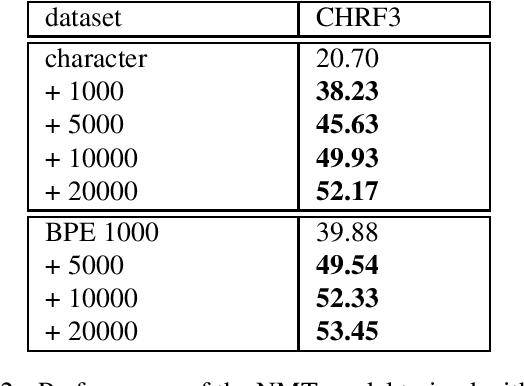

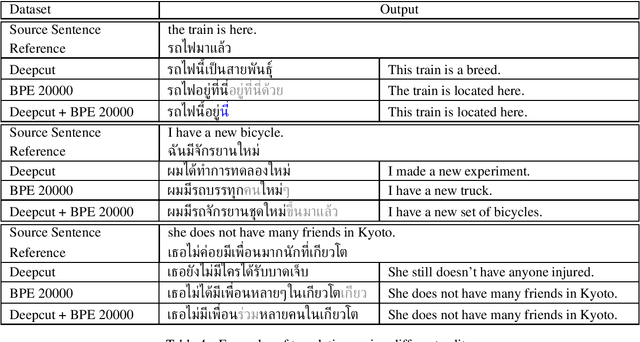
Thai is a low-resource language, so it is often the case that data is not available in sufficient quantities to train an Neural Machine Translation (NMT) model which perform to a high level of quality. In addition, the Thai script does not use white spaces to delimit the boundaries between words, which adds more complexity when building sequence to sequence models. In this work, we explore how to augment a set of English--Thai parallel data by replicating sentence-pairs with different word segmentation methods on Thai, as training data for NMT model training. Using different merge operations of Byte Pair Encoding, different segmentations of Thai sentences can be obtained. The experiments show that combining these datasets, performance is improved for NMT models trained with a dataset that has been split using a supervised splitting tool.
The RGNLP Machine Translation Systems for WAT 2018
Dec 03, 2018
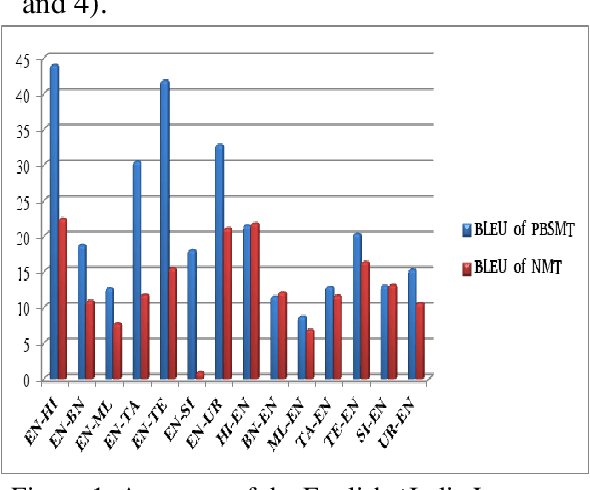
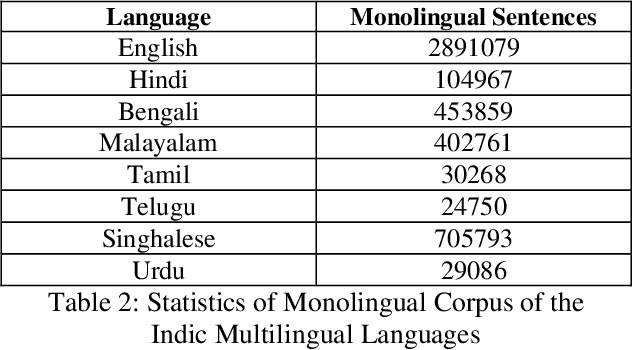
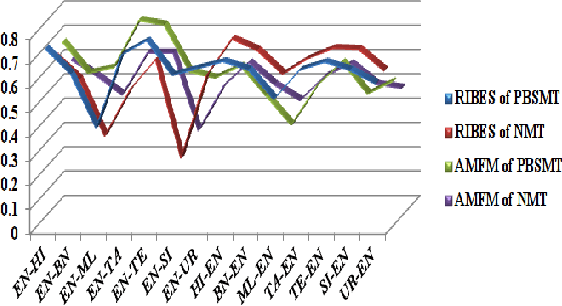
This paper presents the system description of Machine Translation (MT) system(s) for Indic Languages Multilingual Task for the 2018 edition of the WAT Shared Task. In our experiments, we (the RGNLP team) explore both statistical and neural methods across all language pairs. (We further present an extensive comparison of language-related problems for both the approaches in the context of low-resourced settings.) Our PBSMT models were highest score on all automatic evaluation metrics in the English into Telugu, Hindi, Bengali, Tamil portion of the shared task.
Understanding Meanings in Multilingual Customer Feedback
Jun 05, 2018
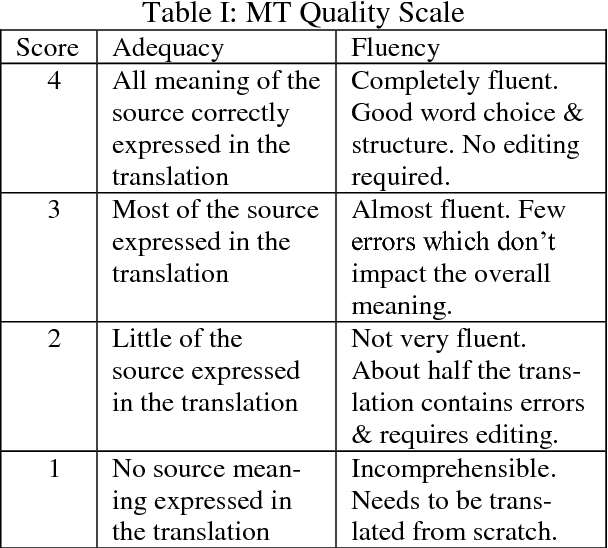

Understanding and being able to react to customer feedback is the most fundamental task in providing good customer service. However, there are two major obstacles for international companies to automatically detect the meaning of customer feedback in a global multilingual environment. Firstly, there is no widely acknowledged categorisation (classes) of meaning for customer feedback. Secondly, the applicability of one meaning categorisation, if it exists, to customer feedback in multiple languages is questionable. In this paper, we extracted representative real world samples of customer feedback from Microsoft Office customers in multiple languages, English, Spanish and Japanese,and concluded a five-class categorisation(comment, request, bug, complaint and meaningless) for meaning classification that could be used across languages in the realm of customer feedback analysis.
Chinese-Portuguese Machine Translation: A Study on Building Parallel Corpora from Comparable Texts
Apr 05, 2018
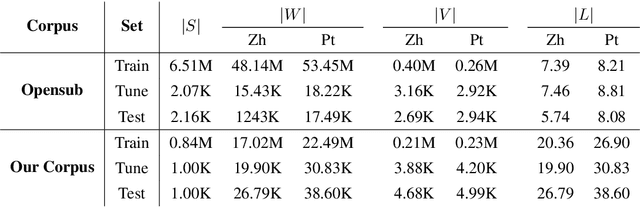
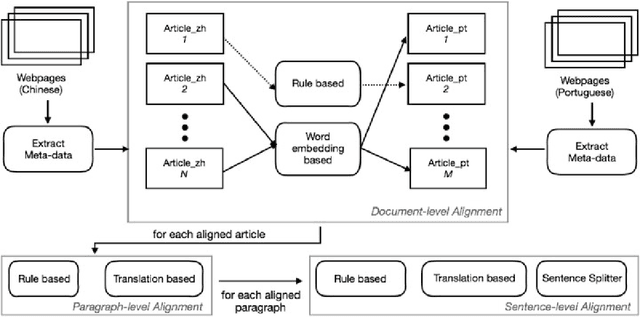

Although there are increasing and significant ties between China and Portuguese-speaking countries, there is not much parallel corpora in the Chinese-Portuguese language pair. Both languages are very populous, with 1.2 billion native Chinese speakers and 279 million native Portuguese speakers, the language pair, however, could be considered as low-resource in terms of available parallel corpora. In this paper, we describe our methods to curate Chinese-Portuguese parallel corpora and evaluate their quality. We extracted bilingual data from Macao government websites and proposed a hierarchical strategy to build a large parallel corpus. Experiments are conducted on existing and our corpora using both Phrased-Based Machine Translation (PBMT) and the state-of-the-art Neural Machine Translation (NMT) models. The results of this work can be used as a benchmark for future Chinese-Portuguese MT systems. The approach we used in this paper also shows a good example on how to boost performance of MT systems for low-resource language pairs.