 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the WMT 2024 Shared Task on Discourse-Level Literary Translation
Dec 16, 2024Following last year, we have continued to host the WMT translation shared task this year, the second edition of the Discourse-Level Literary Translation. We focus on three language directions: Chinese-English, Chinese-German, and Chinese-Russian, with the latter two ones newly added. This year, we totally received 10 submissions from 5 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. We release data, system outputs, and leaderboard at https://www2.statmt.org/wmt24/literary-translation-task.html.
Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
How Does Pretraining Improve Discourse-Aware Translation?
May 31, 2023



Pretrained language models (PLMs) have produced substantial improvements in discourse-aware neural machine translation (NMT), for example, improved coherence in spoken language translation. However, the underlying reasons for their strong performance have not been well explained. To bridge this gap, we introduce a probing task to interpret the ability of PLMs to capture discourse relation knowledge. We validate three state-of-the-art PLMs across encoder-, decoder-, and encoder-decoder-based models. The analysis shows that (1) the ability of PLMs on discourse modelling varies from architecture and layer; (2) discourse elements in a text lead to different learning difficulties for PLMs. Besides, we investigate the effects of different PLMs on spoken language translation. Through experiments on IWSLT2017 Chinese-English dataset, we empirically reveal that NMT models initialized from different layers of PLMs exhibit the same trends with the probing task. Our findings are instructive to understand how and when discourse knowledge in PLMs should work for downstream tasks.
A Survey on Zero Pronoun Translation
May 17, 2023



Zero pronouns (ZPs) are frequently omitted in pro-drop languages (e.g. Chinese, Hungarian, and Hindi), but should be recalled in non-pro-drop languages (e.g. English). This phenomenon has been studied extensively in machine translation (MT), as it poses a significant challenge for MT systems due to the difficulty in determining the correct antecedent for the pronoun. This survey paper highlights the major works that have been undertaken in zero pronoun translation (ZPT) after the neural revolution, so that researchers can recognise the current state and future directions of this field. We provide an organisation of the literature based on evolution, dataset, method and evaluation. In addition, we compare and analyze competing models and evaluation metrics on different benchmarks. We uncover a number of insightful findings such as: 1) ZPT is in line with the development trend of large language model; 2) data limitation causes learning bias in languages and domains; 3) performance improvements are often reported on single benchmarks, but advanced methods are still far from real-world use; 4) general-purpose metrics are not reliable on nuances and complexities of ZPT, emphasizing the necessity of targeted metrics; 5) apart from commonly-cited errors, ZPs will cause risks of gender bias.
Chinese-Portuguese Machine Translation: A Study on Building Parallel Corpora from Comparable Texts
Apr 05, 2018
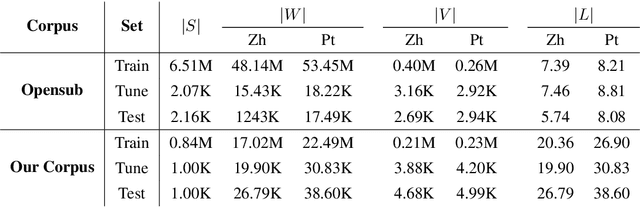
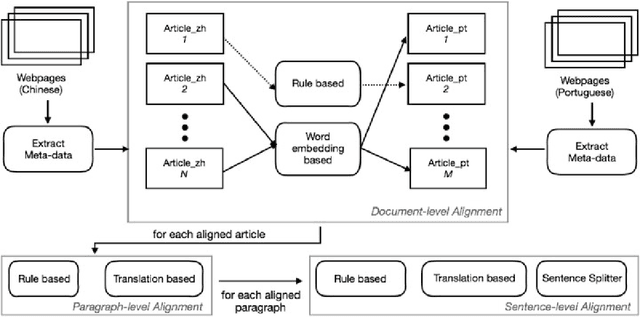

Although there are increasing and significant ties between China and Portuguese-speaking countries, there is not much parallel corpora in the Chinese-Portuguese language pair. Both languages are very populous, with 1.2 billion native Chinese speakers and 279 million native Portuguese speakers, the language pair, however, could be considered as low-resource in terms of available parallel corpora. In this paper, we describe our methods to curate Chinese-Portuguese parallel corpora and evaluate their quality. We extracted bilingual data from Macao government websites and proposed a hierarchical strategy to build a large parallel corpus. Experiments are conducted on existing and our corpora using both Phrased-Based Machine Translation (PBMT) and the state-of-the-art Neural Machine Translation (NMT) models. The results of this work can be used as a benchmark for future Chinese-Portuguese MT systems. The approach we used in this paper also shows a good example on how to boost performance of MT systems for low-resource language pairs.