 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Information Seeking Agent Consolidation
Jan 31, 2026Information-seeking agents have emerged as a powerful paradigm for solving knowledge-intensive tasks. Existing information-seeking agents are typically specialized for open web, documents, or local knowledge bases, which constrains scalability and cross-domain generalization. In this work, we investigate how to consolidate heterogeneous information-seeking agents into a single foundation agentic model. We study two complementary consolidation strategies: data-level consolidation, which jointly trains a unified model on a mixture of domain-specific datasets, and parameter-level consolidation, which merges independently trained agent models at the parameter level. Our analysis compares these approaches in terms of performance retention, cross-domain generalization, and interference across information-seeking behaviors. Our results show that data-level consolidation remains a strong and stable baseline, while parameter-level consolidation offers a promising, efficient alternative but suffers from interference and robustness challenges. We further identify key design factors for effective agent consolidation at the parameter level, including fine-grained merging granularity, awareness of task heterogeneity, and principled consensus strategy.
RAGShaper: Eliciting Sophisticated Agentic RAG Skills via Automated Data Synthesis
Jan 13, 2026Agentic Retrieval-Augmented Generation (RAG) empowers large language models to autonomously plan and retrieve information for complex problem-solving. However, the development of robust agents is hindered by the scarcity of high-quality training data that reflects the noise and complexity of real-world retrieval environments. Conventional manual annotation is unscalable and often fails to capture the dynamic reasoning strategies required to handle retrieval failures. To bridge this gap, we introduce RAGShaper, a novel data synthesis framework designed to automate the construction of RAG tasks and robust agent trajectories. RAGShaper incorporates an InfoCurator to build dense information trees enriched with adversarial distractors spanning Perception and Cognition levels. Furthermore, we propose a constrained navigation strategy that forces a teacher agent to confront these distractors, thereby eliciting trajectories that explicitly demonstrate error correction and noise rejection. Comprehensive experiments confirm that models trained on our synthesized corpus significantly outperform existing baselines, exhibiting superior robustness in noise-intensive and complex retrieval tasks.
DocDancer: Towards Agentic Document-Grounded Information Seeking
Jan 08, 2026Document Question Answering (DocQA) focuses on answering questions grounded in given documents, yet existing DocQA agents lack effective tool utilization and largely rely on closed-source models. In this work, we introduce DocDancer, an end-to-end trained open-source Doc agent. We formulate DocQA as an information-seeking problem and propose a tool-driven agent framework that explicitly models document exploration and comprehension. To enable end-to-end training of such agents, we introduce an Exploration-then-Synthesis data synthesis pipeline that addresses the scarcity of high-quality training data for DocQA. Training on the synthesized data, the trained models on two long-context document understanding benchmarks, MMLongBench-Doc and DocBench, show their effectiveness. Further analysis provides valuable insights for the agentic tool design and synthetic data.
Collaborative Optimization of Multiclass Imbalanced Learning: Density-Aware and Region-Guided Boosting
Dec 27, 2025Numerous studies attempt to mitigate classification bias caused by class imbalance. However, existing studies have yet to explore the collaborative optimization of imbalanced learning and model training. This constraint hinders further performance improvements. To bridge this gap, this study proposes a collaborative optimization Boosting model of multiclass imbalanced learning. This model is simple but effective by integrating the density factor and the confidence factor, this study designs a noise-resistant weight update mechanism and a dynamic sampling strategy. Rather than functioning as independent components, these modules are tightly integrated to orchestrate weight updates, sample region partitioning, and region-guided sampling. Thus, this study achieves the collaborative optimization of imbalanced learning and model training. Extensive experiments on 20 public imbalanced datasets demonstrate that the proposed model significantly outperforms eight state-of-the-art baselines. The code for the proposed model is available at: https://github.com/ChuantaoLi/DARG.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
DeepCompress: A Dual Reward Strategy for Dynamically Exploring and Compressing Reasoning Chains
Oct 31, 2025Large Reasoning Models (LRMs) have demonstrated impressive capabilities but suffer from cognitive inefficiencies like ``overthinking'' simple problems and ``underthinking'' complex ones. While existing methods that use supervised fine-tuning~(SFT) or reinforcement learning~(RL) with token-length rewards can improve efficiency, they often do so at the cost of accuracy. This paper introduces \textbf{DeepCompress}, a novel framework that simultaneously enhances both the accuracy and efficiency of LRMs. We challenge the prevailing approach of consistently favoring shorter reasoning paths, showing that longer responses can contain a broader range of correct solutions for difficult problems. DeepCompress employs an adaptive length reward mechanism that dynamically classifies problems as ``Simple'' or ``Hard'' in real-time based on the model's evolving capability. It encourages shorter, more efficient reasoning for ``Simple'' problems while promoting longer, more exploratory thought chains for ``Hard'' problems. This dual-reward strategy enables the model to autonomously adjust its Chain-of-Thought (CoT) length, compressing reasoning for well-mastered problems and extending it for those it finds challenging. Experimental results on challenging mathematical benchmarks show that DeepCompress consistently outperforms baseline methods, achieving superior accuracy while significantly improving token efficiency.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025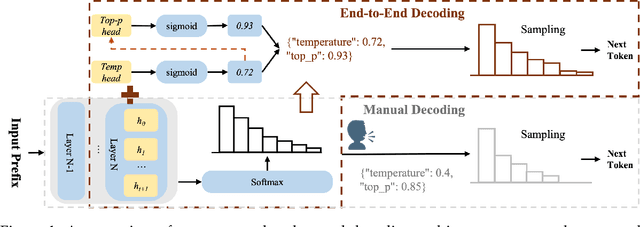
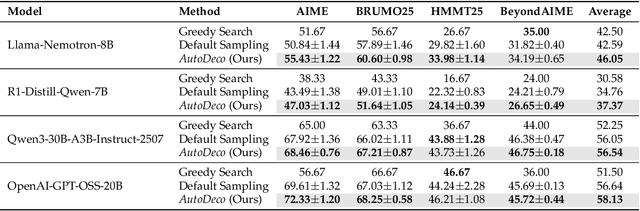
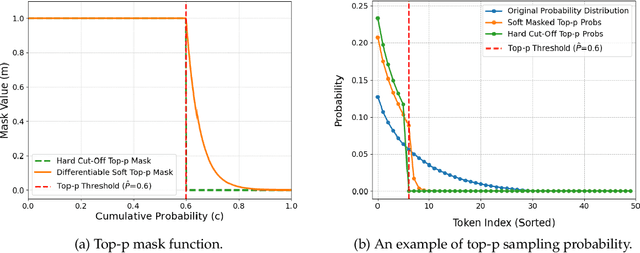
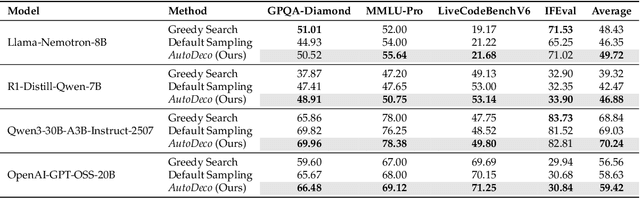
The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
Less is More: Denoising Knowledge Graphs For Retrieval Augmented Generation
Oct 16, 2025Retrieval-Augmented Generation (RAG) systems enable large language models (LLMs) instant access to relevant information for the generative process, demonstrating their superior performance in addressing common LLM challenges such as hallucination, factual inaccuracy, and the knowledge cutoff. Graph-based RAG further extends this paradigm by incorporating knowledge graphs (KGs) to leverage rich, structured connections for more precise and inferential responses. A critical challenge, however, is that most Graph-based RAG systems rely on LLMs for automated KG construction, often yielding noisy KGs with redundant entities and unreliable relationships. This noise degrades retrieval and generation performance while also increasing computational cost. Crucially, current research does not comprehensively address the denoising problem for LLM-generated KGs. In this paper, we introduce DEnoised knowledge Graphs for Retrieval Augmented Generation (DEG-RAG), a framework that addresses these challenges through: (1) entity resolution, which eliminates redundant entities, and (2) triple reflection, which removes erroneous relations. Together, these techniques yield more compact, higher-quality KGs that significantly outperform their unprocessed counterparts. Beyond the methods, we conduct a systematic evaluation of entity resolution for LLM-generated KGs, examining different blocking strategies, embedding choices, similarity metrics, and entity merging techniques. To the best of our knowledge, this is the first comprehensive exploration of entity resolution in LLM-generated KGs. Our experiments demonstrate that this straightforward approach not only drastically reduces graph size but also consistently improves question answering performance across diverse popular Graph-based RAG variants.
On the Out-of-Distribution Backdoor Attack for Federated Learning
Sep 16, 2025Traditional backdoor attacks in federated learning (FL) operate within constrained attack scenarios, as they depend on visible triggers and require physical modifications to the target object, which limits their practicality. To address this limitation, we introduce a novel backdoor attack prototype for FL called the out-of-distribution (OOD) backdoor attack ($\mathtt{OBA}$), which uses OOD data as both poisoned samples and triggers simultaneously. Our approach significantly broadens the scope of backdoor attack scenarios in FL. To improve the stealthiness of $\mathtt{OBA}$, we propose $\mathtt{SoDa}$, which regularizes both the magnitude and direction of malicious local models during local training, aligning them closely with their benign versions to evade detection. Empirical results demonstrate that $\mathtt{OBA}$ effectively circumvents state-of-the-art defenses while maintaining high accuracy on the main task. To address this security vulnerability in the FL system, we introduce $\mathtt{BNGuard}$, a new server-side defense method tailored against $\mathtt{SoDa}$. $\mathtt{BNGuard}$ leverages the observation that OOD data causes significant deviations in the running statistics of batch normalization layers. This allows $\mathtt{BNGuard}$ to identify malicious model updates and exclude them from aggregation, thereby enhancing the backdoor robustness of FL. Extensive experiments across various settings show the effectiveness of $\mathtt{BNGuard}$ on defending against $\mathtt{SoDa}$. The code is available at https://github.com/JiiahaoXU/SoDa-BNGuard.
EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
Sep 16, 2025Large Language Models (LLMs) have recently advanced the field of Automated Theorem Proving (ATP), attaining substantial performance gains through widely adopted test-time scaling strategies, notably reflective Chain-of-Thought (CoT) reasoning and increased sampling passes. However, they both introduce significant computational overhead for inference. Moreover, existing cost analyses typically regulate only the number of sampling passes, while neglecting the substantial disparities in sampling costs introduced by different scaling strategies. In this paper, we systematically compare the efficiency of different test-time scaling strategies for ATP models and demonstrate the inefficiency of the current state-of-the-art (SOTA) open-source approaches. We then investigate approaches to significantly reduce token usage and sample passes while maintaining the original performance. Specifically, we propose two complementary methods that can be integrated into a unified EconRL pipeline for amplified benefits: (1) a dynamic Chain-of-Thought (CoT) switching mechanism designed to mitigate unnecessary token consumption, and (2) Diverse parallel-scaled reinforcement learning (RL) with trainable prefixes to enhance pass rates under constrained sampling passes. Experiments on miniF2F and ProofNet demonstrate that our EconProver achieves comparable performance to baseline methods with only 12% of the computational cost. This work provides actionable insights for deploying lightweight ATP models without sacrificing performance.