 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCO-MAP: A Reinforcement Learning Approach to the Qubit Allocation Problem
May 13, 2026A quantum compiler is a critical piece in the quantum computing pipeline since it allows an abstract quantum circuit to be run on a physical quantum computer. One extremely important subproblem in quantum compilation is the generation of a logical to physical qubit mapping. Typically in quantum compilers this step is either implemented as a random or a heuristic based assignment that aims to minimize additional (SWAP) gate overhead in the quantum circuit. In this paper, we present an alternative approach to solving the qubit mapping problem. Specifically, we formulate the qubit mapping problem with a combinatorial optimization (CO) objective. We then present a method to find a solution to the CO problem by training a reinforcement learning (RL) policy. We also propose a local search based post-processing algorithm to further reduce the overhead. Our results show a dramatic improvement over conventional techniques in reducing the number of SWAPs. On different real world datasets like MQTBench and Queko circuits, our trained policy achieves a \textbf{65-85\%} reduction in SWAP overhead when compared to existing quantum compilers.
QAP-Router: Tackling Qubit Routing as Dynamic Quadratic Assignment with Reinforcement Learning
May 12, 2026Qubit routing is a fundamental problem in quantum compilation, known to be NP-hard. Its dynamic nature makes local routing decisions propagate and compound over time, making global efficient solutions challenging. Existing heuristic methods rely on local rules with limited lookahead, while recent learning-based approaches often treat routing as a generic sequential decision problem without fully exploiting its underlying structure. In this paper, we introduce QAP-Router, framing qubit routing based on a dynamic Quadratic Assignment Problem (QAP) formulation. By modeling logical interactions, or quantum gates, as flow matrices and hardware topology as a distance matrix, our approach captures the interaction-distance coupling in a unified objective, which defines the reward in the reinforcement learning environment. To further exploit this structure, the policy network employs a solution-aware Transformer backbone that encodes the interaction between the flow matrix and the distance matrix into the attention mechanism. We also integrate a lookahead mechanism that blends naturally into the QAP framework, preventing myopic decisions. Extensive experiments on 1,831 real-world quantum circuits from the MQTBench, AgentQ and QUEKO datasets show that our method substantially reduces the CNOT gate count of routed circuits by 15.7%, 30.4% and 12.1%, respectively, relative to existing industry compilers.
The Attack and Defense Landscape of Agentic AI: A Comprehensive Survey
Mar 11, 2026AI agents that combine large language models with non-AI system components are rapidly emerging in real-world applications, offering unprecedented automation and flexibility. However, this unprecedented flexibility introduces complex security challenges fundamentally different from those in traditional software systems. This paper presents the first systematic and comprehensive survey of AI agent security, including an analysis of the design space, attack landscape, and defense mechanisms for secure AI agent systems. We further conduct case studies to point out existing gaps in securing agentic AI systems and identify open challenges in this emerging domain. Our work also introduces the first systematic framework for understanding the security risks and defense strategies of AI agents, serving as a foundation for building both secure agentic systems and advancing research in this critical area.
The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
Feb 12, 2026In the world of Harry Potter, when Dumbledore's mind is overburdened, he extracts memories into a Pensieve to be revisited later. In the world of AI, while we possess the Pensieve-mature databases and retrieval systems, our models inexplicably lack the "wand" to operate it. They remain like a Dumbledore without agency, passively accepting a manually engineered context as their entire memory. This work finally places the wand in the model's hand. We introduce StateLM, a new class of foundation models endowed with an internal reasoning loop to manage their own state. We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking, and train it to actively manage these tools. By learning to dynamically engineering its own context, our model breaks free from the architectural prison of a fixed window. Experiments across various model sizes demonstrate StateLM's effectiveness across diverse scenarios. On long-document QA tasks, StateLMs consistently outperform standard LLMs across all model scales; on the chat memory task, they achieve absolute accuracy improvements of 10% to 20% over standard LLMs. On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced: StateLM achieves up to 52% accuracy, whereas standard LLM counterparts struggle around 5%. Ultimately, our approach shifts LLMs from passive predictors to state-aware agents where reasoning becomes a stateful and manageable process.
IO-RAE: Information-Obfuscation Reversible Adversarial Example for Audio Privacy Protection
Jan 03, 2026The rapid advancements in artificial intelligence have significantly accelerated the adoption of speech recognition technology, leading to its widespread integration across various applications. However, this surge in usage also highlights a critical issue: audio data is highly vulnerable to unauthorized exposure and analysis, posing significant privacy risks for businesses and individuals. This paper introduces an Information-Obfuscation Reversible Adversarial Example (IO-RAE) framework, the pioneering method designed to safeguard audio privacy using reversible adversarial examples. IO-RAE leverages large language models to generate misleading yet contextually coherent content, effectively preventing unauthorized eavesdropping by humans and Automatic Speech Recognition (ASR) systems. Additionally, we propose the Cumulative Signal Attack technique, which mitigates high-frequency noise and enhances attack efficacy by targeting low-frequency signals. Our approach ensures the protection of audio data without degrading its quality or our ability. Experimental evaluations demonstrate the superiority of our method, achieving a targeted misguidance rate of 96.5% and a remarkable 100% untargeted misguidance rate in obfuscating target keywords across multiple ASR models, including a commercial black-box system from Google. Furthermore, the quality of the recovered audio, measured by the Perceptual Evaluation of Speech Quality score, reached 4.45, comparable to high-quality original recordings. Notably, the recovered audio processed by ASR systems exhibited an error rate of 0%, indicating nearly lossless recovery. These results highlight the practical applicability and effectiveness of our IO-RAE framework in protecting sensitive audio privacy.
Scalable Supervising Software Agents with Patch Reasoner
Oct 26, 2025



While large language model agents have advanced software engineering tasks, the unscalable nature of existing test-based supervision is limiting the potential improvement of data scaling. The reason is twofold: (1) building and running test sandbox is rather heavy and fragile, and (2) data with high-coverage tests is naturally rare and threatened by test hacking via edge cases. In this paper, we propose R4P, a patch verifier model to provide scalable rewards for training and testing SWE agents via reasoning. We consider that patch verification is fundamentally a reasoning task, mirroring how human repository maintainers review patches without writing and running new reproduction tests. To obtain sufficient reference and reduce the risk of reward hacking, R4P uses a group-wise objective for RL training, enabling it to verify multiple patches against each other's modification and gain a dense reward for stable training. R4P achieves 72.2% Acc. for verifying patches from SWE-bench-verified, surpassing OpenAI o3. To demonstrate R4P's practicality, we design and train a lite scaffold, Mini-SE, with pure reinforcement learning where all rewards are derived from R4P. As a result, Mini-SE achieves 26.2% Pass@1 on SWE-bench-verified, showing a 10.0% improvement over the original Qwen3-32B. This can be further improved to 32.8% with R4P for test-time scaling. Furthermore, R4P verifies patches within a second, 50x faster than testing on average. The stable scaling curves of rewards and accuracy along with high efficiency reflect R4P's practicality.
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Oct 09, 2025Large language models for mathematical reasoning are typically trained with outcome-based rewards, which credit only the final answer. In our experiments, we observe that this paradigm is highly susceptible to reward hacking, leading to a substantial overestimation of a model's reasoning ability. This is evidenced by a high incidence of false positives - solutions that reach the correct final answer through an unsound reasoning process. Through a systematic analysis with human verification, we establish a taxonomy of these failure modes, identifying patterns like Miracle Steps - abrupt jumps to a correct output without a valid preceding derivation. Probing experiments suggest a strong association between these Miracle Steps and memorization, where the model appears to recall the answer directly rather than deriving it. To mitigate this systemic issue, we introduce the Rubric Reward Model (RRM), a process-oriented reward function that evaluates the entire reasoning trajectory against problem-specific rubrics. The generative RRM provides fine-grained, calibrated rewards (0-1) that explicitly penalize logical flaws and encourage rigorous deduction. When integrated into a reinforcement learning pipeline, RRM-based training consistently outperforms outcome-only supervision across four math benchmarks. Notably, it boosts Verified Pass@1024 on AIME2024 from 26.7% to 62.6% and reduces the incidence of Miracle Steps by 71%. Our work demonstrates that rewarding the solution process is crucial for building models that are not only more accurate but also more reliable.
Neural Architecture Search Algorithms for Quantum Autoencoders
Sep 18, 2025The design of quantum circuits is currently driven by the specific objectives of the quantum algorithm in question. This approach thus relies on a significant manual effort by the quantum algorithm designer to design an appropriate circuit for the task. However this approach cannot scale to more complex quantum algorithms in the future without exponentially increasing the circuit design effort and introducing unwanted inductive biases. Motivated by this observation, we propose to automate the process of cicuit design by drawing inspiration from Neural Architecture Search (NAS). In this work, we propose two Quantum-NAS algorithms that aim to find efficient circuits given a particular quantum task. We choose quantum data compression as our driver quantum task and demonstrate the performance of our algorithms by finding efficient autoencoder designs that outperform baselines on three different tasks - quantum data denoising, classical data compression and pure quantum data compression. Our results indicate that quantum NAS algorithms can significantly alleviate the manual effort while delivering performant quantum circuits for any given task.
Unsourced Adversarial CAPTCHA: A Bi-Phase Adversarial CAPTCHA Framework
Jun 12, 2025
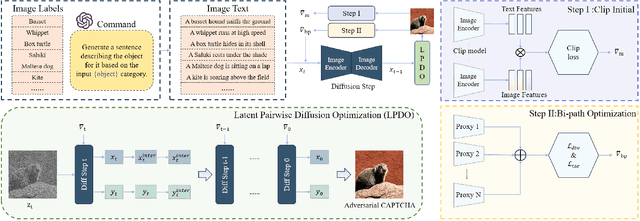

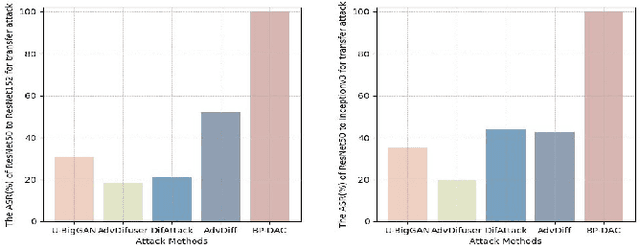
With the rapid advancements in deep learning, traditional CAPTCHA schemes are increasingly vulnerable to automated attacks powered by deep neural networks (DNNs). Existing adversarial attack methods often rely on original image characteristics, resulting in distortions that hinder human interpretation and limit applicability in scenarios lacking initial input images. To address these challenges, we propose the Unsourced Adversarial CAPTCHA (UAC), a novel framework generating high-fidelity adversarial examples guided by attacker-specified text prompts. Leveraging a Large Language Model (LLM), UAC enhances CAPTCHA diversity and supports both targeted and untargeted attacks. For targeted attacks, the EDICT method optimizes dual latent variables in a diffusion model for superior image quality. In untargeted attacks, especially for black-box scenarios, we introduce bi-path unsourced adversarial CAPTCHA (BP-UAC), a two-step optimization strategy employing multimodal gradients and bi-path optimization for efficient misclassification. Experiments show BP-UAC achieves high attack success rates across diverse systems, generating natural CAPTCHAs indistinguishable to humans and DNNs.
Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards
May 19, 2025Large Language Models (LLMs) show great promise in complex reasoning, with Reinforcement Learning with Verifiable Rewards (RLVR) being a key enhancement strategy. However, a prevalent issue is ``superficial self-reflection'', where models fail to robustly verify their own outputs. We introduce RISE (Reinforcing Reasoning with Self-Verification), a novel online RL framework designed to tackle this. RISE explicitly and simultaneously trains an LLM to improve both its problem-solving and self-verification abilities within a single, integrated RL process. The core mechanism involves leveraging verifiable rewards from an outcome verifier to provide on-the-fly feedback for both solution generation and self-verification tasks. In each iteration, the model generates solutions, then critiques its own on-policy generated solutions, with both trajectories contributing to the policy update. Extensive experiments on diverse mathematical reasoning benchmarks show that RISE consistently improves model's problem-solving accuracy while concurrently fostering strong self-verification skills. Our analyses highlight the advantages of online verification and the benefits of increased verification compute. Additionally, RISE models exhibit more frequent and accurate self-verification behaviors during reasoning. These advantages reinforce RISE as a flexible and effective path towards developing more robust and self-aware reasoners.