 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalDentBench: A Multinational Benchmark for Evaluating LLM Clinical Reasoning in Dentistry with Expert Calibration
May 26, 2026While large language models (LLMs) hold transformative potential for medicine, their reasoning robustness and safety in real-world clinical scenarios remain critically underexplored, particularly in dentistry. Here we introduce GlobalDentBench, the first multinational dental benchmark, featuring a taxonomy that encompasses 14 dental specialties across 88 countries and regions spanning six continents. The benchmark comprises 8,978 expert-validated questions across three formats (multiple-choice, short-answer, and case-based questions) and assesses three progressive reasoning levels: knowledge recall (L1), routine reasoning (L2), and individualized reasoning (L3). To ensure data quality, the automated construction framework was calibrated by six senior dentists, achieving expert agreement rates of 99.98% for multiple-choice and short-answer questions and 96.78% for the more complex case-based questions. Evaluation of 12 frontier LLMs on GlobalDentBench revealed a sharp, stepwise performance degradation with increasing reasoning complexity. Specifically, accuracy plummeted from 81.34% on multiple-choice to 64.53% on short-answer and 22.34% on case-based questions, while declining markedly from 74.01% at L1 to 55.64% at L2 and 35.71% at L3. More critically, risk analysis of real-world dental cases demonstrated an alarming overall unsafe rate of 31.01% in LLM-generated clinical recommendations, with 4.51% posing risks of irreversible patient harm and risks particularly pronounced in specialties such as orthodontics. These findings expose fundamental limitations in the medical reasoning and safety of current LLMs. Consequently, GlobalDentBench provides a scalable foundation for trustworthy clinical AI evaluation, underscoring the urgent need for rigorous validation before the safe deployment of these models in healthcare.
Decouple and Rectify: Semantics-Preserving Structural Enhancement for Open-Vocabulary Remote Sensing Segmentation
Apr 02, 2026Open-vocabulary semantic segmentation in the remote sensing (RS) field requires both language-aligned recognition and fine-grained spatial delineation. Although CLIP offers robust semantic generalization, its global-aligned visual representations inherently struggle to capture structural details. Recent methods attempt to compensate for this by introducing RS-pretrained DINO features. However, these methods treat CLIP representations as a monolithic semantic space and cannot localize where structural enhancement is required, failing to effectively delineate boundaries while risking the disruption of CLIP's semantic integrity. To address this limitation, we propose DR-Seg, a novel decouple-and-rectify framework in this paper. Our method is motivated by the key observation that CLIP feature channels exhibit distinct functional heterogeneity rather than forming a uniform semantic space. Building on this insight, DR-Seg decouples CLIP features into semantics-dominated and structure-dominated subspaces, enabling targeted structural enhancement by DINO without distorting language-aligned semantics. Subsequently, a prior-driven graph rectification module injects high-fidelity structural priors under DINO guidance to form a refined branch, while an uncertainty-guided adaptive fusion module dynamically integrates this refined branch with the original CLIP branch for final prediction. Comprehensive experiments across eight benchmarks demonstrate that DR-Seg establishes a new state-of-the-art.
MicroVerse: A Preliminary Exploration Toward a Micro-World Simulation
Feb 28, 2026Recent advances in video generation have opened new avenues for macroscopic simulation of complex dynamic systems, but their application to microscopic phenomena remains largely unexplored. Microscale simulation holds great promise for biomedical applications such as drug discovery, organ-on-chip systems, and disease mechanism studies, while also showing potential in education and interactive visualization. In this work, we introduce MicroWorldBench, a multi-level rubric-based benchmark for microscale simulation tasks. MicroWorldBench enables systematic, rubric-based evaluation through 459 unique expert-annotated criteria spanning multiple microscale simulation task (e.g., organ-level processes, cellular dynamics, and subcellular molecular interactions) and evaluation dimensions (e.g., scientific fidelity, visual quality, instruction following). MicroWorldBench reveals that current SOTA video generation models fail in microscale simulation, showing violations of physical laws, temporal inconsistency, and misalignment with expert criteria. To address these limitations, we construct MicroSim-10K, a high-quality, expert-verified simulation dataset. Leveraging this dataset, we train MicroVerse, a video generation model tailored for microscale simulation. MicroVerse can accurately reproduce complex microscale mechanism. Our work first introduce the concept of Micro-World Simulation and present a proof of concept, paving the way for applications in biology, education, and scientific visualization. Our work demonstrates the potential of educational microscale simulations of biological mechanisms. Our data and code are publicly available at https://github.com/FreedomIntelligence/MicroVerse
LiveClin: A Live Clinical Benchmark without Leakage
Feb 18, 2026The reliability of medical LLM evaluation is critically undermined by data contamination and knowledge obsolescence, leading to inflated scores on static benchmarks. To address these challenges, we introduce LiveClin, a live benchmark designed for approximating real-world clinical practice. Built from contemporary, peer-reviewed case reports and updated biannually, LiveClin ensures clinical currency and resists data contamination. Using a verified AI-human workflow involving 239 physicians, we transform authentic patient cases into complex, multimodal evaluation scenarios that span the entire clinical pathway. The benchmark currently comprises 1,407 case reports and 6,605 questions. Our evaluation of 26 models on LiveClin reveals the profound difficulty of these real-world scenarios, with the top-performing model achieving a Case Accuracy of just 35.7%. In benchmarking against human experts, Chief Physicians achieved the highest accuracy, followed closely by Attending Physicians, with both surpassing most models. LiveClin thus provides a continuously evolving, clinically grounded framework to guide the development of medical LLMs towards closing this gap and achieving greater reliability and real-world utility. Our data and code are publicly available at https://github.com/AQ-MedAI/LiveClin.
DentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
Dec 12, 2025Reliable interpretation of multimodal data in dentistry is essential for automated oral healthcare, yet current multimodal large language models (MLLMs) struggle to capture fine-grained dental visual details and lack sufficient reasoning ability for precise diagnosis. To address these limitations, we present DentalGPT, a specialized dental MLLM developed through high-quality domain knowledge injection and reinforcement learning. Specifically, the largest annotated multimodal dataset for dentistry to date was constructed by aggregating over 120k dental images paired with detailed descriptions that highlight diagnostically relevant visual features, making it the multimodal dataset with the most extensive collection of dental images to date. Training on this dataset significantly enhances the MLLM's visual understanding of dental conditions, while the subsequent reinforcement learning stage further strengthens its capability for multimodal complex reasoning. Comprehensive evaluations on intraoral and panoramic benchmarks, along with dental subsets of medical VQA benchmarks, show that DentalGPT achieves superior performance in disease classification and dental VQA tasks, outperforming many state-of-the-art MLLMs despite having only 7B parameters. These results demonstrate that high-quality dental data combined with staged adaptation provides an effective pathway for building capable and domain-specialized dental MLLMs.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025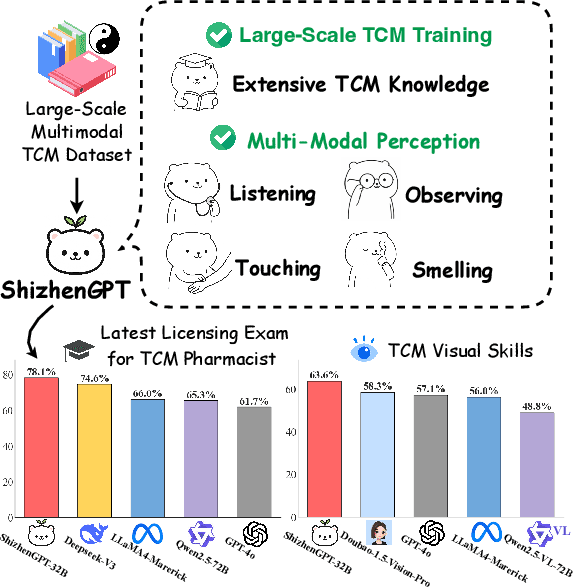
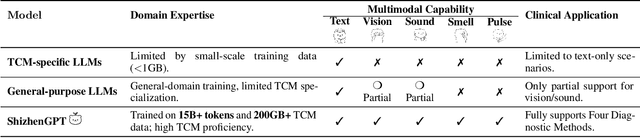
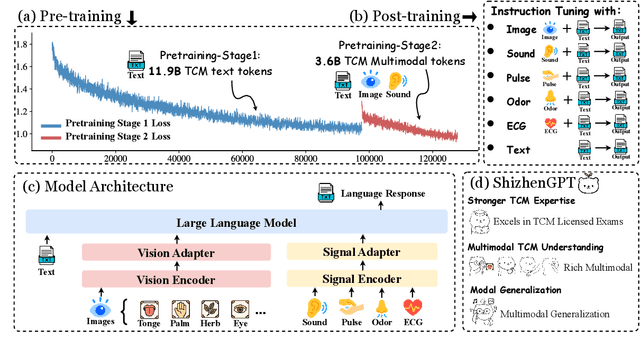
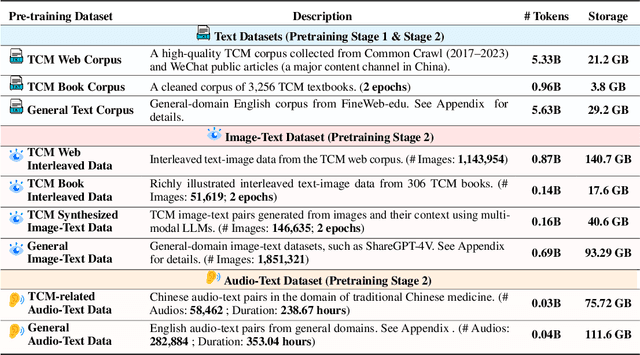
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
Large Language Models for Outpatient Referral: Problem Definition, Benchmarking and Challenges
Mar 11, 2025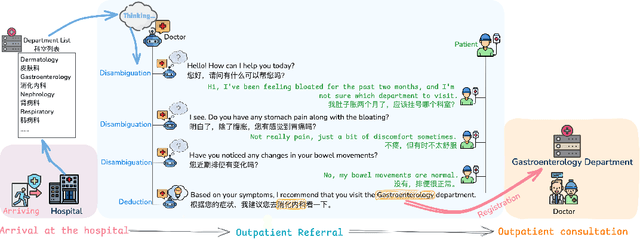
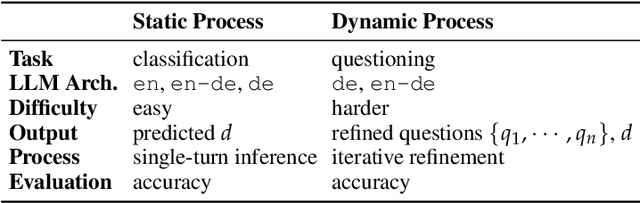
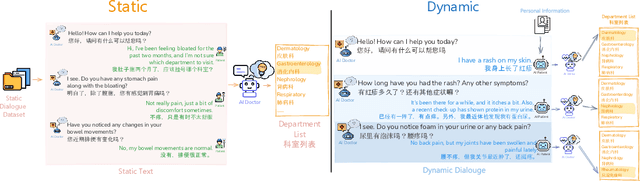
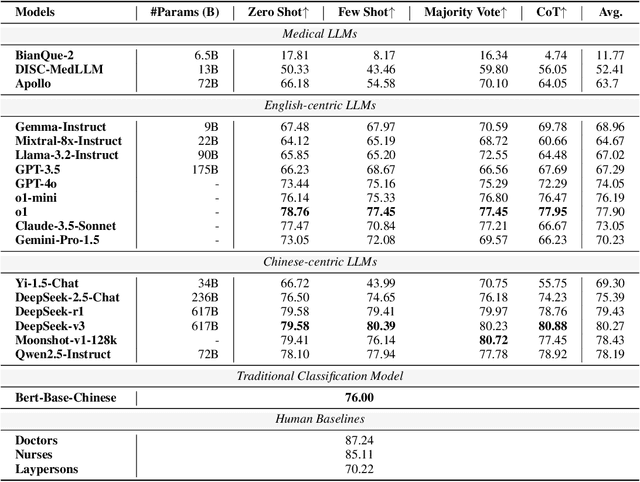
Large language models (LLMs) are increasingly applied to outpatient referral tasks across healthcare systems. However, there is a lack of standardized evaluation criteria to assess their effectiveness, particularly in dynamic, interactive scenarios. In this study, we systematically examine the capabilities and limitations of LLMs in managing tasks within Intelligent Outpatient Referral (IOR) systems and propose a comprehensive evaluation framework specifically designed for such systems. This framework comprises two core tasks: static evaluation, which focuses on evaluating the ability of predefined outpatient referrals, and dynamic evaluation, which evaluates capabilities of refining outpatient referral recommendations through iterative dialogues. Our findings suggest that LLMs offer limited advantages over BERT-like models, but show promise in asking effective questions during interactive dialogues.
The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models
Mar 04, 2025
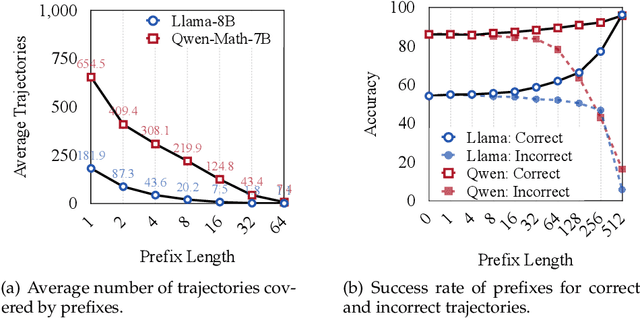
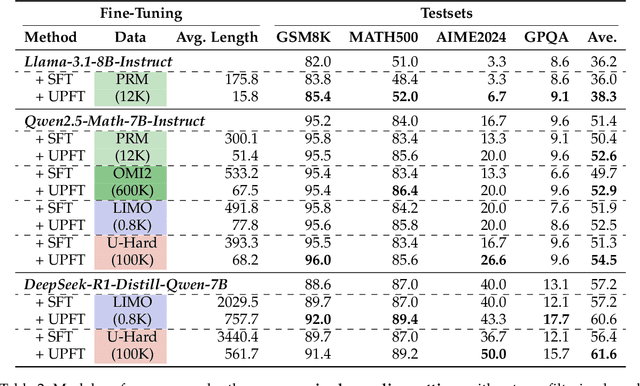

Improving the reasoning capabilities of large language models (LLMs) typically requires supervised fine-tuning with labeled data or computationally expensive sampling. We introduce Unsupervised Prefix Fine-Tuning (UPFT), which leverages the observation of Prefix Self-Consistency -- the shared initial reasoning steps across diverse solution trajectories -- to enhance LLM reasoning efficiency. By training exclusively on the initial prefix substrings (as few as 8 tokens), UPFT removes the need for labeled data or exhaustive sampling. Experiments on reasoning benchmarks show that UPFT matches the performance of supervised methods such as Rejection Sampling Fine-Tuning, while reducing training time by 75% and sampling cost by 99%. Further analysis reveals that errors tend to appear in later stages of the reasoning process and that prefix-based training preserves the model's structural knowledge. This work demonstrates how minimal unsupervised fine-tuning can unlock substantial reasoning gains in LLMs, offering a scalable and resource-efficient alternative to conventional approaches.
RAG-Instruct: Boosting LLMs with Diverse Retrieval-Augmented Instructions
Dec 31, 2024



Retrieval-Augmented Generation (RAG) has emerged as a key paradigm for enhancing large language models (LLMs) by incorporating external knowledge. However, current RAG methods face two limitations: (1) they only cover limited RAG scenarios. (2) They suffer from limited task diversity due to the lack of a general RAG dataset. To address these limitations, we propose RAG-Instruct, a general method for synthesizing diverse and high-quality RAG instruction data based on any source corpus. Our approach leverages (1) five RAG paradigms, which encompass diverse query-document relationships, and (2) instruction simulation, which enhances instruction diversity and quality by utilizing the strengths of existing instruction datasets. Using this method, we construct a 40K instruction dataset from Wikipedia, comprehensively covering diverse RAG scenarios and tasks. Experiments demonstrate that RAG-Instruct effectively enhances LLMs' RAG capabilities, achieving strong zero-shot performance and significantly outperforming various RAG baselines across a diverse set of tasks. RAG-Instruct is publicly available at https://github.com/FreedomIntelligence/RAG-Instruct.
On the Compositional Generalization of Multimodal LLMs for Medical Imaging
Dec 28, 2024



Multimodal large language models (MLLMs) hold significant potential in the medical field, but their capabilities are often limited by insufficient data in certain medical domains, highlighting the need for understanding what kinds of images can be used by MLLMs for generalization. Current research suggests that multi-task training outperforms single-task as different tasks can benefit each other, but they often overlook the internal relationships within these tasks, providing limited guidance on selecting datasets to enhance specific tasks. To analyze this phenomenon, we attempted to employ compositional generalization (CG)-the ability of models to understand novel combinations by recombining learned elements-as a guiding framework. Since medical images can be precisely defined by Modality, Anatomical area, and Task, naturally providing an environment for exploring CG. Therefore, we assembled 106 medical datasets to create Med-MAT for comprehensive experiments. The experiments confirmed that MLLMs can use CG to understand unseen medical images and identified CG as one of the main drivers of the generalization observed in multi-task training. Additionally, further studies demonstrated that CG effectively supports datasets with limited data and delivers consistent performance across different backbones, highlighting its versatility and broad applicability. Med-MAT is publicly available at https://github.com/FreedomIntelligence/Med-MAT.